RegEx help needed
-
Hello, I need help with a RegEx.
I have to do a translation in a source text that is in the following place after [text “:”] and ends with ".
Here is an example:"English_pd_pTag_1":"","English_pd_comSize_1":2,"English_pd_sprite_1":"","English_pd_1_com_0text":"Look in her phone.","English_pd_1_com_0audio":"","English_pd_1_com_0sprite":"", "English_pd_1_com_1text":"Na, I shouldn't, I'll give it back to her.","English_pd_1_com_1audio":"","English_pd_1_com_1sprite":"", "English_pd_pTag_2":"","English_pd_comSize_2":2,"English_pd_sprite_2":"","English_pd_2_com_0text":"Okay, just in case, I'll send it to my phone and delete the message.","English_pd_2_com_0audio":"","English_pd_2_com_0sprite":"", "English_pd_2_com_1text":"Do nothing, and give it back to her.","English_pd_2_com_1audio":"","English_pd_2_com_1sprite":"", "English_pd_pTag_3":"","English_pd_comSize_3":2,"English_pd_sprite_3":"","English_pd_3_com_0text":"Look inside the box!", "English_pd_3_com_0audio":"","English_pd_3_com_0sprite":"","English_pd_3_com_1text":"This could be some Se7en shit, better not look.", "English_pd_3_com_1audio":"","English_pd_3_com_1sprite":"","English_pd_pTag_4":"","English_pd_comSize_4":2,"English_pd_sprite_4":"","English_pd_4_com_0text":"A batch of money, like$100 (you miss a scene)","English_pd_4_com_0audio":"","English_pd_4_com_0sprite":"","English_pd_4_com_1text":"Can I drink a little bit of it?","English_pd_4_com_1audio":"","English_pd_4_com_1sprite":"", "English_pd_pTag_5":"Mom","English_pd_comSize_5":1,"English_pd_sprite_5":"","English_pd_5_com_0text":"Hello, my handsome knight! ","English_pd_5_com_0audio":"","English_pd_5_com_0sprite":"", "English_pd_pTag_6":"Mom","English_pd_comSize_6":1,"English_pd_sprite_6":"","English_pd_6_com_0text":"You can, actually! I've been searching the internet for lovotion but it's sold out everywhere!","English_pd_6_com_0audio":"","English_pd_6_com_0sprite":"", "English_pd_pTag_7":"Me","English_pd_comSize_7":1,"English_pd_sprite_7":"","English_pd_7_com_0text":"Ah? What's that?","English_pd_7_com_0audio":"","English_pd_7_com_0sprite":"",Only the text between the quotation marks after the string “text”. " to the next " should be marked.
I have a printout that does this, but not always …
[\ D] [^ _] [^: "] \ s [a-z, A-Z, 0-9,., ', $, (,),!,?,] {1,}Here’s an example:
Lines 2, 9 and 10 are marked correctly.
Some characters are not marked in lines 1, 3, 5, 6 and 8
and in line 4 too much is marked and finally in line 7 once too much (first hit of two) - and once correctly (second hit in the same line).
