How to find and replace unrecognizable characters in multiple files of a folder with the correct character using Notepad ++?
-
@Ramanand-Jhingade said in How to find and replace unrecognizable characters in multiple files of a folder with the correct character using Notepad ++?:
@PeterJones How do I do
Encoding > Convert to UTF-8-BOMYou look on the Notepad++ menu, where it has the word “Encoding” as a menu entry; you click on it. Then you go to the menu entry called “Convert to UTF-8-BOM” and click on it.
? Will that cause any problems for the images, alphabets or numerals on any of the webpages
“Images”, no. Your image data isn’t in the HTML source file. If you don’t know that, you probably have some studying of web technology to do.
“Alphabets or numerals”: I don’t know what’s in your page. That’s up to you to know. I already gave the caveat “if you know there aren’t any other UTF8 characters in the file” before following that procedure.
(the webpages are with .html extensions but I edit them with Notepad++)?
Yes, that’s the way that web source files work: you use a text editor to edit the plain text HTML source. If you think you have to clarify that statement because it’s not intuitively obvious to you, then you probably have some studying of web technology to do.
-
@Ramanand-Jhingade
and in addition to what has already been said, you can take a look here to get a better understanding about ansi, unicode and their friends. -
@PeterJones I did what you said and then tried to replace the unrecognizable characters with the codes you typed above but it still says,
Can’t find the text "\x93" -
@Ramanand-Jhingade said in How to find and replace unrecognizable characters in multiple files of a folder with the correct character using Notepad ++?:
I did what you said and then tried to replace the unrecognizable characters with the codes you typed above but it still says,
Can you show screenshots of your steps, similar to what I did above, or my example below? All you have to do is hit Alt+PrintScreen inside Notepad++ (or use the windows Snipping Tool with Shift+WindowsKey+S and then draw a box around the area of screen you want to snip) then paste into your reply here.
It would be nice if you showed enough of your window so we could see the x93 characters and what they become at each step, and also see the full status bar along the bottom.
For example:
-
see that it’s UTF-8-BOM right now, so it doesn’t know what to do with the x91 and similar invalid UTF8 characters
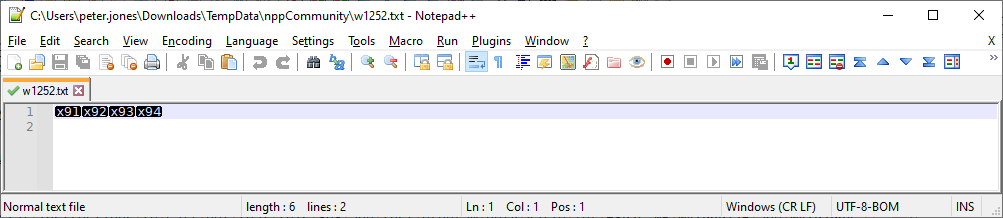
notice how they look like x91 right now -
use the menus to set Encoding > ANSI
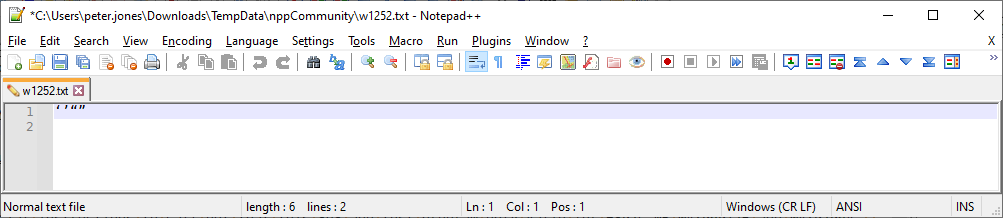
notice how they look like smart quotes now? That’s because they are. And Notepad++ knows this. -
At this point, a search should work. But you don’t need to search and replace, because notepad++ recognizes the characters at this point. There is nothing to search and replace, because the characters are right.
