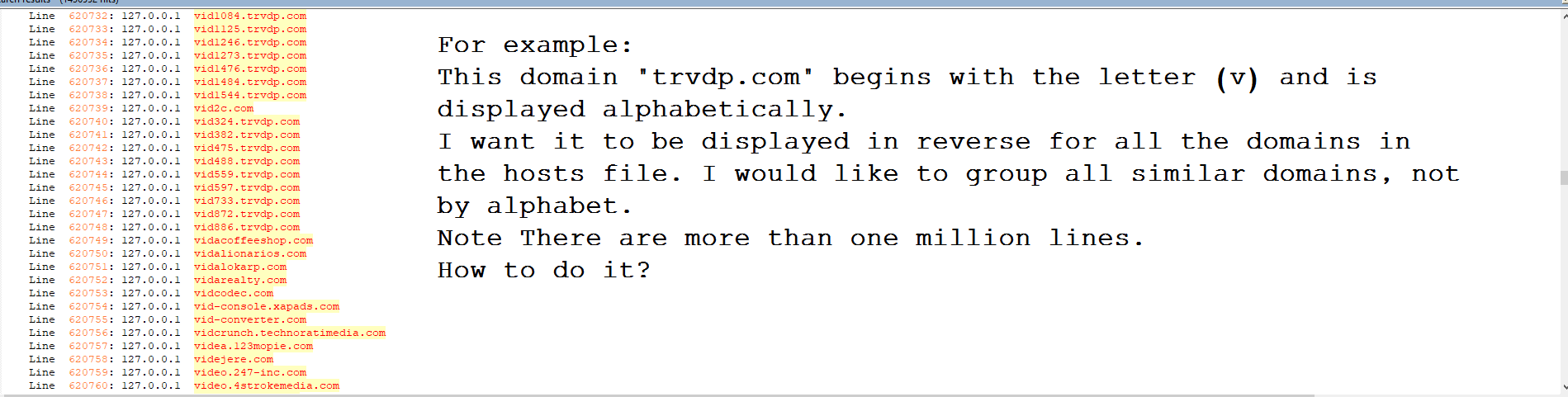
I would like to group all similar domains, not by alphabet.
-
I want it to be displayed in reverse for all the domains in the hosts file. I would like to group all similar domains, not by alphabet.
… How to do it?You cannot do it simply. You have to manipulate the data to do the sort, because Notepad++ has no way to split into tokens and then sort (akin to linux
cut ... | sort ...incantation) – but the data edits can be a temporary thing, so you can end up with the desired results with a multi-step solution:Assume that you will always have two or three components in the server (
example.comora.example.combut notfour.three.example.com), and that valid characters in the tokens of the server are alphanumeric, underscore, and hyphen.-
Example Data:
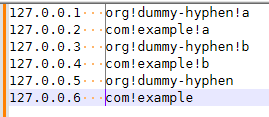
127.0.0.1 a.dummy-hyphen.org 127.0.0.2 a.example.com 127.0.0.3 b.dummy-hyphen.org 127.0.0.4 b.example.com 127.0.0.5 dummy-hyphen.org 127.0.0.6 example.com -
Change from
a.b.ctoc!b!a(using the old internet convention of exclamations for TLD-first lists)
FIND =(?<=\h)([\w-]+)(?:\.([\w-]+))(?:\.([\w-]+))?
REPLACE =(?3$3!)(?2$2!)(?1$1)
SEARCH MODE = Regular Expression
REPLACE ALL127.0.0.1 org!dummy-hyphen!a 127.0.0.2 com!example!a 127.0.0.3 org!dummy-hyphen!b 127.0.0.4 com!example!b 127.0.0.5 org!dummy-hyphen 127.0.0.6 com!example -
Column selection between IP and backwards server name
- Ctrl-Home, then click between the first IP and server, then Edit > Begin/End Select in Column Mode to start column mode selection
- Ctrl-End, then click between the last IP and server, then Edit > Begin/End Select in Column Mode to end column mode selection
-
Sort while the column selection is still active: Edit > Line Operations > Sort Lines Lexicographically Ascending
127.0.0.6 com!example 127.0.0.2 com!example!a 127.0.0.4 com!example!b 127.0.0.5 org!dummy-hyphen 127.0.0.1 org!dummy-hyphen!a 127.0.0.3 org!dummy-hyphen!b -
Change from
c!b!atoa.b.c
FIND =(?<=\h)([\w-]+)(?:\!([\w-]+))(?:\!([\w-]+))?