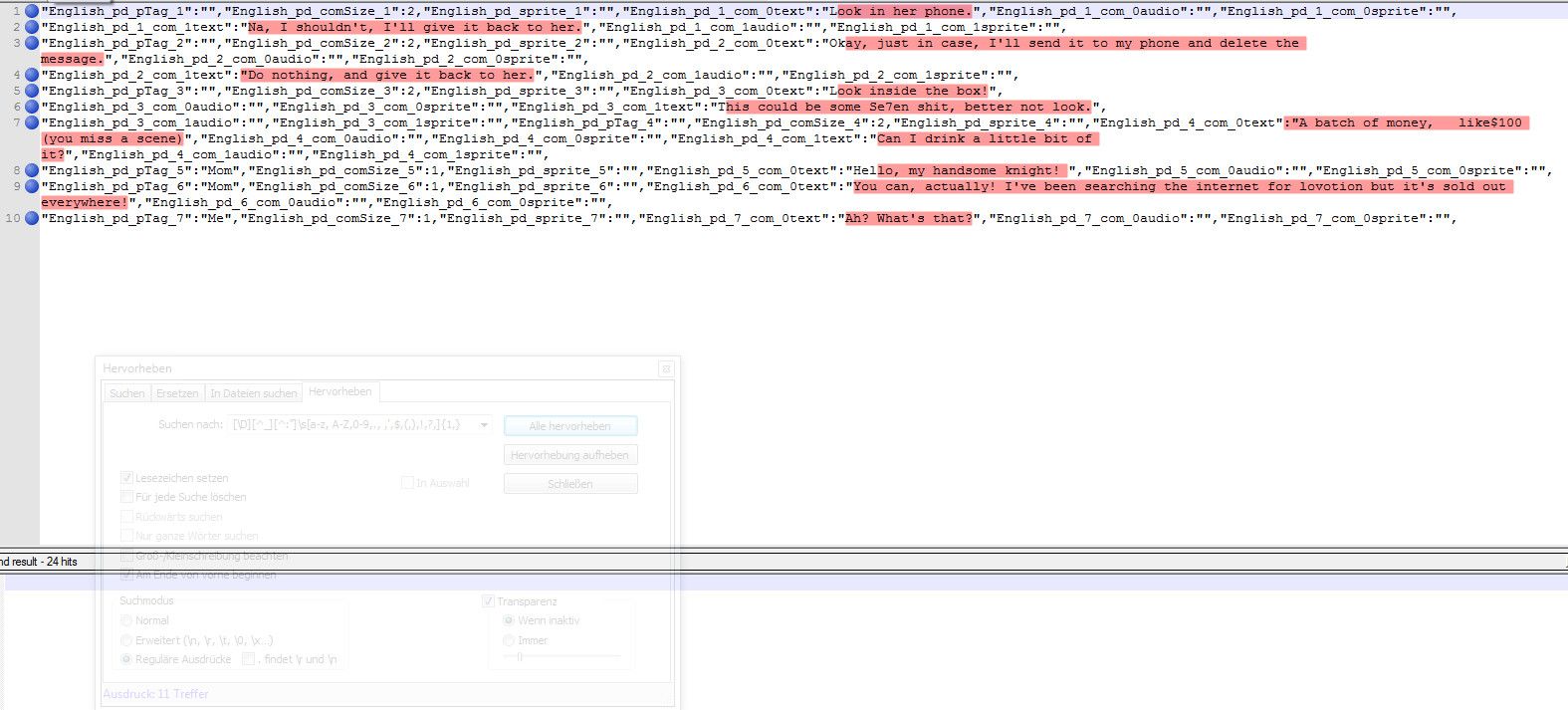
I hope I have not expressed myself too incomprehensibly and someone can help me with this problem …
-
-
In order to localize such lines, I would do all the formatting in one column (this will be more readable)
After localization, combined all the lines (as it was originally) -
@Alan-Kilborn said in RegEx help needed:
(?-is)text":“\K.+?(?=”)
Oh wow!
It works!
Many, many thanks and a Merry Christmas time!I have a question about the \ K. +? flag …
If they were kind enough to explain it briefly so that I can understand it better.
I had already found a partial solution myself, but in the end it was “.” selected with.