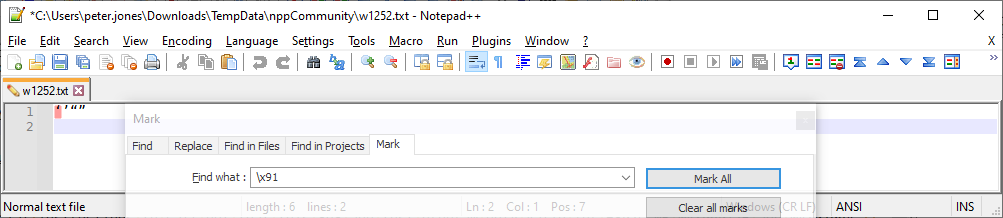
-
menu Encoding > Convert to UTF-8 or Convert to UTF-8-BOM. Now this will put the file into a valid UTF-8 byte sequence.
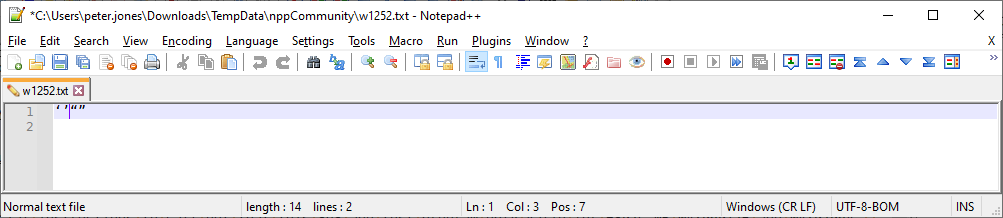
Notice also that the length changed on the status bar: that’s because in UTF-8, the smart quotes each take up 3 bytes, plus 2 bytes for the newline sequence at the end (3*4+2 = 14) -
if everything looks right to you, Save
Note that step 3 is only needed if your webserver is expecting the file to be in UTF-8 (or is otherwise telling the outside world that it is UTF-8). It might be that if you’re looking at a local file in your local browser (no webserver involved) it assumes UTF-8. Or maybe it assumes something different. I cannot tell you, because I have no insight into your webserver or your local computer.
-----
Note: you are responsible for your own data. I am assuming you have backed up any critical data. I am not liable for any data loss that you might incur while correctly or incorrectly following my advice. -
-
@PeterJones I am not lying but I will do what you typed above and send screenshots when I can make some time. Please think of a solution meanwhile. Thanks for your time and help.
-
@PeterJones Showing you screenshots:


The encoding is already UTF 8, so how to find and replace the unrecognized characters? -
@PeterJones I found a method to find all non-ascii characters from multiple files of a folder here: notepad-tip-find-out-non-ascii
I think I should check all that individually but if you know a less time consuming method, please let me know! I observed that at most places, they are showing up as they should, it is only in some places that a unicode is shown (probably a bug) -
@PeterJones @guy038 Is there a way to find invalid characters using the information here: how-to-change-all-invalid-characters-to-spaces ?
-
@Ramanand-Jhingade said in How to find and replace unrecognizable characters in multiple files of a folder with the correct character using Notepad ++?:
[posted screenshots]
Thank you for doing screenshots. Unfortunately, you didn’t pay attention to my request or look at my example screenshots, because your screenshots did not show the Notepad++ status bar at the bottom of the window, so there was no proof of the encoding. I will just have to take your word for “the encoding is already UTF 8”, whereas if you had done what I asked, it would have been included in the screenshots, so I could be sure. Further, you didn’t understand that my request wanted you to show a screenshot at each of the four steps of the procedure I gave you, just like my example gave four screenshots, one at each of the four steps.
The encoding is already UTF 8, so how to find and replace the unrecognized characters?
You appear to be not understanding my posts and screenshots.
Did you notice in my #1 screenshot above, shown again here:

… that the “encoding is already UTF 8” – you can see this in the lower-right corner, in the Notepad++ status bar; that’s the reason I included the status bar in my screenshot, and why I asked you to include the status bar in your screenshot.
The fact that the “encoding is already UTF 8” was the whole point of what I was trying to show you: Notepad++ thinks the encoding is UTF-8, but it has run across the x91x92x93x94 bytes which are not valid UTF 8 encoded characters – so you have badly-formed UTF-8.
