Help duplicate files
-
@Adriano When I have a complicated project I prefer to do it in several easy to understand steps rather than inventing a nearly impossible for normal humans to understand and maintain solution that does it all in one step.
Thus, I would do the project as:
- Insert a line number at the start of each line, counting from 0001, 0002, 0003, etc. if you expect up to 10000 lines.
- Make a copy of the 8th value (which was the 7th value before we inserted the line numbers) and insert it at the beginning of each line. Thus line 1 would look like:
420302;0001;30-00000000-9;705;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; - Sort the file.
- Remove lines where the first value is a duplicate of the line before it.
- Remove the first value from each line that we had added at step 2 above.
- Sort the file again. This restores the original line order.
- Remove the first value from each line to get rid of the line numbers we added at step 1.
-
Thanks for your answer, from the whole row what matters is the following data
420302;17/05/2023
230178;17/05/2023
347211;17/05/2023
230133;17/05/2023
420302;17/05/2023
347211;17/05/2023
I am trying to create a regex to only find duplicates in the mentioned group but it does not work. -
@Paul-Wormer It is not allowed to modify the lines or the order of the lines.
-
@mkupper Select the part of the text with the following expression
[0-9]+.;([0-9]+(/[0-9]+)+)
Now I just need to compare, which is the part I don’t know. -
Hello, @adriano, @paul-wormer, @mkupper and All,
@adriano, I think that the following regex S/R would do the job :
SEARCH
(?-s)^(?:;[^;\r\n]+){6}(.+\R)(?=(?s:.*?)^.+\1)REPLACE
Leave EMPTYSo, from this INPUT file :
;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;10;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;705;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;705;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;11175;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230133;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;9072;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;10;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1;You would get the expected OUTPUT text below :
;30-00000000-9;86;0;0;0;1;230133;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;9072;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;10;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1;
Notes :
-
This regex S/R always keep the last duplicates
-
This regex S/R does not change the lines order !
-
But, this regex S/R could fail if there are, let’s say,
500or more lines, all different, between twoduplicates!
Best Regards,
guy038
-
-
Hi, @adriano and All,
Reading more carefully your needs, as you said :
Thanks for your answer, from the whole row what matters is the following data
420302;17/05/2023
230178;17/05/2023
347211;17/05/2023
230133;17/05/2023
420302;17/05/2023
347211;17/05/2023Then I suppose that the following regex S/R is the best bet :
SEARCH
(?-s)^(?:;[^;\r\n]+){6}(;[^;\r\n]+;\d\d/\d\d/\d{4}\x20).+\R(?=(?s:.*?)^.+\1)REPLACE
Leave EMPTYBR
guy038
-
This post is deleted! -
@guy038 Thank you, only searches for adjacent
-
@guy038 Sorry if it works it was just a syntax error, thanks you.
-
@guy038 said in Help duplicate files:
Hello, @adriano, @paul-wormer, @mkupper and All,
@adriano, I think that the following regex S/R would do the job :
SEARCH
(?-s)^(?:;[^;\r\n]+){6}(.+\R)(?=(?s:.*?)^.+\1)REPLACE
Leave EMPTYSo, from this INPUT file :
;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;10;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;705;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;705;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;11175;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230133;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;9072;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;10;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1;You would get the expected OUTPUT text below :
;30-00000000-9;86;0;0;0;1;230133;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;9072;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;10;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1;
Notes :
-
This regex S/R always keep the last duplicates
-
This regex S/R does not change the lines order !
-
But, this regex S/R could fail if there are, let’s say,
500or more lines, all different, between twoduplicates!
Best Regards,
guy038
What do I do if it has more than 500 lines, my current document has 3300 lines?
-
-
Before I continue, I will say what I think you mean:
<1st group of six lines> foo bar baz pon hoj baz <2nd group of six lines> foo bar baz qws uye qwsIn this example (assuming we are looking for duplicate lines in a group of six) we would want our final result to be
<1st group of six lines> foo bar pon hoj baz <2nd group of six lines> foo bar baz uye qwsbecause we removed the only lines that had a duplicate within their group of six lines.
If I’m right, my solution below will work better than guy038’s.
