How can I get autocomplete to be sorted by frequency of repetition instead of alphabetically?
-
@PeterJones The brief list could be a bit more visually appealing, so thanks for the suggestion.
I doubt that the feature would be implemented since Notepad++ is primarily a code editor and not a “text” editor.
Do you know any text editor that has this feature? I though I would experiment with Vim or Emacs, but the learning curve is quite steep. -
Perhaps something could be “scripted” for this desire?
I don’t like Notepad++'s auto-completion feature myself, so I don’t use it. And thus I’m not versed in how it could be scripted, nor would I have interest in writing/using such a script.
But it seems like some others have recently produced scripts that manipulate auto-completion, so maybe they would be interested in this opportunity to show off some script-brilliance?
-
@Alan-Kilborn I have no experience with C++, but I found a way to create a “plugin” using python. I may look into creating one in the near future.
-
@asadMarmash said in How can I get autocomplete to be sorted by frequency of repetition instead of alphabetically?:
@Alan-Kilborn I have no experience with C++, but I found a way to create a “plugin” using python. I may look into creating one in the near future.
Indeed.
For some examples that will give you ideas:
- this discussion led to @Mark-Olson creating a script for PythonScript that uses the dictionary from the DSpellCheck plugin for populating the auto-complete (it thus shows how to do a custom auto-complete, which will be helpful to you)
- you can search the forum for “frequency” or maybe better “pythonscript frequency”, and may find scripts that help with finding the frequency of words in your document.
-
@PeterJones
Here’s a simple way to sort autocompletions by frequency.Fair warning: this script engages in some heavy computation every time a char is added, and the amount of computation and memory consumption scales with the size of the file. Since this is Python and not C++, you shouldn’t be surprised if it’s quite a bit slower than normal autocompletion, and it’s probably unusable for files over a kilobytes.
There is definitely room for efficiency gains. I wrote this using a very simple, obvious algorithm because I didn’t want to fuss. I can try to implement this more efficiently within my dictionary autocompletion plugin, but it’s a nontrivial task.
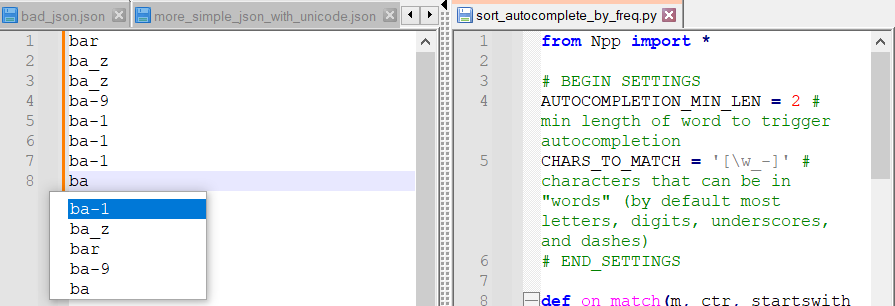
from Npp import * # BEGIN SETTINGS AUTOCOMPLETION_MIN_LEN = 2 # min length of word to trigger autocompletion CHARS_TO_MATCH = r'[\w_-]' # characters that can be in "words" (by default most letters, digits, underscores, and dashes) # END_SETTINGS def on_match(m, ctr, startswith): word = m.group(0) if not word.startswith(startswith): return ctr.setdefault(word, 0) ctr[word] += 1 def getWordRangeUnderCaret(): pos = editor.getCurrentPos() word_start_pos = editor.wordStartPosition(pos, True) word_end_pos = editor.wordEndPosition(pos, True) return word_start_pos, word_end_pos def onCharInsert(notif): word_start_pos, word_end_pos = getWordRangeUnderCaret() word_length = word_end_pos - word_start_pos word = editor.getRangePointer(word_start_pos, word_length).strip() if word_length < AUTOCOMPLETION_MIN_LEN: return ctr = {} editor.research('(%s+)' % CHARS_TO_MATCH, lambda m: on_match(m, ctr, word)) autocomp = sorted(ctr, key = lambda x: ctr[x], reverse=True) autocomp_str = ' '.join(autocomp) editor.autoCShow(word_length, autocomp_str) if __name__ == '__main__': try: CALLBACK_ADDED except NameError: CALLBACK_ADDED = 1 editor.callback(onCharInsert, [SCINTILLANOTIFICATION.CHARADDED])Edits after initial post:
- Add setting to customize what are considered word chars
- Get rid of f-string syntax in onCharInsert function to make it (hopefully) compatible with the Python2 version of PythonScript.