REPLACE =(?3$3.)(?2$2.)(?1$1)
SEARCH MODE = Regular Expression
REPLACE ALL127.0.0.6 example.com 127.0.0.2 a.example.com 127.0.0.4 b.example.com 127.0.0.5 dummy-hyphen.org 127.0.0.1 a.dummy-hyphen.org 127.0.0.3 b.dummy-hyphen.org
It is now alphabetical by TopLevel, then by second level, then (if available) by third level.
If you wanted more than the 2-3 sections that I assumed in the hostname, you would have multiple of the
(?:\.([\w-]+))?at the end of the FIND, and prefix more(?ℕ$ℕ!)on the REPLACE-—
Useful References
-
-
If I understand the problem correctly, my plugin Columns++ can do this.
After installing the plugin, select the entire file and select Sort… from the Columns++ menu.
Fill in the dialog that opens like this:
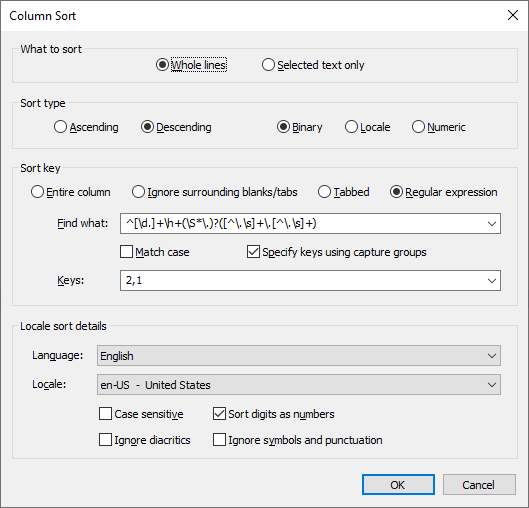
then click the OK button; click OK again when asked to convert to a rectangular selection.
The settings you need are:
What to sort: Whole lines
Sort type: Descending and Binary
Sort key: Regular expression
Find what:^[\d.]+\h+(\S*\.)?([^\.\s]+\.[^\.\s]+)
Specify keys using capture groups checked
Keys:2,1Locale sort details need not be changed.
I am assuming the “Line _____:” prefixes in your image are not part of the actual file; if they are, then you’ll need to modify the regular expression to account for them.
Also, I took your intent to be to sort first by the domain name, then by the sub-domains (if any), both descending. If you wanted something else, you can consult the help or ask here.
Edit: The regular expression I gave (
^[\d.]+\h+(.*\.)?([^\.\r\n]+\.[^\.\r\n]+)(\h.*)?$) was not well-chosen. (It was meant to skip anything following the first or only server name, but it doesn’t do that.) I replaced it with a better one. -
Hello, @mohammad-al-thobiti, @peterjones, @coises and All,
@peterjones, you could have used the same regex, just without changing the dot by the exclamation mark !
Indeed, in this case, we have the rule
Regex ( Regex (text) ) = Identity, meaning that after using the regex twice, you text is identical to the orignal oneIn addition, I extended the possible links to
4sections as, for instance, the linkab.cd.ef.com
Thus, starting with this INPUT text :
127.0.0.1 a.dummy-hyphen.org 127.0.0.2 a.example.com 127.0.0.3 cdef.x.example.com 127.0.0.3 b.dummy-hyphen.org 127.0.0.4 b.example.com 127.0.0.6 cd.xyztuv.example.com 127.0.0.5 dummy-hyphen.org 127.0.0.6 example.comWith the regex S/R :
-
SEARCH
(?x) (?<= \h ) ( [\w-]+ ) (?: \. ( [\w-]+ )) (?: \. ( [\w-]+ ) (?: \. ( [\w-]+ ) )? )? -
REPLACE
(?4$4.)(?3$3.)(?2$2.)(?1$1)
=> You get the temporary text :
127.0.0.1 org.dummy-hyphen.a 127.0.0.2 com.example.a 127.0.0.3 com.example.x.cdef 127.0.0.3 org.dummy-hyphen.b 127.0.0.4 com.example.b 127.0.0.6 com.example.xyztuv.cd 127.0.0.5 org.dummy-hyphen 127.0.0.6 com.example-
Perform a
ZERO-LENGTHRECTANGULAR selection on all the lines on column13 -
Run the
Edit > Line Operations > Sort Lines Lexicographically Acsendingoption
=> Your text becomes :
127.0.0.6 com.example 127.0.0.2 com.example.a 127.0.0.4 com.example.b 127.0.0.3 com.example.x.cdef 127.0.0.6 com.example.xyztuv.cd 127.0.0.5 org.dummy-hyphen 127.0.0.1 org.dummy-hyphen.a 127.0.0.3 org.dummy-hyphen.b- Apply the same regex S/R than previously :
=> You should get the expected OUTPUT text :
127.0.0.6 example.com 127.0.0.2 a.example.com 127.0.0.4 b.example.com 127.0.0.3 cdef.x.example.com 127.0.0.6 cd.xyztuv.example.com 127.0.0.5 dummy-hyphen.org 127.0.0.1 a.dummy-hyphen.org 127.0.0.3 b.dummy-hyphen.orgBest Regards,
guy038
-
-
@ guy038 @ peterjones, @ coises and All
Thank you all
I Removed all 127.0.0.1 lines to avoid any complexity, I left only Domains.