- Separate each group of six lines using a delimiter that doesn’t occur naturally in the text (I chose the
BELcharacter)- FIND:
(?-s)(?:\A|\G)^(?:.*\R){6}\K - REPLACE WITH:
\x07\r\n

- FIND:
- Mark every line with a region of interest that is duplicated in another region of interest within the next six lines (i.e., before the next
BELcharacter)- Mark all
(?-s)^(?:;[^;\r\n]+){6};\K(\d+;\d\d/\d\d/\d{4})(?=[^\x07]+^(?:;[^;\r\n]+){6};\1.+\R?)(Bookmark lineselected!)
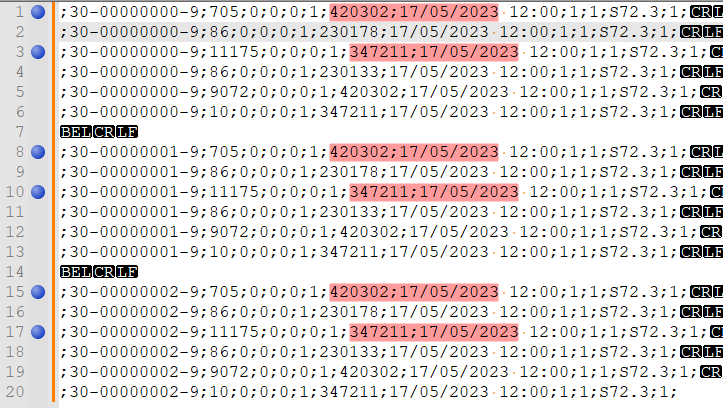
- Mark all
- Go to
Search->Bookmark->Remove bookmarked lines. This will remove all lines that have a duplicate within their group of six lines.
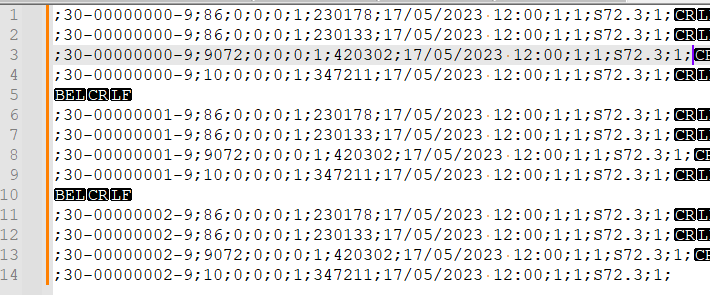
- Replace
^\x07\r\nwith EMPTY. This will remove the lines with theBELcharacters that I inserted.
- Separate each group of six lines using a delimiter that doesn’t occur naturally in the text (I chose the
-
@Mark-Olson said in Help duplicate files:
Before I continue, I will say what I think you mean:
<1st group of six lines> foo bar baz pon hoj baz <2nd group of six lines> foo bar baz qws uye qwsIn this example (assuming we are looking for duplicate lines in a group of six) we would want our final result to be
<1st group of six lines> foo bar pon hoj baz <2nd group of six lines> foo bar baz uye qwsbecause we removed the only lines that had a duplicate within their group of six lines.
If I’m right, my solution below will work better than guy038’s.
- Separate each group of six lines using a delimiter that doesn’t occur naturally in the text (I chose the
BELcharacter)- FIND:
(?-s)(?:\A|\G)^(?:.*\R){6}\K - REPLACE WITH:
\x07\r\n
- FIND:
- Mark every line with a region of interest that is duplicated in another region of interest within the next six lines (i.e., before the next
BELcharacter)- Mark all
(?-s)^(?:;[^;\r\n]+){6};\K(\d+;\d\d/\d\d/\d{4})(?=[^\x07]+^(?:;[^;\r\n]+){6};\1.+\R?)(Bookmark lineselected!)
- Mark all
- Go to
Search->Bookmark->Remove bookmarked lines. This will remove all lines that have a duplicate within their group of six lines.
- Replace
^\x07\r\nwith EMPTY. This will remove the lines with theBELcharacters that I inserted.
It’s not really six lines, it’s a file of 3300 correlative lines, but thanks for your help.
With the following expression I managed to select the code plus the date but I did not find the way to compare them
[0-9]+;([0-9]+(/[0-9]+)+) - Separate each group of six lines using a delimiter that doesn’t occur naturally in the text (I chose the
-
@Adriano said in Help duplicate files:
It’s not really six lines, it’s a file of 3300 correlative lines, but thanks for your help.
