Captions for video - Find and Replace across time stamps
-
@Alan-Kilborn’s is a good starting point. But in edge cases, it might not do what you want:
I am going to use your example to show a procedure for “how to search for a phrase when separated by multiple types of separator sequences”, and in so developing, hopefully give you (and other readers) a good way to think about such problems.
First, I start thinking about the simplest case: if I were searching for a phrase
like a fire, I would just type that into the search field, and as long as the phrase was all on one physical line, that would be sufficient.To move on to the next generalization (allowing multiline match), I am going to introduce a few important regex concepts (the links point to the section in the manual that describes that feature).
-
Instead of a space character, I will use
\x20(SPACE is ASCII 32, which is hex 0x20;\x20is the way our regex engine represents that arbitrary character). This will make it easier to use a space in the regex, especially if it needs to be at the beginning or end of the regex -
The control character sequence
\Rwill match any newline sequence (colloquially known as CR, LF, or CRLF). -
Using the search modifier syntax
(?x-s), I set two options in the regex: (1) this enables thexoption, which means if I have normal space characters, they will be ignored; this then requires using notation like\x20for a literal space… but it also makes it easier to see the regex; (2) the-sportion of the option means that the.sequence will not match newline sequences (the same as turning off. matches newline; Alan’s post enabled. matches newlineusing(?s)) -
If I want to “reuse” a regex to match something that meets the same sub-regex, I can use the subexpression control flow: so if I have a subexpression in parentheses earlier, I can reuse that same expression later using
(?ℕ), whereℕis the number of the subexpression. -
You can use
|inside an expression or subexpression to be the logical “OR”.
Back to the problem at hand. For the first generalization, I want to switch to using some of that notation, but still only using literal spaces as the separator between the words of a phrase:
(?x-s) like (\x20) a (?1) fire
This uses the option to allow extra spaces to make it more readable, uses the
\x20for the literal space, and the(?1)to refere to the regex – so anyplace I use(?1), it is exactly equivalent to(\x20). This expression still only matches the same as the original. A lot of extra work up front, but…Now we want to allow matching over multiple lines , so matching
like a fireor
like a fireTo do this, we want to match the space
\x20OR a newline sequence\R.(?x-s) like (\x20 | \R) a (?1) fire
Now the separator expression allows a space or a newline sequence, and the
(?1)is exactly equivalent to that. (At this point, some might have said “just use\sto match any horizontal or vertical whitespace”… but that won’t allow us to be as generic in the next step… and maybe you don’t want a TAB to be allowed between, only spaces or newlines)The next idea is to allow a timestamp line. You can specify the timestamp very loosely or very tightly, but I am going to say that a timestamp looks like zero or more newlines followed by one or two digits, followed by a colon, followed by anything else on the main timestamp line (including its newline). If you want to be more specific, you can add extra rules to it… making sure it only allows full timestamps with hms and/or the range of times, or whatever else distinguishes it from a similar line that shouldn’t be allowed. The expression
\R* \d{1,2} : .*\Rmatches those three requirements. Adding it into our full expression, we want to say “the separator can be a space, a newline, or a timestamp”:(?x-s) like (\x20 | \R | \R* \d{1,2} : .*\R) a (?1) fire
If you’ve got a phrase with more words, just stick another
(?1)between each word.Example data I used:
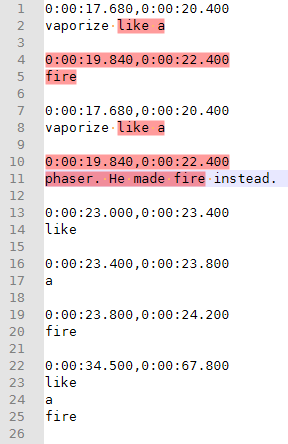
0:00:17.680,0:00:20.400 vaporize like a 0:00:19.840,0:00:22.400 fire 0:00:17.680,0:00:20.400 vaporize like a 0:00:19.840,0:00:22.400 phaser. He made fire instead. 0:00:23.000,0:00:23.400 like 0:00:23.400,0:00:23.800 a 0:00:23.800,0:00:24.200 fire 0:00:34.500,0:00:67.800 like a fireHopefully this helps with the immediate problem, and with being able to generalize it in the future (do similar searches, but with different separators, or more separators, or more restrictive on one of the rules, or what have you).
Good luck.
