Efficiently select/copy bookmarked lines and their collapsed contents altogether?
-
I have bunch of sections and collapsed contents (ie. .ini format) shown.
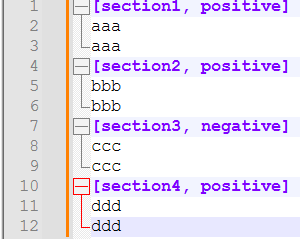
I’ve identified the keyword of interest (ie. “positive” in this case) by Bookmark line" & “Mark All”) and would like to select/copy both the bookmarked lines and their content collapsed in the bookmarked lines (ie. line 1-3, 4-6, 10-12).

How can I select/copy both bookmarked and collapsed lines within more efficiently, without actually unfolding, for example, the section 1 to select line 2-3?
I’ve hovered Ctrl + mouse manually from the beginning of the bookmarker lines of interest for line selection. Can Notepad++ select/copy the lines in the bookmarked/collapsed easily?
Thanks for comments.
-
So, the following has nothing to do with bookmarks at all…
But if you put your caret at the beginning of line 4 and press Shift + DownArrow, line 4 will appear selected and your caret will be at the start of line 7. If you then press Ctrl+c, the text copied will include lines 4, 5 and 6.
If you’re looking for more “advanced” functionality than that, you’re out of luck.
-
@Fermi If your data closely matches the layout that you showin your screen shots then try this:
Step 1 - add one line at the bottom of the file that has
[section999, end]The exact details of that line do not matter other than we want the
[section999part.Step 2 - Do a Mark-all using this regular expression
^(\[section[0-9]+, positive\]\R(?:(?!\[section[0-9]+).+\R)*)+If you experiment with searching using that expression you will find that it matches blocks of consecutive
positivesections. The reason for the[section999, end]line is to deal with if the last section ispositiveand there is stuff after that section that you don’t want.If you don’t have stuff in the file after the last section then you don’t need the
[section999, end]line.If you have blank lines in your sections then change the
(?!\[section[0-9]+).+part to(?!\[section[0-9]+).*As it is, if you have no blank lines then you can use.+and instead of an[section999, end]line you can add one blank line.Step 3 - Do a mark-all and then Copy-all-marked lines.
That will load all of the
positivesections into the copy/ paste buffer in one shot.Here’s the breakdown of what’s happening in
^(\[section[0-9]+, positive\]\R(?:(?!\[section[0-9]+).+\R)*)+- The outer
^(…)+parentheses allow for consectitive positive blocks. This is optional as we are doing a mark-all Having this makes a plain search to see what it makes make more sense. - The
\[section[0-9]+, positive\]\Rpart matches the start of apositivesection. - Right after that is
(?:(?!\[section[0-9]+).*\R)*which matches zero or more lines within a section with the end of the match being the start of the next section. Essentially, I’m matching all lines that do not start with\[section[0-9]+. If your data includes lines that start with something line[section999then you may need to expand that part of the regexp.
- The outer
-
This post is deleted! -
@Fermi said in Efficiently select/copy bookmarked lines and their collapsed contents altogether?:
I guess I’ve over-simplified the problem earlier. I’m having something more general like: [long_random_stringx_sectiony, positive, long_random_stringy] as the section header.
Please take a look at FAQ: Request for Help without sufficient information to help you. I think that will help you ask a question here where the answers you get will be useful or helpful to you.
-
@mkupper
In a generic form (.ini), I want to select the header and its contents, where the header/comment before/after the keyword (ie. positive) are unique.[unique_header1]; positive, unique_comment1 aaa ... [unique_header2]; negative, unique_comment2 bbb ... [unique_header3]; positive, unique_comment3 ccc ... [unique_headerz]; positive, unique_commentz zzz ...What modification should I have to the regex? Thanks.
-
@Fermi said in Efficiently select/copy bookmarked lines and their collapsed contents altogether?:
In a generic form (.ini), I want to select the header and its contents, where the header/comment before/after the keyword (ie. positive) are unique.
Ideally, regular expressions are constructed to match only the data you want it to match and will not match anything else. You don’t want false positives nor false negatives.
As you seem unwilling or unable to provide examples of the data you are attempting to match any help we provide here will also need to be generic or vague. To complicate things, you also seem to be shifting the goalposts of what a section header looks like.
I decided to define a section header as a line that starts with a
[and that anything else is not a section header line. With that in mind, here is a rather general regular expression that will match thepositivesections:(?-i)^\[.*[,;] *positive,.*\R(?:(?!\[).*\R)*That expression has two main parts
(?-i)^\[.*[,;] *positive,.*\Rmatches the section header lines we are interested in.(?:(?!\[).*\R)*matches zero or more lines that are not section header lines.
Reading the
(?-i)^\[.*[,;] *positive,.*\Rpart from left to right we have:(?-i)Turns off the ignore-case option so that we only match a lower casepositive. If your data includes things such asPositiveorPOSITIVEthen you should use(?i)instead of(?-i).^matches the start of a line,\[matches a[. We need the\as[s have a special meaning within regular expressions. Using\[says to look for a normal[..*matches zero to any number of characters.[,;]matches either a comma or semicolon. When you first posted you had commas and now you have semicolons. That’s fine, we can handle either or both and so I went with both.*matches zero to any number of spaces between the[,;]and thepositive.positive,matches the wordpositivefollowed by a comma..*matches zero to any number of characters. This will run to the end of the line.\Rmatches the end of line characters themselves.
The second part with
(?:(?!\[).*\R)*is slightly convoluted as I also want to match empty or blank lines and to include those in the section.- The
(?:and)*outer parentheses and their decoration says to repeat the stuff that’s inside zero or more times. (?!\[).*\Ris the inner part and it matches any line that does not start with a[.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login