-
This new version now may ignore case for autocompletions depending on the lexer language setting (e.g., will ignore case for SQL but not Python)
I would not particularly recommend this version because it may ignore case in some situations where I think it’s rather inappropriate (e.g., text documents) and because of how the algorithm works, the autocompletions it produces are always in all caps. The version in my previous post may be more intuitive and useful.
from Npp import * # BEGIN SETTINGS AUTOCOMPLETION_MIN_LEN = 2 # min length of word to trigger autocompletion CHARS_TO_MATCH = r'[\w_-]' # characters that can be in "words" (by default most letters, digits, underscores, and dashes) USE_LANGUAGE_IGNORECASE = True # use the document's lexer language setting for ignoring case # END_SETTINGS def on_match(m, ctr, ignorecase): '''increase the count of the current word by 1 if ignorecase, store only the uppercase version of each word''' word = m.group(0) if ignorecase: word = word.upper() ctr.setdefault(word, 0) ctr[word] += 1 def getWordRangeUnderCaret(): '''get the start and end of the word under the caret''' pos = editor.getCurrentPos() word_start_pos = editor.wordStartPosition(pos, True) word_end_pos = editor.wordEndPosition(pos, True) return word_start_pos, word_end_pos def onCharInsert(notif): '''Find all words in the document prefixed by the word under the caret and show those words for autocompletion sorted by their frequency. Ignore words with length less than AUTOCOMPLETION_MIN_LEN. May ignore the case of words based on the lexer language (e.g., will ignore case in SQL but not in Python)''' word_start_pos, word_end_pos = getWordRangeUnderCaret() word_length = word_end_pos - word_start_pos word = editor.getRangePointer(word_start_pos, word_length).strip() if word_length < AUTOCOMPLETION_MIN_LEN: return ctr = {} # anything preceded by a non-word-char and starting with the current word match_pat = '(?<!{0}){1}({0}+)'.format(CHARS_TO_MATCH, word) ignorecase = USE_LANGUAGE_IGNORECASE and editor.autoCGetIgnoreCase() if ignorecase: # match case-insenstively if that's the language default match_pat = '(?i)' + match_pat editor.research(match_pat, lambda m: on_match(m, ctr, ignorecase)) autocomp = sorted(ctr, key = lambda x: ctr[x], reverse=True) autocomp_str = ' '.join(autocomp) editor.autoCShow(word_length, autocomp_str) if __name__ == '__main__': try: CALLBACK_ADDED except NameError: CALLBACK_ADDED = 1 editor.callback(onCharInsert, [SCINTILLANOTIFICATION.CHARADDED])Edit: added a setting to choose whether to use lexer language to decide whether to ignore case
-
One thing I should note about my scripts that I don’t think anyone has mentioned: there is no way to intercept Scintilla’s default autocompletion list (which includes language keywords) between when it is generated and when it is shown to the user. Thus, my script overrides the default autocompletions and I have no (easy) way to avoid this.
The upshot of this would seem to be (if I read the relevant docs correctly) that this is more of a job for the Scintilla devs than the Notepad++ devs.
-
OK, (probably) final update to my little script.