-—
Do you want regex search/replace help? Then please be patient and polite, show some effort, and be willing to learn; answer questions and requests for clarification that are made of you. All example text should be marked as literal text using the
</>toolbar button or manual Markdown syntax. To makeregex in red(and so they keep their special characters like *), use backticks, like`^.*?blah.*?\z`. Screenshots can be pasted from the clipboard to your post usingCtrl+Vto show graphical items, but any text should be included as literal text in your post so we can easily copy/paste your data. Show the data you have and the text you want to get from that data; include examples of things that should match and be transformed, and things that don’t match and should be left alone; show edge cases and make sure you examples are as varied as your real data. Show the regex you already tried, and why you thought it should work; tell us what’s wrong with what you do get. Read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. If you follow these guidelines, you’re much more likely to get helpful replies that solve your problem in the shortest number of tries. -
-
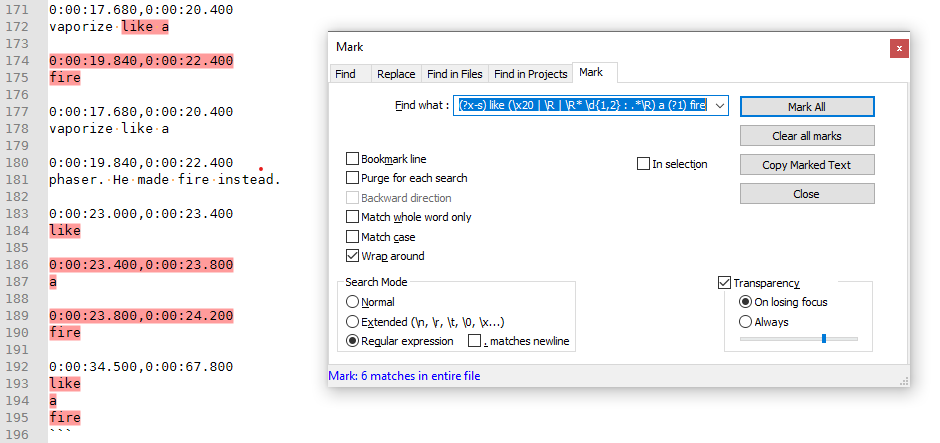
Sorry, I meant to include a screenshot of the last regex working on the example data.
-
@PeterJones Wow! Thank you so much for the detailed explanation. No wonder I couldn’t figure it out. You really know your stuff and are amazing! :-)
One follow-up question, Is there any way to adjust this to a find/replace that wouldn’t delete the time stamp across lines? So in the example.
0:00:17.680,0:00:20.400
vaporize like a0:00:19.840,0:00:22.400
fireAfter finding the “like a fire” across multiple lines the replace would blank out the end of the first line and change the second line fire to liquefy.
Desired result
0:00:17.680,0:00:20.400
vaporize0:00:19.840,0:00:22.400
liquefyThanks so much!
-
One solution could be as simple as adding a space before “like a” and grouping the second time stamp in @PeterJones’ regex. Also, in the replacement expression insert a reference to recently created group and the new string. As follows:
Search: (?x-s) \x20like (\x20 | \R | \R* \d{1,2} : .*\R) a ((?1)) fire Replace: $2liquefyHope this helps
-
I think what the OP is looking for here is basically a way to search for a phrase which could have a timestamp inserted into it at any word position in the phrase, i.e., it won’t occur that the timestamp is inserted into the middle of the word.
Then the OP wants the ability to replace with the same sort of criterion.
And it appears that the replacement can wholly occur after the timestamp (the portion of the search match before the timestamp is removed) and things still work.I think what might be best here is a script; the script would still use regular expressions, but it would allow the user to very naturally search for a simple phrase (user specifies “like a fire”) and replace it with a phrase (user specifies “liquify”) and the script takes care of the rest.
-
Hello, @MaximillianM, @peterjones, @alan-kilborn, @astrosofista and All,
Let’s expand the problem a bit and imagine this text :
0:00:17.680,0:00:20.400 The licenses for most software are designed to 0:00:19.840,0:00:22.400 take away your freedom to share and change it.And that the OP want to :
-
Find the string
designed to take away -
Replace it with the string
generally made to always suppress
Right now, the timestamp is located between the two strings
designed toandtake awayNow, let’s use the
|symbol to represent thetimestampfeatureWhich replacement is expected by @MaximillianM ?
designed to | take away => generally | made to always suppress ( Case A ) designed to | take away => generally made | to always suppress ( Case B ) designed to | take away => generally made to | always suppress ( Case C ) designed to | take away => generally made to always | suppress ( Case D )To my mind, the more logical one would be
Case B, as, before thetimestamp, there would be as many words after the replacement than before the replacement !…
Best Regards,
guy038
-
-
@guy038 said in Captions for video - Find and Replace across time stamps:
To my mind, the more logical one would be Case B
But we really don’t know what the OP’s needs in this regard are.