You also linked to,
notepad-tip-find-out-non-ascii : https://www.datagenx.net/2015/12/notepad-tip-find-out-non-ascii.html
which suggests that you use
[^\x00-\x7F]+. That would work, if you were in ANSI or one of the character-set encodings. But if your file is interpreted as UTF-8, then search will not find any such codepoints, because the bytes x93 and x94 are not properly encoded characters, so the search function does not always find them. See this example:
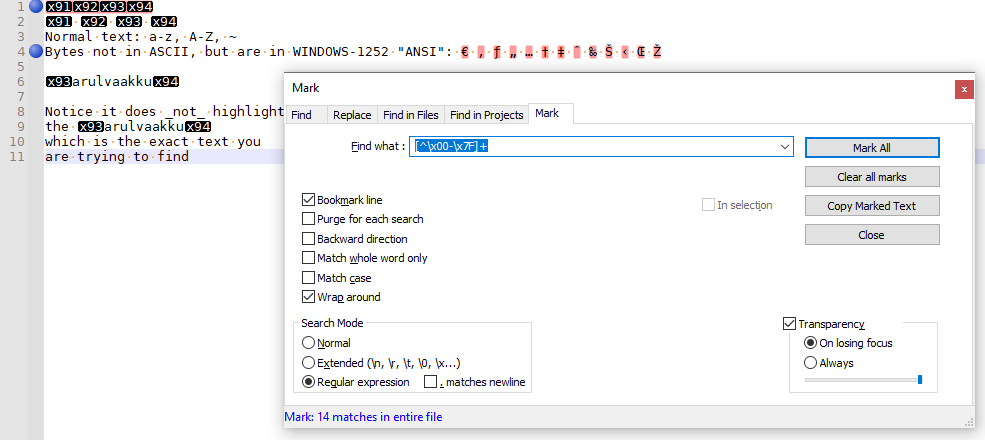
Notice how the only two lines bookmarked are the first (where the bytes run into each other, so that the high bytes at least match the UTF-8 requirement of having multiple 0x80-0xFF bytes adjacent to each other, rather than with non-high-bit characters like a space between) and the fourth (where there are other non-ASCII but validly-encoded UTF-8 characters); it does not match line 2 (where the bytes are space separated).Trying to find a search in Notepad++ to find invalidly-encoded characters is hard, because the Notepad++ search function assumes your data is properly encoded in whatever encoding Notepad++ is currently set to.
However, I did some more experimenting, and found a procedure that should work without ruining other UTF-8 text, and just fix the poorly-encoded smart quotes.
-
Verify that the status bar and/or Notepad++ Encoding menu currently is selected on UTF-8 or UTF-8-BOM
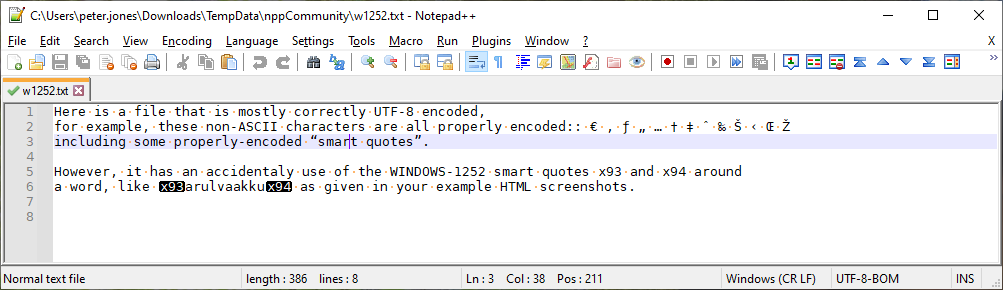
-
Use Encoding > ANSI to convince Notepad++ that your bytes are ANSI, not UTF-8.