So I can collect it by gropes. After I use it :
With the regex S/R :SEARCH
(?x) (?<= \h ) ( [\w-]+ ) (?: \. ( [\w-]+ )) (?: \. ( [\w-]+ ) (?: \. ( [\w-]+ ) )? )?REPLACE
(?4$4.)(?3$3.)(?2$2.)(?1$1)I had an error (Find: Invalid Regular Expression) after entering the regular expression.
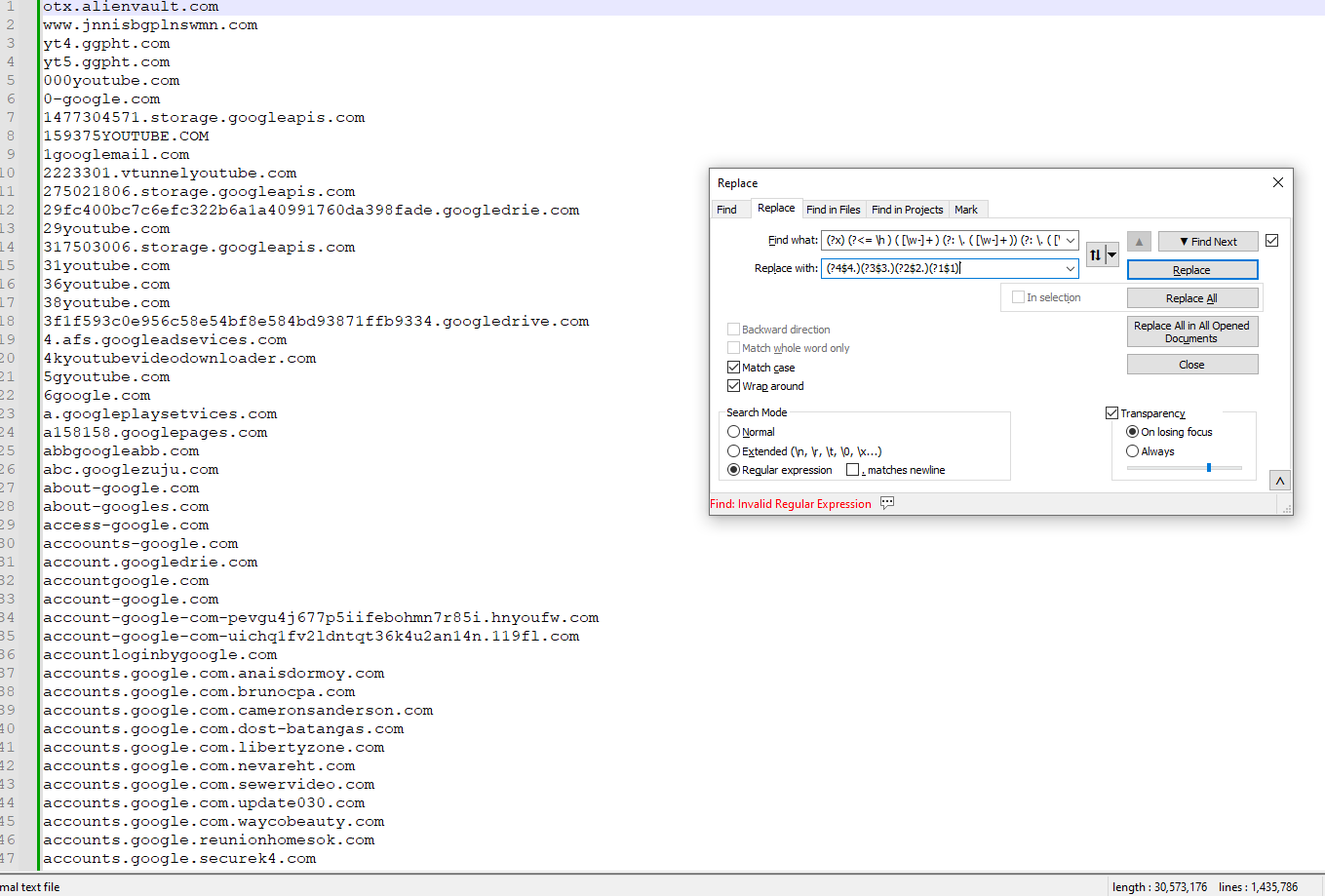
How can I Fix it? whit only domains using
/.example.com/sand not for all subdomains, because some of them are too long more than 4 sections, for instance, the link
ab.cd.ef.comas you said.