The advice that @mkupper gave you near the beginning of this topic is the right way to solve the problem if you have too many lines, because the regex buffer cannot store thousands of bytes between the “first” and “second” when doing these complex manipulations.
It is not allowed to modify the lines or the order of the lines.
You can modify the order temporarily, and then restore. This is exactly what @mkupper suggested in that early message
Given the additional instructions that the other helpers have dragged out of you from multiple back-and-forth, I would do a slightly modified version @mkupper 's suggestion, though I’ll give more details on a couple things, too
- Insert a line number at the start of each line, with a separator:
- Search > Replace
FIND WHAT =^
REPLACE WITH =☺(or some other character that you don’t have in your data)
SEARCH MODE = regular expression
Replace All
(This will put a separator between the line number that we will soon input) Ctrl+Home- Edit > Begin/End Select in Column Mode to begin a column selection
Ctrl+End- if you don’t have a blank line at the end of the document, hit ENTER to make such
- Edit > Begin/End Select in Column Mode to end the column selection
- Edit > Column Editor (or
Alt+C)- Initial Number =
1 - Increase By =
1 - Leading =
Zeroes
- Initial Number =
- Search > Replace
- Make a copy of the ######;##/##/####:
- Search > Replace
FIND WHAT =(?-s)(^\d+☺)(?=.*?([0-9]+.;([0-9]+(/[0-9]+)+)).*$)
REPLACE WITH =☺$1☺
SEARCH MODE = regular expression
Replace All - You should now have data that looks like
420302;17/05/2023☺01☺;30-00000000-9;705;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1;
- Search > Replace
- Sort the file.
- Remove lines where the prefix is the same on multiple sequential rows (ie, duplicates):
- Search > Replace
FIND WHAT =(?-s)^(.*)(☺.*\R)(\1.*\R)+(if there are N = two or more rows that start with the same prefix)
REPLACE WITH =$1$2(replace it with only the first row rather than the N rows)
SEARCH MODE = regular expression
Replace All
- Search > Replace
- Remove the first value from each line that we had added at step 2 above.
- Search > Replace
FIND WHAT =(?-s)^[0-9]+.;([0-9]+(/[0-9]+)+)☺
REPLACE WITH = (make it empty, so it will be replaced with nothing)
SEARCH MODE = regular expression
Replace All
- Search > Replace
- Sort the file again. This restores the original line order.
- Remove the first value from each line to get rid of the line numbers we added at step 1.
- Search > Replace
FIND WHAT =(?-s)^[0-9]+☺
REPLACE WITH = (make it empty, so it will be replaced with nothing)
SEARCH MODE = regular expression
Replace All
- Search > Replace
-—
Useful References
- Please Read Before Posting
- Template for Search/Replace Questions
- Formatting Forum Posts
- Notepad++ Online User Manual: Searching/Regex
- FAQ: Where to find other regular expressions (regex) documentation
-—
Please note: This Community Forum is not a data transformation service; you should not expect to be able to always say “I have data like X and want it to look like Y” and have us do all the work for you. If you are new to the Forum, and new to regular expressions, we will often give help on the first one or two data-transformation questions, especially if they are well-asked and you show a willingness to learn; and we will point you to the documentation where you can learn how to do the data transformations for yourself in the future. But if you repeatedly ask us to do your work for you, you will find that the patience of usually-helpful Community members wears thin. The best way to learn regular expressions is by experimenting with them yourself, and getting a feel for how they work; having us spoon-feed you the answers without you putting in the effort doesn’t help you in the long term and is uninteresting and annoying for us.
- Insert a line number at the start of each line, with a separator:
-
@Adriano said in Help duplicate files:
I need to do when they are equal after the seventh row is to eliminate one of the two rows
@Adriano said in Help duplicate files:
It is not allowed to modify the lines or the order of the lines.
Can you install and use a new Plugin? If it is allowed, then download CsvQuery and execute with it the following SQLLight query:
SELECT * FROM THIS GROUP BY COL8, COL9You might need to modify the names of Col8 and Col9 to mach your specific case.