- Before:
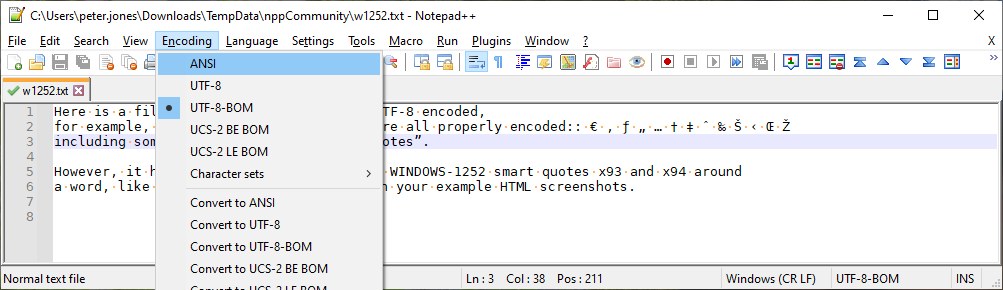
- After:
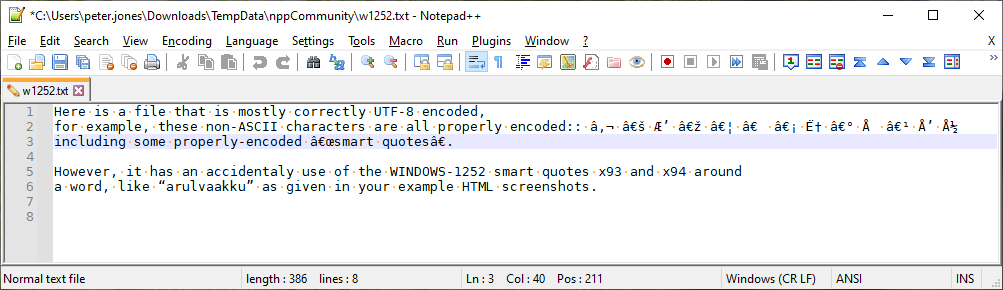
- You will notice that the “good” characters currently “look” wrong. Don’t worry about that for now. Trust me. But now
“arulvaakku”looks right
_WARNING: If you are not showing as “ANSI” encoding before starting step 3, you have not followed my instructions and this will not work! Step 2 will get you to the right point, but only if you have followed by instructions.
- Before:
-
Do a couple of search/replace. These four will change all single and double smart quotes into the correct three-byte sequence. (use regular expression search mode for all search/replace below)
- search
\x91replace\xE2\x80\x98 - search
\x92replace\xE2\x80\x99 - search
\x93replace\xE2\x80\x9C - search
\x94replace\xE2\x80\x9D
At this point, it will look “worse”, but that’s okay. Trust me.
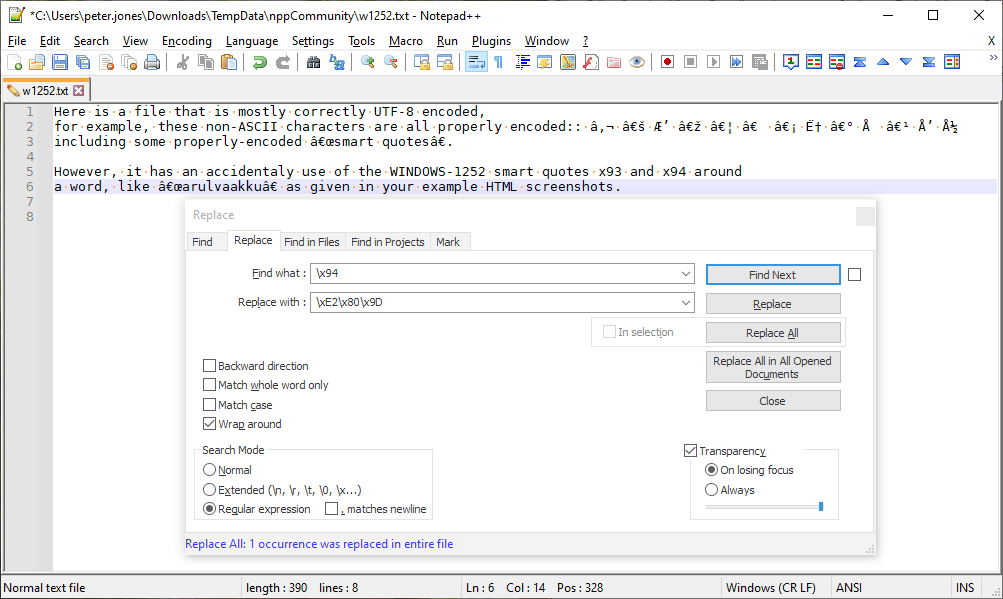
- search
-
Use the Encoding > UTF-8 to tell Notepad++ to re-interpret the file as if the bytes were UTF-8, which is what you want. At this point, everything looks good:
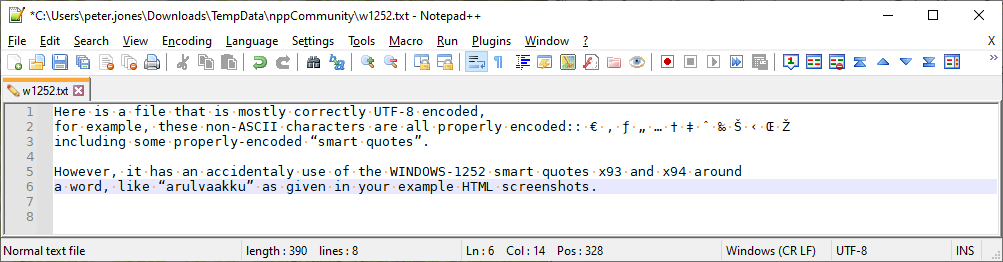
-
SAVE
I think I should check all that individually but if you know a less time consuming method, please let me know! I observed that at most places, they are showing up as they should, it is only in some places that a unicode is shown (probably a bug)
My method won’t be great if you have a lot of files. If there is a bug, it’s a bug in how your HTML was generated.
Alternatives
If the only non-ASCII characters in your entire file are the x93 and x94 smart quotes, then just ignore how it “looks” in notepad++, and tell your webserver that the file is encoded as Windows-1252 (using both server settings and maybe a meta-charset HTML tag
If the only non-ASCII characters in your entire file are x93 and x94 smart quotes, then try to convince Notepad++ to automatically interpret it as ANSI. Some things to try to get that result