Thank you. -
/.example.com/s
\.example.com\s -
Hi, @mohammad-al-thobiti, @peterjones, @coises and All,
Ah… OK ! As you prefered to delete the leading IP adresses and the following blank characters, as well, the regex S/R must be changed as :
-
SEARCH
(?x) ( [\w-]+ ) (?: \. ( [\w-]+ )) (?: \. ( [\w-]+ ) (?: \. ( [\w-]+ ) )? )? -
REPLACE
(?4$4.)(?3$3.)(?2$2.)(?1$1)
So, from this example of INPUT text :
a.dummy-hyphen.org a.example.com cdef.x.example.com b.dummy-hyphen.org b.example.com cd.xyztuv.example.com dummy-hyphen.org example.com…At the very end…, you should get this OUTPUT text :
example.com a.example.com b.example.com cdef.x.example.com cd.xyztuv.example.com dummy-hyphen.org a.dummy-hyphen.org b.dummy-hyphen.org
BTW, to know the maximum of sections of your URL adresses, contained in your file :
-
First, copy your URL file list as
sections.txt -
Open the
sections.txtwithin Notepad++ -
Use the following regex S/R :
-
SEARCH
[^.\r\n] -
REPLACe
Leave EMPTY -
Tick the
Regular expressionsearch mode -
Clik on the
Replace Allbutton
-
=> You should get a list of dots ONLY
-
Now, run the
Edit > Line Operations > Sort Lines Lexicographically Ascendingoption ( No selection needed ) -
Go to the very end of the
sections.txtfile (Ctrl + End) -
Simply, count the number of dots of the last line
-
Delete this dummy file !
Could you tell us which is this number ? Thanks !
BR
guy038
-
-
@ guy038
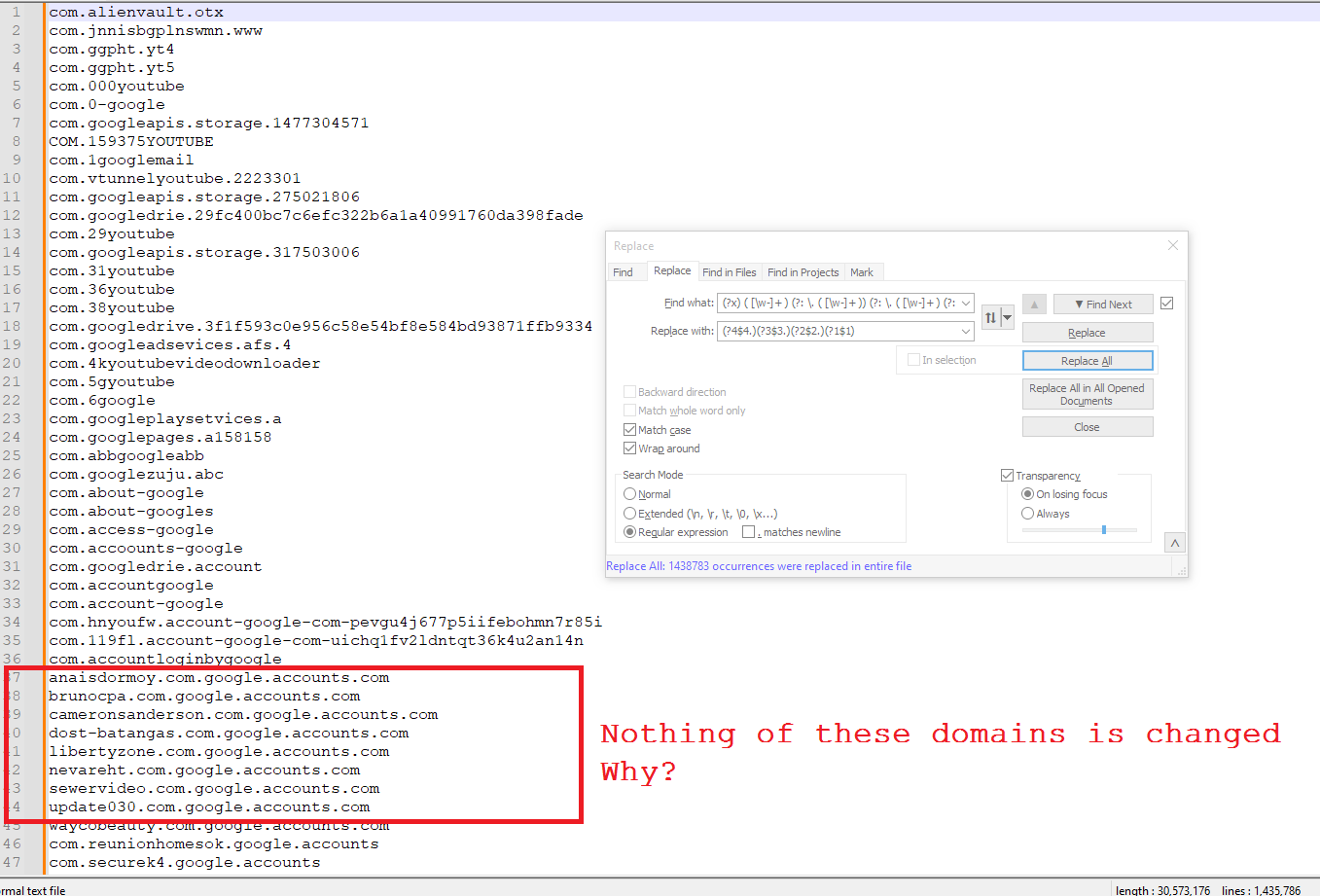
Oh, Thank you.
some of them work well, but not all as you can see below:
-
Hi, @mohammad-al-thobiti and All,
This is the expected behaviour because these addresses contain
5sections :anaisdormoy.com.google.accounts.com <----1----> <2>.<-3--> <--4---> <5>And my regex works ONLY IF up to
4dots only !
So, as I asked you in my previous post, just do the second part steps to determine how many sections contains your file !
See you later !
BR
guy038
-
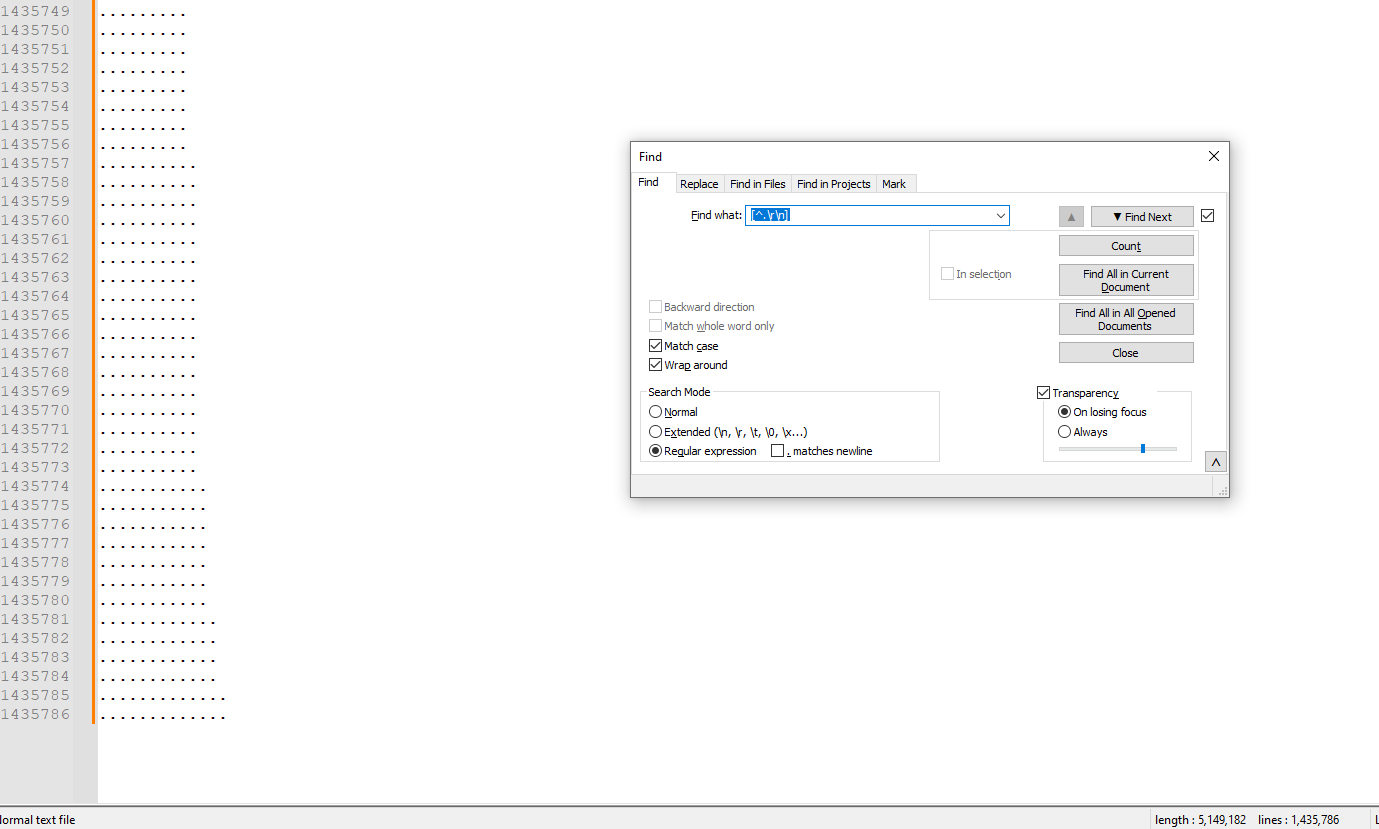
Could you tell us which is this number?
The number is 13 dots!
-
Hello @mohammad-al-thobiti and All,