Since programmers don’t want their default autocompletions to be overriden for programming languages, and I’m concerned about it being a bit too CPU-hungry for very large files, I’ve added two new settings so that it doesn’t work on very big files and it only autocompletes for files with extensions from a predetermined list.I’ve tried this version out on a decently large (90 kb) JSON file I got from an API, and I was pretty pleased with the results.
from Npp import * # BEGIN SETTINGS AUTOCOMPLETION_MIN_LEN = 2 # min length of word to trigger autocompletion CHARS_TO_MATCH = r'[\w_-]' # characters that can be in "words" (by default most letters, digits, underscores, and dashes) USE_LANGUAGE_IGNORECASE = True # use the document's lexer language setting for ignoring case ENABLED_EXTENSIONS = { '', # files with no extension yet 'csv', 'txt', 'md', 'xml', 'json', 'tsv', 'log', 'dump', 'yaml', 'yml', } # only use for files with these extensions MAX_FILE_SIZE = 200_000 # do not try autocompleting for files with more bytes than this # END_SETTINGS def on_match(m, ctr, ignorecase): '''increase the count of the current word by 1 if ignorecase, store only the uppercase version of each word''' word = m.group(0) if ignorecase: word = word.upper() ctr.setdefault(word, 0) ctr[word] += 1 def getWordRangeUnderCaret(): '''get the start and end of the word under the caret''' pos = editor.getCurrentPos() word_start_pos = editor.wordStartPosition(pos, True) word_end_pos = editor.wordEndPosition(pos, True) return word_start_pos, word_end_pos def getExtension(fname): for ii in range(len(fname) - 1, -1, -1): if fname[ii] == '.': break if ii == 0: return '' return fname[ii + 1:] def onCharInsert(notif): '''Find all words in the document prefixed by the word under the caret and show those words for autocompletion sorted by their frequency. Ignore words with length less than AUTOCOMPLETION_MIN_LEN. May ignore the case of words based on the lexer language (e.g., will ignore case in SQL but not in Python)''' if editor.getLength() > MAX_FILE_SIZE: return ext = getExtension(notepad.getCurrentFilename()) if ext not in ENABLED_EXTENSIONS: return word_start_pos, word_end_pos = getWordRangeUnderCaret() word_length = word_end_pos - word_start_pos word = editor.getRangePointer(word_start_pos, word_length).strip() if word_length < AUTOCOMPLETION_MIN_LEN: return ctr = {} # anything preceded by a non-word-char and starting with the current word match_pat = '(?<!{0}){1}({0}+)'.format(CHARS_TO_MATCH, word) ignorecase = USE_LANGUAGE_IGNORECASE and editor.autoCGetIgnoreCase() if ignorecase: # match case-insenstively if that's the language default match_pat = '(?i)' + match_pat editor.research(match_pat, lambda m: on_match(m, ctr, ignorecase)) autocomp = sorted(ctr, key = lambda x: ctr[x], reverse=True) autocomp_str = ' '.join(autocomp) editor.autoCShow(word_length, autocomp_str) if __name__ == '__main__': try: CALLBACK_ADDED except NameError: CALLBACK_ADDED = 1 editor.callback(onCharInsert, [SCINTILLANOTIFICATION.CHARADDED]) -
@Mark-Olson I honestly didn’t expect someone to write me a plugin, so thanks a lot dude!
But I have a question, how can I get it to suggest me the word I am currently writing at the top of the suggestions only if it is present in the text.
So for example if I have a file than contains this:abc abc abcdWriting “abc” will only suggest “abcd”. While the native autocomplete returns both “abc” and “abcd”. I think it would be appropriate to return “abc” first regardless of the frequency of repetition, this is because it was found in the text, and not truely a “autocomplete”.
I tried coding this myself and failed :( -
@asadMarmash said in How can I get autocomplete to be sorted by frequency of repetition instead of alphabetically?:
and not truely a “autocomplete”.
Exactly. It’s not an autocomplete. If you want to exit out of the auto-complete interface and just accept the word as-is, hit the ESC key.
-
@asadMarmash said in How can I get autocomplete to be sorted by frequency of repetition instead of alphabetically?:
But I have a question, how can I get it to suggest me the word I am currently writing at the top of the suggestions only if it is present in the text.
So for example if I have a file than contains this:New setting.