-
Settings > Preferences > New Document:
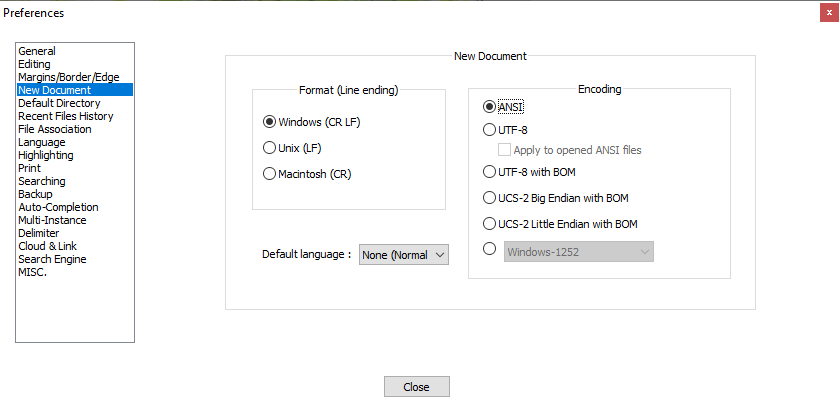
- Set “Encoding” to either “ANSI” or “Windows-1252”
- Make sure “Apply to opened ANSI files” is not checked
-
Settings > Preferences > MISC
- Try changing the setting of “Autodetect character encoding” to either checked or not.
After changing any of those settings, you may have to reload your file to get Notepad++ to apply its new settings. I do not guarantee that these settings will work for you… the auto-detect is notorious for disagreeing with the user as to what encoding it thinks is there, and everyone has different ideas of the “right” settings, depending on what their text normally looks like, and what bytes they contain.
- After loading a file, if Notepad++ doesn’t get it right, and you see the x93 and x94 boxes, just switch to Encoding > ANSI and everything will look right. On that file, you’d definitely want to include the meta-charset tag
Non-Notepad++ Alternative
If you have lots of files that have mixed encoding with some normal UTF-8 characters and some windows-1252 smart quotes, it might not be efficient to make the changes in Notepad++. Instead, you might want to find a non-Notepad++ solution. I would suggest trying command line tools, maybe like “iconv” or “sed” – there are windows versions of those tools, but this forum is not the right place to find help on those.
Done
I have explained these to the best of my ability. I am not confident that you have understood the points I have been making, or my instructions for how to fix your data. Unfortunately, I don’t know how else to say it. If you have more questions, feel free to ask; but I am going to likely leave it up to someone different to step in and try to help you, because I don’t know what more I could say that I haven’t already said.