Ah… OK !! So, give me some time to find out the correct regex S/R which could handle and revert up to
13sections !!See you later,
Best Regards
guy038
-
This post is deleted! -
@Coises said in I would like to group all similar domains, not by alphabet.:
Commas are not allowed in domain names, so we can use a comma to distinguish between forward and reversed domain names
… which is why I used the historical standard of exclamation points for reversed domain names, rather than introducing ambiguity by re-using the period.
, and reverse them one part at a time:
I do like the way that simplifies the regex, to make it much more understandable and generic, at the expense of making the user click Replace All up to 13 times.
Ugh. You deleted your post while I was replying. It had good information. I am hoping you are going to re-post a slightly rephrased version eventually.
@guy038 said,
So, give me some time to find out the correct regex S/R which could handle and revert up to 13 sections !!
That’s why I just gave the generic format in my original regex, and explained how @Mohammad-Al-Thobiti could extend the idea to as many groups as was desired, because I had a feeling in my reply that the original three-section solution wasn’t going to be enough. Taking my generic formula and just appending copies of the two tokens that I supplied would have worked up to 9 capture groups – and I was hoping that the other regulars here would have let the OP try to learn from the example, rather than spoonfeeding.
And using the
${ℕ}substitution syntax and(?{ℕ}...)conditional replacement instead of$ℕand(?ℕ...)in the replacement would have allowed for ten or more groups. Which is what I would have suggested when the OP came back with the inevitable “but what if I want more groups than 9? when I tried to 13 groups, it didn’t work”. Because my expression didn’t use nesting, it wouldn’t require any fancy thought on the part of the user, just literally copy/pasting more of the same sort of token, and the ability to interpret that they needed to count up with each ℕ in the replacement.But @Coises’ currently-deleted suggestion of just doing a single pair replacement, run many times, would be even simpler to understand than my original suggestion, without the