I mean, well, if you want to have fun, go off and solve any problem you’d like. :-)For me, I’ll wait to see if OP returns again, clarifies need, and expresses interest in the scripted solution.
The scripted solution I envision would prompt with an input box for the string to search for, then would prompt with an input box for the replacement. The script would run and use some variant of Peter’s solution behind the scenes.
-
Thank you all so much! You are Great! This really helps.
I tested replacing the text after the second timestamp using $2 which works. Also adding it after the second timestamp probably is the best default option. The only real “error” could be if the replacement made it so that one line of text was completely blank.
I hadn’t known about the script function and have just used recorded macros. Macros do work, but once created macros can be but are not that easy to edit.
Since you have been so helpful. I’ll outline the full desired outcome which might be a script.
1-Find and replace a list of words. Words might be added or removed to this list in the future. My current list is about 90 words.
Most are just simple words so a 1 to 1 on the same line works.
For example “cuz” replace with “because” or “um” replaced with a blank. Ideally, this list could be seen and editedWordToFind, Word to Replace
cuz, because
um, [blank]2-Then phrases that could go across lines. The regular expressions ones.
Could be in the same list/table as above with the full code or a different list/table.
WordToFind-----------Word to Replace
(?x-s) \x20like (\x20 | \R | \R* \d{1,2} : .*\R) a ((?1)) fire-----------------$2liquefyor since you really know your stuff. Maybe fancy and takes the phrase
“like a fire” and creates the code (?x-s) \x20like (\x20 | \R | \R* \d{1,2} : .*\R) a ((?1)) fireThanks again! You have really been helping me out :-)
-
@MaximillianM said in Captions for video - Find and Replace across time stamps:
“like a fire” and creates the code (?x-s) \x20like (\x20 | \R | \R* \d{1,2} : .*\R) a ((?1)) fire
Yes, something like that was what I had in mind.
Would your search “phrase” ever have TWO+ embedded timestamps in it? Or is that a case that we don’t need to consider…?
Let me absorb your specs and see if I can put together a reasonable demo.
-
@Alan-Kilborn Thanks! Across two timestamps is a possibility and would be great to consider for some potential longer phrases. You keep exceeding my expectations :-) Though if it is too complicated, across one is still really good.
-
So let’s start simple and slowly. :-)
Here’s a test PythonScript that can demo the functionality:
# -*- coding: utf-8 -*- from Npp import editor, notepad class T1(object): def __init__(self): search_phrase = 'like a fire' while True: search_phrase = notepad.prompt('\r\nEnter search phrase and press OK to find next:', '', search_phrase) if search_phrase == None or len(search_phrase) == 0: return # quit word_list = search_phrase.strip().split() regex = r'(?-is)(?(DEFINE)(\x20|\R|\R*\d{1,2}:.*\R))' + '(?1)'.join(word_list) matches = [] editor.research(regex, lambda m: matches.append(m.span(0)), 0, editor.getCurrentPos(), editor.getLength(), 1) if len(matches) == 0: notepad.messageBox('No (more) matches', '') return else: (match_start, match_end) = matches[0] editor.scrollRange(match_end, match_start) editor.setSelection(match_end, match_start) if __name__ == '__main__': T1()When you run it, it will prompt you for your search phrase, like this:

When you enter it and press OK, you will be shown your first match (it will become selected) and it will prompt again:

It will continue moving downward in a file, until no more matches occur or you press Cancel.
Peter has some good instructions for getting started with the PythonScript plugin HERE.
See if you can get what I’ve shown working for you, and then we’ll talk about where to take it from here. -
@Alan-Kilborn Thanks, yes, I was able to get it to work!
-
@Alan-Kilborn Hi Alan, Thanks for your help on this project can you point me in the right direction for the next step of adding code to use a preset list of words to find and replace? Thanks again :-)
-
@MaximillianM said in Captions for video - Find and Replace across time stamps:
use a preset list of words to find and replace
Sure; again let’s start small…
Let’s just put the list inside the code, but maybe make it look like it is coming from a file (because you may want to go there, later).
So I’d suggest a list like this:
::findable_you:replaceable_you :I can contain spaces:So I seewhere the format is:
- one-character delimiter
- find word/phrase
- delimiter (as previously defined by first character)
- replace word/phrase
In Python we might do it like this:
the_list = [ ':findable_you:replaceable_you', ':I can contain spaces:So I see', ':look_for_me:really_want_to_be_you', '!simple!complex', '$fire$liquify', ]We need some code to process that list:
# -*- coding: utf-8 -*- from Npp import editor class T2(object): def __init__(self): the_list = [ ':findable_you:replaceable_you', ':I can contain spaces:So I see', ':look_for_me:really_want_to_be_you', '!simple!complex', '$fire$liquify', ] editor.beginUndoAction() for definition in the_list: delim = definition[0] (find_what, repl_with) = definition[1:].split(delim, 2) editor.replace(find_what, repl_with) editor.endUndoAction() if __name__ == '__main__': T2() -
@Alan-Kilborn Thanks! Yes, I like the idea of making it a separate file for ease of updates.