With setting on and word present in text:
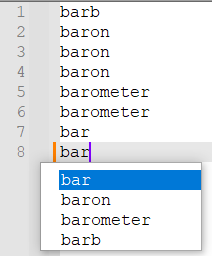
With setting on and word absent in preceding text:
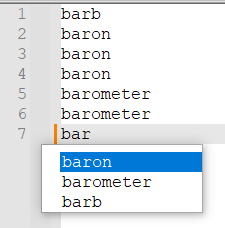
So if the setting is on, the current word is absent from the autocompletion if the current word is its only occurrence, and it shows up first if the current word is present in the preceding text.from Npp import * # BEGIN SETTINGS AUTOCOMPLETION_MIN_LEN = 2 # min length of word to trigger autocompletion CHARS_TO_MATCH = r'[\w_-]' # characters that can be in "words" (by default most letters, digits, underscores, and dashes) USE_LANGUAGE_IGNORECASE = True # use the document's lexer language setting for ignoring case DEFAULT_IGNORECASE = False # should case be ignored if not using language ignorecase? ENABLED_EXTENSIONS = { '', # files with no extension yet 'csv', 'txt', 'md', 'xml', 'json', 'tsv', 'log', 'dump', 'yaml', 'yml', } # only use for files with these extensions MAX_FILE_SIZE = 200_000 # do not try autocompleting for files with more bytes than this CURRENT_WORD_ONLY_IF_IN_TEXT = True # END_SETTINGS def on_match(m, ctr, ignorecase): '''increase the count of the current word by 1 if ignorecase, store only the uppercase version of each word''' word = m.group(0) if ignorecase: word = word.upper() ctr.setdefault(word, 0) ctr[word] += 1 def getWordRangeUnderCaret(): '''get the start and end of the word under the caret''' pos = editor.getCurrentPos() word_start_pos = editor.wordStartPosition(pos, True) word_end_pos = editor.wordEndPosition(pos, True) return word_start_pos, word_end_pos def getExtension(fname): for ii in range(len(fname) - 1, -1, -1): if fname[ii] == '.': break if ii == 0: return '' return fname[ii + 1:] def onCharInsert(notif): '''Find all words in the document prefixed by the word under the caret and show those words for autocompletion sorted by their frequency. Ignore words with length less than AUTOCOMPLETION_MIN_LEN. May ignore the case of words based on the lexer language (e.g., will ignore case in SQL but not in Python)''' if editor.getLength() > MAX_FILE_SIZE: return ext = getExtension(notepad.getCurrentFilename()) if ext not in ENABLED_EXTENSIONS: return word_start_pos, word_end_pos = getWordRangeUnderCaret() word_length = word_end_pos - word_start_pos word = editor.getRangePointer(word_start_pos, word_length).strip() if word_length < AUTOCOMPLETION_MIN_LEN: return ctr = {} # anything preceded by a non-word-char and starting with the current word match_pat = '(?<!{0}){1}({0}*)'.format(CHARS_TO_MATCH, word) ignorecase = DEFAULT_IGNORECASE if USE_LANGUAGE_IGNORECASE: ignorecase = editor.autoCGetIgnoreCase() else: editor.autoCSetIgnoreCase(ignorecase) if ignorecase: # match case-insenstively if that's the language default match_pat = '(?i)' + match_pat editor.research(match_pat, lambda m: on_match(m, ctr, ignorecase)) word_was_in_text = False if ignorecase: word_was_in_text = ctr[word.upper()] > 1 else: word_was_in_text = ctr[word] > 1 if CURRENT_WORD_ONLY_IF_IN_TEXT: del ctr[word] autocomp = sorted(ctr, key = lambda x: ctr[x], reverse=True) if CURRENT_WORD_ONLY_IF_IN_TEXT and word_was_in_text: if ignorecase: autocomp.insert(0, word.upper()) else: autocomp.insert(0, word) autocomp_str = ' '.join(autocomp) editor.autoCShow(word_length, autocomp_str) if __name__ == '__main__': try: CALLBACK_ADDED except NameError: CALLBACK_ADDED = 1 editor.callback(onCharInsert, [SCINTILLANOTIFICATION.CHARADDED]) -
@Mark-Olson This is brilliant! Thank you Mark, I truly appreciate your effort <3
-
Disregard the version I posted in my previous post. It is bugged and does not work.