{ℕ}requirements. So I hope @Coises re-posts that solution once he’s comfortable with the wording, because it’s the best solution for easy extending to as many domain pieces as needed. -
@PeterJones said in I would like to group all similar domains, not by alphabet.:
Ugh. You deleted your post while I was replying.
I am sorry about that. It contained a good idea, implemented incorrectly. My “solution” rotated the parts of the domain name rather than reversing them.
I didn’t know about exclamation points being a standard; I’ll use those instead of commas when I figure out how to do this correctly.
I also realized the original poster probably wants domains like
xxx.comandxxx.organdxxx.co.ukto sort together, which adds an extra complexity. -
@Coises said in I would like to group all similar domains, not by alphabet.:
I also realized the original poster probably wants domains like xxx.com and xxx.org and xxx.co.uk to sort together, which adds an extra complexity.
I think your solution, without that, is sufficient for any reasonable need. If the OP desires that complexity, they can take what we’ve already given them and read the documentation that I linked them to, and figure out the next level themselves. (But if you really want to spend your time on that, I’d recommend doing initial searches from
blah.com,blah.co.uk, etc, and turn those intoblah,comandblah,co,uk; then use ! as the machine separator. That way it will sort first by theblah, then by any more specific things above, which would keepblah.comandblah.co.uknear each other) -
Since there are so many levels, and you’re working with a temporary file anyway, we could make this less tricky. At @PeterJones’ suggestion, here we use an exclamation point to distinguish between forward and reversed domain names.