The results are shown in the following screenshot:
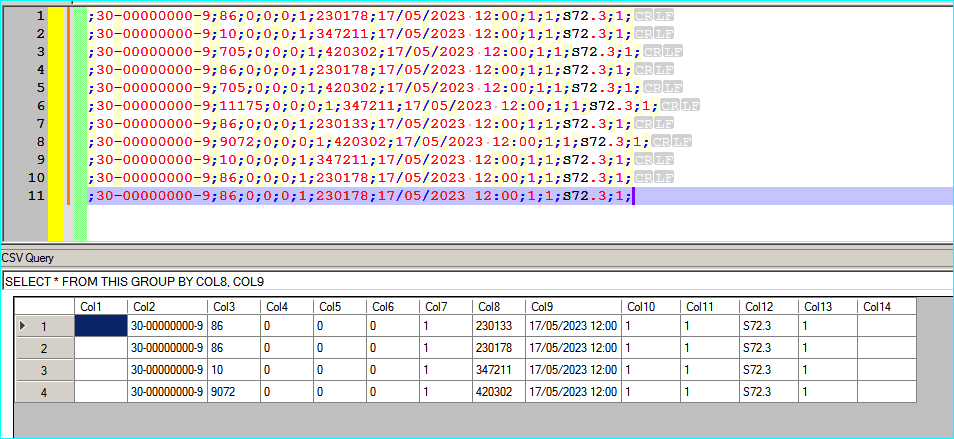
After that, you can right click on the CsvQuery table, create a new csv file with the results that will be:
;30-00000000-9;86;0;0;0;1;230133;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;10;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1; ;30-00000000-9;9072;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1;and now you can copy and past them back to the original file, if you need to modify the original one or if you want you can simply save the new one as a separated file.
-
@wonkawilly Your solution, elegant as it is, changes the order of the lines. The solutions of @mkupper and @PeterJones are fairly complex exactly because they conserve the order.
-
@guy038 @Paul-Wormer @mkupper @Mark-Olson @PeterJones @wonkawilly
Thank you all for your help, here is a complete summary of the report, only the REL_P to DIA_ part is used.
From that list you should find the duplicates.PRES
INTER
30-10000010-9;;;0;0;0;1;;;1;;6;155598642307;00;210920;1;ESP;17/05/2023;11:15;01/06/2023;18:00;1;0;;0;0;0;0;0;0;1;0
REL_D
;;;0;1;S72.3;1;1
REL_P
;30-10000010-9;705;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;11175;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;230133;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770772;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770192;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770902;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770412;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;705;0;0;0;1;177141;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770171;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770546;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;18/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;19/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;20/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;770192;21/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;770902;21/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;770546;21/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;770412;21/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;230178;21/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;21/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;230133;21/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;770711;21/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;22/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;23/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770902;24/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770412;24/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770546;24/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;230178;24/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770711;24/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770192;24/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;24/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;230133;24/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;25/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;26/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;27/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;28/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;121012;29/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;170175;29/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;10;0;0;0;1;347211;29/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;121012;29/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;29/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;11175;0;0;0;1;347211;29/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;4066;0;0;0;1;121012;29/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;230133;30/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;230178;30/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770192;30/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770412;30/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770546;30/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770711;30/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;86;0;0;0;1;770902;30/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;30/05/2023 12:00;1;1;S72.3;1;
;30-10000010-9;9072;0;0;0;1;420302;31/05/2023 12:00;1;1;S72.3;1;
DIA_
;;;0;PISO;17/05/2023;11:15;01/06/2023;18:00;1
MED
;;40017;0;9710;;;0;14.00;17/05/2023;11:15
;;40017;0;18163;;;0;1.00;17/05/2023;11:15
;;40017;0;29326;;;0;45.00;17/05/2023;11:15
;;40017;0;29366;;;0;3.00;17/05/2023;11:15
;;40017;0;37703;;;0;1.00;17/05/2023;11:15
;;40017;0;40346;;;0;1.00;17/05/2023;11:15
;;40017;0;42627;;;0;1.00;17/05/2023;11:15
;;40017;0;47536;;;0;4.00;17/05/2023;11:15
;;40017;0;47571;;;0;6.00;17/05/2023;11:15
;;40017;0;50467;;;0;1.00;17/05/2023;11:15
;;40017;0;50813;;;0;14.00;17/05/2023;11:15
;;40017;0;51456;;;0;1.00;17/05/2023;11:15
;;40017;0;55439;;;0;43.00;17/05/2023;11:15
;;40017;0;55442;;;0;24.00;17/05/2023;11:15
;;40017;0;12369;;;0;1.00;17/05/2023;11:15
;;40017;0;6960;;;0;90.00;17/05/2023;11:15
;;40017;0;9606;;;0;2.00;17/05/2023;11:15
FIN -
I found that while I was copying my earlier regexes into here, I made some mistakes (I probably accidentally grabbed intermediate copies of the regex rather than the final, as I fixed problems along the way. sorry).