-
-
If you end up going down the route of non-Notepad++ solutions (remembering that here is not the right place to ask questions if you do), @Vasile-Caraus has posted a couple of non-Notepad++ tools that might be able to do the search-and-replace in the way that you want, the tools listed in these two posts. The second tool which he mentioned, grepWin, has been recommended by other users on the forum as well, especially in circumstances when Notepad++'s find-in-files wasn’t properly handling encoding-detection.
Vasile showed it working for the bytes
�(which is the UTF-encoding for�) because that was the focus of that previous discussion. But it will likely also work if you wanted to replace\x93with“and\x94with”– and might be easier for you to figure out than iconv or command-line grep.Given your requirements, grepWin may be the best tool for you for this particular smart-quote problem. (if you have grepWin questions, you will need to find a grepWin forum or other generic help site, because the Notepad++ Community is focused on Notepad++)
-
@PeterJones I finally found a solution here: how-to-find-non-ascii-unprintable-characters-using-notepad-plus-plus
We have to select the Regular expression mode and search/find with this code: [\x00-\x08\x0B\x0C\x0E-\x1F\x7F-\x9F]
I will do the replacements one by one instead of using “Replace all” -
Find Allis making Notepad++ to stop working and close if I use the above code. Any suggestions to avoid that?
-
Find All is making Notepad++ to stop working and close if I use the above code.
Which Find All do you mean? Do you mean the Find > Find All in Current Document, Find > Find All in Opened Documents, or Find in Files > Find All ?
Please note that the Find in Files adds another level of confusion, because Notepad++ is trying to figure out the encoding on each file individually, and depending on the bytes in the file and your settings (as described above), it might think some are UTF-8 and others are ANSI or might pick a strange character-set value. The Find in Files isn’t great with non-ASCII characters, unfortunately. There are bug reports / feature requests, but they are taking time to get worked out.
I suggest doing one file at a time for now.
-
@PeterJones @Ekopalypse Thank you both for your time and help. @PeterJones Please post here if the bug is fixed and I can Find all/search in multiple files of a folder
-
Please post here if the bug is fixed and I can Find all/search in multiple files of a folder
Don’t misunderstand. Find in Files > Find All works for ASCII characters. And it works with valid characters in well-defined encodings (so a UTF-8-BOM or UCS-2-LE BOM file should properly search-and-replace with any valid character). It’s just when you’re making Notepad++ guess the encoding (one of the many character-set “encodings”) or when there are invalid characters (byte x93 all alone rather than in the appropriate mutli-byte sequence in a UTF-8 file). So, for your unusual use-case, it’s not currently working; but usually, it does.
-
@PeterJones By God’s grace, the Find all/search in multiple files of a folder using the Regular expression mode finally worked after I removed all the files that did not end with the
.htmlextension. I thank you again from the bottom of my heart!
-
(This post was in progress before your questions about Find All… I came back to this post later, so that future readers of the thread will know which character matches which.)
@Ramanand-Jhingade wrote:
I finally found a solution here: how-to-find-non-ascii-unprintable-characters-using-notepad-plus-plus
We have to select the Regular expression mode and search/find with this code:[\x00-\x08\x0B\x0C\x0E-\x1F\x7F-\x9F]Good job! I applaud your persistence.
However, the solution surprises me.