Enter:
Find what :
([^.\s]+)\.([^!\s]+)
Replace with :\2!\1Replace All repeatedly until it says 0 occurrences were replaced, then sort the file.
If you need to change back to normal domain names after the sort, use:
Find what :
([^!\s]+)!([^.\s]+)
Replace with :\2.\1and Replace All repeatedly until it says 0 occurrences were replaced.
The steps above will sort first by the top-level domain (.com, .net, etc.). If you need to have, say,
whatever.comandwhatever.netandwhatever.co.uksort together, then after reversing the domain names, use something like:Find what :
^([a-z]{2}![a-z]{2}|[^!]+)!(\S+)
Replace with :\2 \1and Replace All once before sorting. (This is not guaranteed to be correct for every case of two-letter top level domains, but it should get the common ones right.)
To reverse, after sorting, use:
Find what :
^(\S+) (\S+)
Replace with :\2!\1 -
Hi, @mohammad-al-thobiti, @peterjones, @coises and All,
Ah, ah ah… I’m very happy to announce that I’ve found out a general regex which can handle any number of sections ;-))
So, let’s begin with this simple INPUT text containing from
2to13sections ( one of each ), pasted in a new tab :abc.def abc.def.ghi abc.def.ghi.jkl abc.def.ghi.jkl.mno abc.def.ghi.jkl.mno.pqr abc.def.ghi.jkl.mno.pqr.stu abc.def.ghi.jkl.mno.pqr.stu.vwx abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0 abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123 abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456 abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789 abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789.€±¶ abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789.€±¶.Ø÷ß- Move to the very beginning of the file (
Ctrl + Home)
First, we add the
|.string at the beginning of every line, with the following regex S/R :-
SEARCH
(?x-s) ^ (?= . ) -
REPLACE
|.
Thus, we get :
|.abc.def |.abc.def.ghi |.abc.def.ghi.jkl |.abc.def.ghi.jkl.mno |.abc.def.ghi.jkl.mno.pqr |.abc.def.ghi.jkl.mno.pqr.stu |.abc.def.ghi.jkl.mno.pqr.stu.vwx |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0 |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123 |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456 |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789 |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789.€±¶ |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789.€±¶.Ø÷ß- Move to the very beginning of the file (
Ctrl + Home)
Now, this is the main regex S/R :
-
SEARCH
(?x-s) ^ ( .* \| ) ( (?: \. (?: (?! \| ) \S )+ )+ ) ( \. (?: (?! \. ) \S )+ ) -
REPLACE
\1\3|\2 -
Click
14thtimes on theReplace Allbutton, till you get the messageReplace All: 0 occurrences were replaced from caret to end-of-file
=> You should get the temporary text :
|.def|.abc |.ghi|.def|.abc |.jkl|.ghi|.def|.abc |.mno|.jkl|.ghi|.def|.abc |.pqr|.mno|.jkl|.ghi|.def|.abc |.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.123|.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.456|.123|.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.789|.456|.123|.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.€±¶|.789|.456|.123|.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.Ø÷ß|.€±¶|.789|.456|.123|.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc- Move to the very beginning of the file (
Ctrl + Home)
Now, we just to get rid of all the
|chars as well as the FIRST dot of each line, with the regex S/R :SEARCH
(?x) ^ \| \. | \|REPLACE
Leave EMPTYAnd we get our expected OUTPUT text :
def.abc ghi.def.abc jkl.ghi.def.abc mno.jkl.ghi.def.abc pqr.mno.jkl.ghi.def.abc stu.pqr.mno.jkl.ghi.def.abc vwx.stu.pqr.mno.jkl.ghi.def.abc yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc 123.yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc 456.123.yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc 789.456.123.yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc €±¶.789.456.123.yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc Ø÷ß.€±¶.789.456.123.yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc
So, @mohammad-al-thobiti :
-
Apply all the above steps against your real file
-
Run the
Edit > Line Operations > Sort Lines Lexicographically Ascendingoption ( No [rectangular] selection is needed as you just keep the addresses ) -
Possibly, add back the
127.0.0.1IPV4 address, followed with twospacechars with the regex S/R :-
SEARCH
(?x-s) ^ (?= . ) -
REPLACE
(127.0.0.1 )
-
Best Regards,
guy038
P.S. :
I’ve just seen the @coises’s solution. I’m going to have a look at its solution which could be more simple than my regex solution !