I experimented with the code.
What is the difference between using the ! or $ for the word in the list? They seem to do a similar find/replace in the example, at least in my small test. But I’m probably missing something.
The next step seems to be adding the search over multiple lines code as from your earlier example. How can I do that?
Thanks!
-
@MaximillianM said in Captions for video - Find and Replace across time stamps:
What is the difference between using the ! or $ for the word in the list? They seem to do a similar find/replace in the example, at least in my small test. But I’m probably missing something.
So the “delimiter” variability is useful if the data itself contains the delimiter.
Say we hardcoded the delimiter to be a colon (
:).
Then if you wanted to replace something likea:bwithc:dit would be difficult.The way I defined it, you could just use a different delimiter for this case, e.g.
!a:b!c:d. -
@MaximillianM said in Captions for video - Find and Replace across time stamps:
The next step seems to be adding the search over multiple lines code as from your earlier example. How can I do that?
This is the point where I’m having trouble envisioning how it would work.
I know you said something about it before, but I didn’t quite understand it.Would you put a special symbol in the replacement part that you’d want the timestamp to be replaced by?
Maybe a more in-depth walk-through (example(s)) of what is wanted?I’m certainly willing to do it, or at least help you get started…
-
@Alan-Kilborn Thanks again. I see you are helping many other people so I should have put a summary in to help you :-)
The problem
1-Simple Find and replace with a list of words (your most recent code does this)
2-Find and replace multi-word string that goes across a timestamp
Find “like a fire” replace with $2liquefy0:00:17.680,0:00:20.400
vaporize like a0:00:19.840,0:00:22.400
fireI would like to combine the most recent code with this one (minus the manual entry box so it could use the list as in your most recent code) to search across the time stamp.
-- coding: utf-8 --
from Npp import editor, notepad
class T1(object):
def __init__(self): search_phrase = 'like a fire' while True: search_phrase = notepad.prompt('\r\nEnter search phrase and press OK to find next:', '', search_phrase) if search_phrase == None or len(search_phrase) == 0: return # quit word_list = search_phrase.strip().split() regex = r'(?-is)(?(DEFINE)(\x20|\R|\R*\d{1,2}:.*\R))' + '(?1)'.join(word_list) matches = [] editor.research(regex, lambda m: matches.append(m.span(0)), 0, editor.getCurrentPos(), editor.getLength(), 1) if len(matches) == 0: notepad.messageBox('No (more) matches', '') return else: (match_start, match_end) = matches[0] editor.scrollRange(match_end, match_start) editor.setSelection(match_end, match_start)if name == ‘main’: T1()
Thanks again :-)
-
@MaximillianM said in Captions for video - Find and Replace across time stamps:
Find “like a fire” replace with $2liquefy
0:00:17.680,0:00:20.400
vaporize like a
0:00:19.840,0:00:22.400
fireYes, you used this example before, but I didn’t fully understand it.
I take it the$2represents the bridged timestamp, and where it would appear in the replacement text.BTW, why
$2?
Is it because a search match could possibly bridge two timestamps?
And$1might possibly appear in the replace expression as well?
Or$3etc? -
@Alan-Kilborn Hi, I’m a beginner and was just using the $2 that astrosofista suggested in this post so I don’t fully understand it.
He suggested
Search: (?x-s) \x20like (\x20 | \R | \R* \d{1,2} : .*\R) a ((?1)) fire
Replace: $2liquefyIf I don’t use the $2 before the replacement word then the timestamp is removed in the replacement. I tried $1 and $3 before the replacement word as a test and the time stamp was removed in both cases.
Putting the replacement expression in the second part of the string (second timestamp) is preferable as it is the most likely scenario.
Just one bridged time-stamp is the basic requirement, in the future I might look at across multiple time-stamps.
There a blank line between the timestamp/phrase as in the example below.
$1, $2, $3, would not be present in the text so ok to use in our expression.Find “like a fire” replace (end of expression) with liquefy
0:00:17.680,0:00:20.400
vaporize like a0:00:19.840,0:00:22.400
fire0:00:22.400,0:00:24.300
next phraseThanks :-)
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login