@Adriano said in Help duplicate files:
here is a complete summary of the report
After fixing those mistakes, I still had to tweak a couple things, because your new data had exceptions that weren’t covered by your original data, so some of the regex were matching too many of the lines. (This would have been prevented if you’d actually posted your big list – in a plain-text/code block like I do below – originally, rather than giving an abbreviated list.)
So here are the steps from my list above that need to change to work with your new data.
- same as above
- FIND =
(?-s)(^\d+☺)(?=.*?((?<=;)[0-9]+.;([0-9]+(/[0-9]+)+)).*$)
REPLACE =☺$2☺$1
Example resulting line:☺420302;17/05/2023☺07☺;30-10000010-9;705;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; - same as above
- FIND =
(?-s)^(☺.*?)(☺\d+☺.*\R)(\1.*\R)+
REPLACE =$1$2 - FIND =
(?-s)^☺[0-9]+;([0-9]+(/[0-9]+)+)☺
REPLACE = empty the replacement box (replace with nothing) - same as above
7 same as above
With using that exact sequence, I took your data from your most recent post, and deleted 5 lines that had duplicates of the
121012;29/05/2023,347211;17/05/2023,347211;29/05/2023, and420302;17/05/2023rows. I believe that’s what you wanted. If not, sorry. It’s the best I can or will do for you.PRES INTER 30-10000010-9;;;0;0;0;1;;;1;;6;155598642307;00;210920;1;ESP;17/05/2023;11:15;01/06/2023;18:00;1;0;;0;0;0;0;0;0;1;0 REL_D ;;;0;1;S72.3;1;1 REL_P ;30-10000010-9;705;0;0;0;1;420302;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;230178;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;11175;0;0;0;1;347211;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;230133;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770772;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770192;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770902;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770412;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;705;0;0;0;1;177141;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770171;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770546;17/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;18/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;19/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;20/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;10;0;0;0;1;770192;21/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;10;0;0;0;1;770902;21/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;10;0;0;0;1;770546;21/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;10;0;0;0;1;770412;21/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;10;0;0;0;1;230178;21/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;21/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;10;0;0;0;1;230133;21/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;10;0;0;0;1;770711;21/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;22/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;23/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770902;24/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770412;24/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770546;24/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;230178;24/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770711;24/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770192;24/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;24/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;230133;24/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;25/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;26/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;27/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;28/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;10;0;0;0;1;121012;29/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;10;0;0;0;1;170175;29/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;10;0;0;0;1;347211;29/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;29/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;230133;30/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;230178;30/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770192;30/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770412;30/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770546;30/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770711;30/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;86;0;0;0;1;770902;30/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;30/05/2023 12:00;1;1;S72.3;1; ;30-10000010-9;9072;0;0;0;1;420302;31/05/2023 12:00;1;1;S72.3;1; DIA_ ;;;0;PISO;17/05/2023;11:15;01/06/2023;18:00;1 MED ;;40017;0;9710;;;0;14.00;17/05/2023;11:15 ;;40017;0;18163;;;0;1.00;17/05/2023;11:15 ;;40017;0;29326;;;0;45.00;17/05/2023;11:15 ;;40017;0;29366;;;0;3.00;17/05/2023;11:15 ;;40017;0;37703;;;0;1.00;17/05/2023;11:15 ;;40017;0;40346;;;0;1.00;17/05/2023;11:15 ;;40017;0;42627;;;0;1.00;17/05/2023;11:15 ;;40017;0;47536;;;0;4.00;17/05/2023;11:15 ;;40017;0;47571;;;0;6.00;17/05/2023;11:15 ;;40017;0;50467;;;0;1.00;17/05/2023;11:15 ;;40017;0;50813;;;0;14.00;17/05/2023;11:15 ;;40017;0;51456;;;0;1.00;17/05/2023;11:15 ;;40017;0;55439;;;0;43.00;17/05/2023;11:15 ;;40017;0;55442;;;0;24.00;17/05/2023;11:15 ;;40017;0;12369;;;0;1.00;17/05/2023;11:15 ;;40017;0;6960;;;0;90.00;17/05/2023;11:15 ;;40017;0;9606;;;0;2.00;17/05/2023;11:15 FINPlease note: Because you didn’t even bother reporting on the results when you tried my previous sequence, I am assuming that you didn’t actually try; and you obviously didn’t make note of any of the resources I linked, especially the ones that show how to insert data in search/replace questions so that it ends up in a “plain text box” (aka “code box”). As a result, I am not convinced that my helping you has been worth all the effort I’ve put into my posts in this discussion. Since I made mistakes when I published my previous solution, I am posting this version as a correction. However, if this isn’t sufficient, then I am not willing and/or able to help you any more, and I wish you the best of luck.