This version contains a proper working implementation of a feature in which the current word is boosted to the top if it previously occurred and is otherwise not shown.
from Npp import * # BEGIN SETTINGS AUTOCOMPLETION_MIN_LEN = 2 # min length of word to trigger autocompletion CHARS_TO_MATCH = r'[\w_-]' # characters that can be in "words" (by default most letters, digits, underscores, and dashes) USE_LANGUAGE_IGNORECASE = True # use the document's lexer language setting for ignoring case DEFAULT_IGNORECASE = False # should case be ignored if not using language ignorecase? ENABLED_EXTENSIONS = { '', # files with no extension yet 'csv', 'txt', 'md', 'xml', 'json', 'tsv', 'log', 'dump', 'yaml', 'yml', } # only use for files with these extensions MAX_FILE_SIZE = 200_000 # do not try autocompleting for files with more bytes than this CURRENT_WORD_ONLY_IF_IN_TEXT = True # END_SETTINGS def on_match(m, ctr, ignorecase): '''increase the count of the current word by 1 if ignorecase, store only the uppercase version of each word''' word = m.group(0) if ignorecase: word = word.upper() ctr.setdefault(word, 0) ctr[word] += 1 def getWordRangeUnderCaret(): '''get the start and end of the word under the caret''' pos = editor.getCurrentPos() word_start_pos = editor.wordStartPosition(pos, True) word_end_pos = editor.wordEndPosition(pos, True) return word_start_pos, word_end_pos def getExtension(fname): for ii in range(len(fname) - 1, -1, -1): if fname[ii] == '.': break if ii == 0: return '' return fname[ii + 1:] def onCharInsert(notif): '''Find all words in the document prefixed by the word under the caret and show those words for autocompletion sorted by their frequency. Ignore words with length less than AUTOCOMPLETION_MIN_LEN. May ignore the case of words based on the lexer language (e.g., will ignore case in SQL but not in Python)''' if editor.getLength() > MAX_FILE_SIZE: return ext = getExtension(notepad.getCurrentFilename()) if ext not in ENABLED_EXTENSIONS: return word_start_pos, word_end_pos = getWordRangeUnderCaret() word_length = word_end_pos - word_start_pos word = editor.getRangePointer(word_start_pos, word_length).strip() if word_length < AUTOCOMPLETION_MIN_LEN: return ctr = {} # anything preceded by a non-word-char and starting with the current word match_pat = '(?<!{0}){1}({0}*)'.format(CHARS_TO_MATCH, word) ignorecase = DEFAULT_IGNORECASE if USE_LANGUAGE_IGNORECASE: ignorecase = editor.autoCGetIgnoreCase() else: editor.autoCSetIgnoreCase(ignorecase) if ignorecase: # match case-insenstively if that's the language default match_pat = '(?i)' + match_pat editor.research(match_pat, lambda m: on_match(m, ctr, ignorecase)) if CURRENT_WORD_ONLY_IF_IN_TEXT: if ignorecase: upword = word.upper() if upword in ctr: if ctr[upword] > 1: # word earlier in text, move to front ctr[upword] = 10_000_000_000 else: del ctr[upword] # word not in text, remove elif word in ctr: if ctr[word] > 1: ctr[word] = 10_000_000_000 else: del ctr[word] autocomp = sorted(ctr, key = lambda x: ctr[x], reverse=True) autocomp_str = ' '.join(autocomp) editor.autoCShow(word_length, autocomp_str) if __name__ == '__main__': try: CALLBACK_ADDED except NameError: CALLBACK_ADDED = 1 editor.callback(onCharInsert, [SCINTILLANOTIFICATION.CHARADDED])
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login