It didn’t make sense to me that
\x93wouldn’t find“but that[\x00-\x08\x0B\x0C\x0E-\x1F\x7F-\x9F]would. In an ANSI-encoded file, that search makes perfect sense, because those bytes aren’t in ASCII or extended-ASCII. But in a UTF-encoded file, those bytes aren’t valid unless they are part of a multi-byte UTF-8 encoding sequence.So I started cutting parts out of that expression until I narrowed it down to what’s matching:
\x13matched thex93byte.With a UTF-8 encoded file that has bad bytes with the MSB set that don’t get interpreted as part of a multi-byte UTF-8 character sequence, the following appears true:
\x13will match the
\x14will match the
For example:
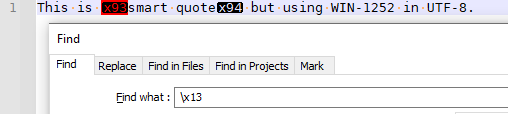
So I built up a test file , and started doing searches:
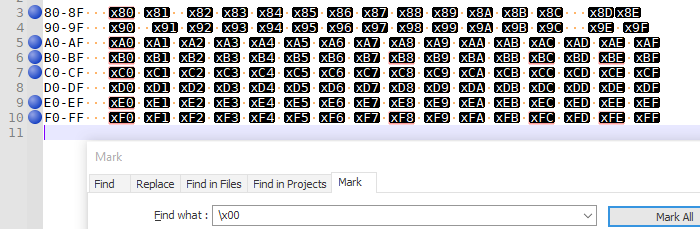
- searching
\x00matches many, including x80, xA0, xB0, xB8, xBC, xBE, xC0, xE0, xF0, xF8, xFC, xFE - searching
\x01matches eight, including x81, xA1, xB1, xB9, xBD, xC1, xE1, xF1, xF9, xFD - searching
\x02matches eight, including x82, xA2, xB2, xBA, xC2, xE2, xF2, xFA - searching
\x03matches eight, including x83, xA3, xB3, xBB, xC3, xE3, xF3, xFB - searching
\x04matches six, including x84, xA4, xB4, xC4, xE4, xF4 - searching
\x05,\x06, and\x07each match the seven in the same pattern as\x04 - searching
\x08only matches four, including x88, xA8, xC8, xF8 .\x09works analogously - searching
\x0Amatches that same pattern of four, but also matches all the line-feed character in the EOL sequences - searching
\x0Band\x0Ceach match four, including x8B, xAB, xCB, xFB, x8C, xAC, xCC, xFC, - searching
\x0Dmatches the pattern of four, and all the carriage returns in the EOL sequences - searching
\x0Ematches the pattern of four: x8E, xAE, xCE, xEE - searching
\x0Fmatches three of the four (but my file didn’t have x8F to match against) - searching
\x10matches two: x90 and xD0.\x11,\x12,\x13,\x14,\x15,\x16,\x17,\x18,\x19,\x1A,\x1B,\x1C,\x1D,\x1E,\x1Fall match the two entries from the 90 and D0 rows.
And no, @Alan-Kilborn , to answer your chat question, it does not change behavior inside of the
[]character class.As near as I can tell, in this poorly-encoded situation, the search engine seems to be applying certain bit-masks when searching for invalid bytes, where it masks out some of the upper bits while looking for matches. (My guess is that the multiple matches for a given search escape has to do with the fact that in valid UTF-8, 8-bit sequences that are
10xxxxxxcan only be the second, third, or fourth byte of the multibyute sequence (so that’s 0x80-0xBF);110xxxxxis the start of a 2-byte sequence (0xC0-0xDF);1110xxxxis the start of a 3-byte sequence (0xE0-0xEF); and1111xxxxis the start of a 4-byte sequence (0xF0-0xFF). But that’s a wild guess.)Remember, all of these were for my experiments, with a file that Notepad++ is interpreting as UTF-8, but have these badly-encoded single bytes with spaces in between. This isn’t a general search technique in a well-formed file with the right encoding selected. None of this is best-practice, but is only here to help correct mal-formed UTF-8 files.
-
Hello, @ramanand-jhingade, @peterjones, @ekopalypse, @alan-kilborn and All,
Many thanks for your insight about invalid bytes in
UTF8encoded files. Very strange indeed !So, in summary, if we use the non-regex notation
x[U][V]to represent the invalid characterxUV:- The regex \x00 matches the INVALID bytes x[8ABCEF][0] and x[BF][8CE] - The regex \x01 matches the INVALID bytes x[8ABCEF][1] and x[BF][9D] - The regex \x02 matches the INVALID bytes x[8ABCEF][2] and x[BF][A] - The regex \x03 matches the INVALID bytes x[8ABCEF][3] and x[BF][B] and \x[B][F] - The regex \x0[4-7] matches the INVALID bytes x[8ABCEF][4-7] - The regex \x0[8-F] matches the INVALID bytes x[8ACE][8-F] - The regex \x1[0-F] matches the INVALID bytes x[9D][0-F]I tried to find out a general rule explaining these results… without success :-(
Note that the invalid byte
xFF, in anUTF-8encoded file, cannot be find with the notation\x[01][0-F]
Now, I think that @ramanand-jhingade could also find and replace the
x93arulvaakkux94string with the following regex S/R :SEARCH
[[:cntrl:]]arulvaakku[[:cntrl:]]REPLACE
"arulvaakku"Note that, again, the Posix class
[[:cntrl:]]is not able to match the invalidUTF-8bytexFF!