-
@Adriano said in Help duplicate files:
@mkupper Select the part of the text with the following expression
[0-9]+.;([0-9]+(/[0-9]+)+)
Now I just need to compare, which is the part I don’t know.I am confused about why you have a dot. Your regex starts out with
[0-9]+.;which will match one or more numeric digits followed by any character followed by a semicolon. In the example data you have provided so far I only see numeric digits immediately followed by a semicolon meaning[0-9]+;will work unless there is something about your data you are not showing to us.Is the
17/05/2023part in the data a date in dd/mm/yyyy format? If so, then your;([0-9]+(/[0-9]+)+)regex expression would match many things that are not dates. That is dangerous as you may accidentally match something you did not intend to match. Examples of non-dates that are matched by your expression are:;12345/12345 ;12345/12345/12345 ;12345/12345/12345/12345/12345 ;0/0 ;0/0/0 ;0/0/0/0 ;0/0/0/0/0Is this intentional or do you want to match just dd/mm/yyyy format dates? I am going to assume that you only have dates and so if this was my data I would use
;[0-3][0-9]/[01][0-9]/20[0-9][0-9]It’s not perfect but is short and easy for humans to see what is happening.Thus, I would change the regex that locates the data to be
(;[0-9]+;[0-3][0-9]/[01][0-9]/20[0-9][0-9])I added a;at the front to make it less likely to accidentally match something in the data that you did not intend to match.To handle the “Now I just need to compare, which is the part I don’t know” part of the question the rexexp becomes:
Search for:
^(.+(;[0-9]+;[0-3][0-9]/[01][0-9]/20[0-9][0-9]) .+\R)(.+\2.+\R)+
Replace with\1That will find consecutive lines that contain the same pattern we are interested in and removes all of the duplicate lines.
Earlier I had suggested breaking the problem down into easier to understand parts. We can allow for non-consecutive lines but the expression becomes harder to understand.
Search for:
^(.+(;[0-9]+;[0-3][0-9]/[01][0-9]/20[0-9][0-9]) .+\R)(.+\R)*?(.+\2.+\R)+
Replace with\1\3Repeat that over and over until it stops finding matches There are four main groups:
\1 or
^(.+(;[0-9]+;[0-3][0-9]/[01][0-9]/20[0-9][0-9]) .+\R)is the entire first line of data where some later line also has the same data we are interested in/\2 or
(;[0-9]+;[0-3][0-9]/[01][0-9]/20[0-9][0-9])is inside \1 and both matches and captures the data pattern we are interested in.\3 or
(.+\R)*?matches zero or more lines of data. The?at the end makes this a non-greedy match meaning it will stop as soon as we hit part \4.\4 or
(.+\2.+\R)+is the part that matches a line that contains the \2 pattern we are interested in. The+at the end is optional and allows us to match consecutive lines that contain the \2 pattern we are interested in.The replacement of
\1\3gives us the first line with the data pattern and the possibly empty list of lines that don’t contain the data pattern. We discard \4 which are the lines that contain duplicates of the \2 pattern.While it works for testing this will fail in strange ways if your data contains thousands of lines. The
\3capturing group can’t handle more than a few thousand lines. It’s an issue with the regular expression engine. That’s part of why I suggested earlier to sort the data and then re-sorting. -
@mkupper You are absolutely right my regex is not very reliable, instead the one you created (^(.+(;[0-9]+;[0-3][0-9]/[01][0-9]/20[0-9][0-9][0-9]) .+R)(.+2.+R)+) works very well with the repeated consecutives now I only have to manually make the non consecutives, thank you very much for all the help.
-
This post is deleted!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login