- Move to the very beginning of the file (
-
Hi, @mohammad-al-thobiti, @peterjones, @coises and All,
@mohammad-al-thobiti, you should use the @coises’s approach, which works much better than mine !!
In addition, in my previous post, I omitted to add the reverse regex to use, once your sort would be done :-((
While the @coise’s method avoids any additional S/R and correctly mentions the reverse regex to run after the sort operation
Note that I slightly Modified the first two @coises’s regexes to get more rigorous ones ( See, at the end of this post the reason for these changes )
Thus, I would propose this road map :
-
First, from the @coises’s post, I would use this alternate regex formulation :
-
SEARCH
(?x) ( [^.\r\n]+ ) \. ( [^!\r\n]+ ) -
REPLACE
\2!\1 -
Click
14thtimes on theReplace Allbutton
-
-
Run the
Edit > Line Operations > Sort Lines Lexicographically Ascendingoption ( No [rectangular] selection is needed as you just keep the addresses ) -
Thirdly, once the sort done, from the @coises’s post, use the alternate reverse regex S/R :
-
SEARCH
(?x) ( [^!\r\n]+ ) ! ( [^.\r\n]+ ) -
REPLACE
\2.\1 -
Click
14thtimes on theReplace Allbutton
-
=> You should get all your addresses back, in the right order
Best Regards,
guy038
P.S. :
@coises uses the
\sclass of characters, which is equivalent to any of the25characters, below, with the regex :(?x) \t | \n | \x{000B} | \x{000C} | \r | \x{0020} | \x{0085} | \x{00A0} | x{1680} | [\x{2000}-\x{200B}] |\x{2028} | \x{2029} | \x{202F} | \x{3000}In the highly unlikely event that one of these characters is included in some addresses, I preferred to use the
[\r\n]regex, which ONLY avoids these 2EOLchars in addresses, instead of using the\sregex ! -
-
Thank you for your efforts, my friends.
I would like to tell you that the result is excellent.
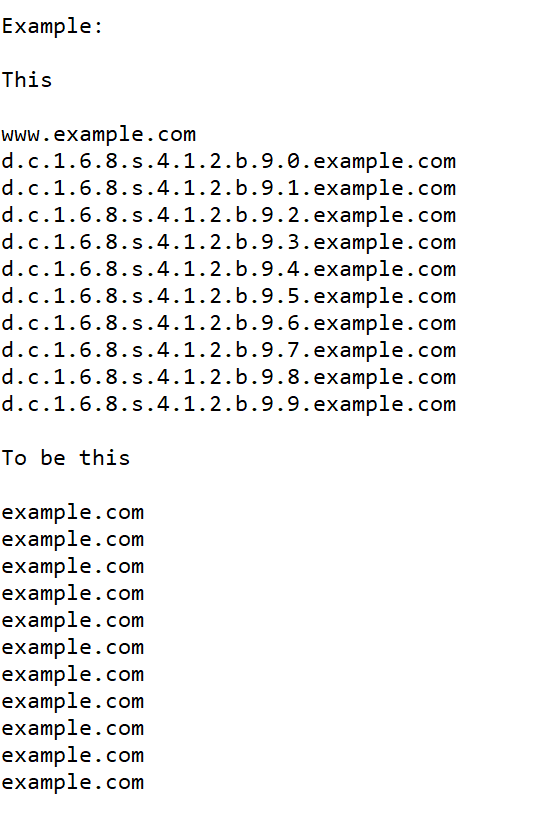
But an idea came to me: why not just delete the subdomain and keep only the main domain and then delete the similar ones?
Is there a way to delete long link extensions? And keep the main domain?Example:
-
-
Hi, @mohammad-al-thobiti and All,
May I rephrase your question ? Let’s see if we mean the same goal !
So, for example, from the INPUT text, below :
abc.def.ghi.jkl.example.com all.net abc.def.example.com abc.my_site.com abc.def.ghi.all.net my_site.com abc.def.all.net abc.def.ghi.jkl.mno.opq.my_site.com example.comWith the following regex S/R :
SEARCH
(?x) ^ (?: [\w-]+ \. )* ( [\w-]+ \. [\w-]+ ) $REPLACE
\1We would get that text :
example.com all.net example.com my_site.com all.net my_site.com all.net my_site.com example.comThen, using the
Edit > Line Operations > Remove Duplicates Linesoption, we would end up with this OUTPUT :example.com all.net my_site.comIf this is exactly what you expect to, just go ahead !
BR
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login