As a remainder, here is, in a picture, some pieces of information about the
UTF-8encoding :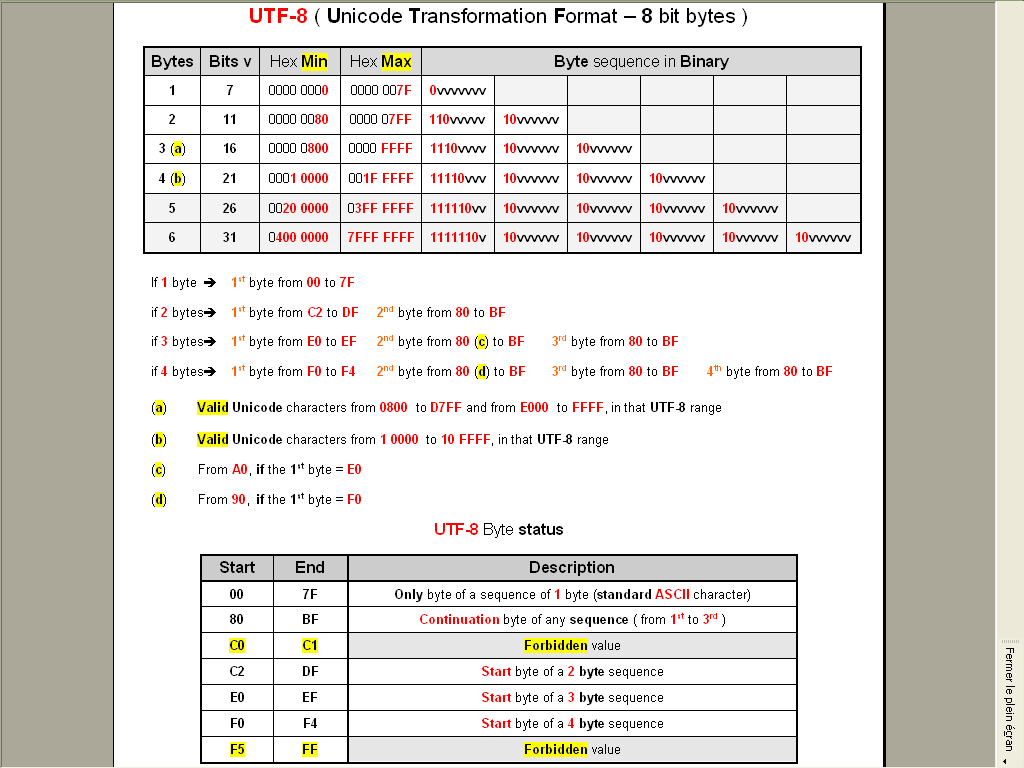
Best Regards
guy038
-
@guy038 said in How to find and replace unrecognizable characters in multiple files of a folder with the correct character using Notepad ++?:
here is, in a picture, some pieces of information about the UTF-8 encoding
That’s a nice reference. Where is it from?
I’ve just been using Wikipedia’s similar pictorial reference --> HERE.
-
Hi, @alan-kilborn and All,
No, just a personal presentation, in a
Worddocument, of some parts of this article that I made some years ago, to fully understand theUTF-8encoding ;-))My first table is simply the extension to the complete
UTF-8encoding of the Unicode table, seen here, which is able to encode all theUnicodecharacters (1,114,112)With the complete
UTF-8encoding, up to six bytes, it can represent up to134,217,728characters ( so fromU+0toU+7FFFFFF)As you can see, no problem for
UTF-8to encode all characters used in the different inhabited worlds of the galaxy !!!
And my second table is simply an other presentation of this one, on Wikipedia
BR
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login