(? <= Text “:”) \ D * (") -
\Kis kind of a “start again” flag. What comes to the left has to match, but it isn’t part of the match. The matched text is only what appears to the right of the final\Kin an expression.I’m not sure what to make of your expression, except to say that “You tried!” :-)
The oddest part of your expression might be
\Dwhich means “match anything except a digit”.We have more info about regular expressions by following this link:
https://community.notepad-plus-plus.org/topic/15765/faq-desk-where-to-find-regex-documentation -
@Alan-Kilborn said in RegEx help needed:
I’m not sure what to make of your expression, except to say that “You tried!” :-)
I try to learn and understand what I’m doing … ;-)
The oddest part of your expression might be
\Dwhich means “match anything except a digit”.I read that “\ D” stands for letters …
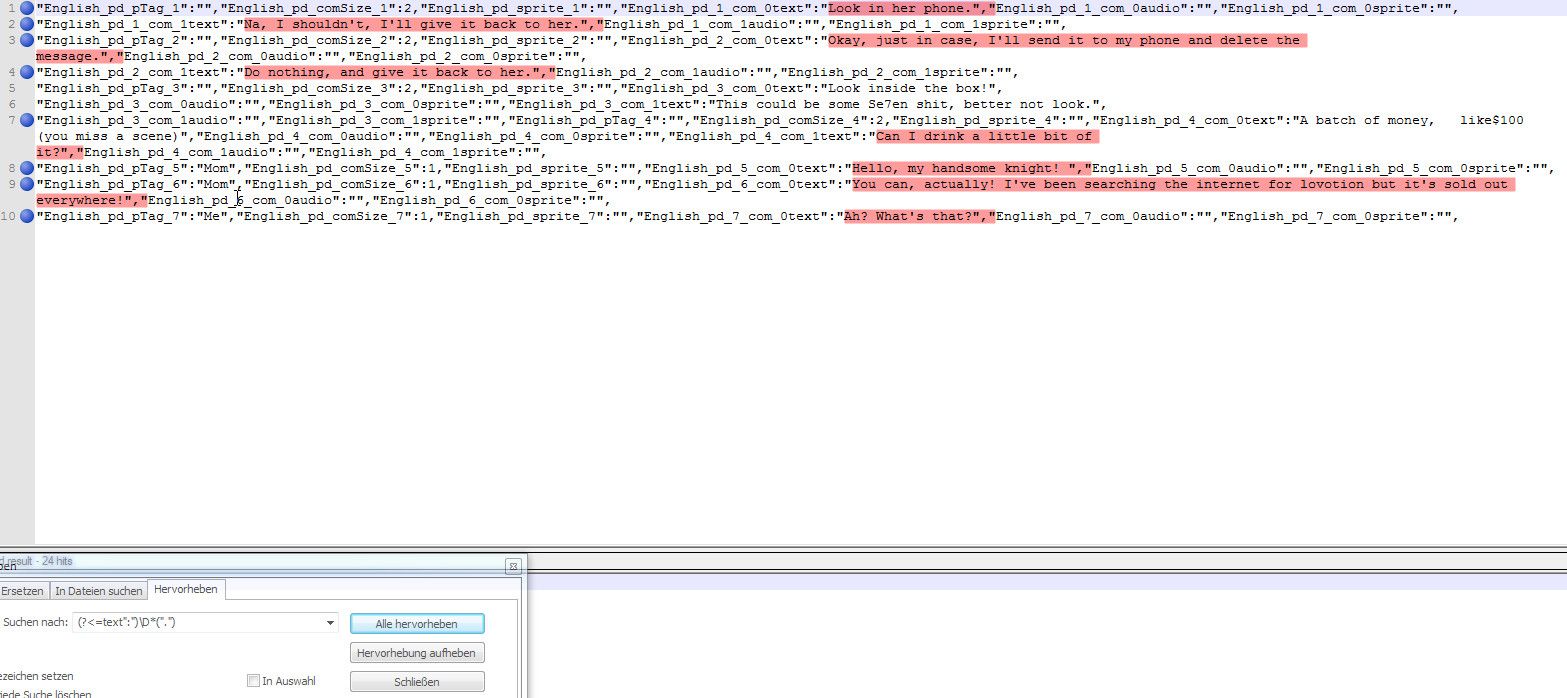
With the flag \ D, I got this output:
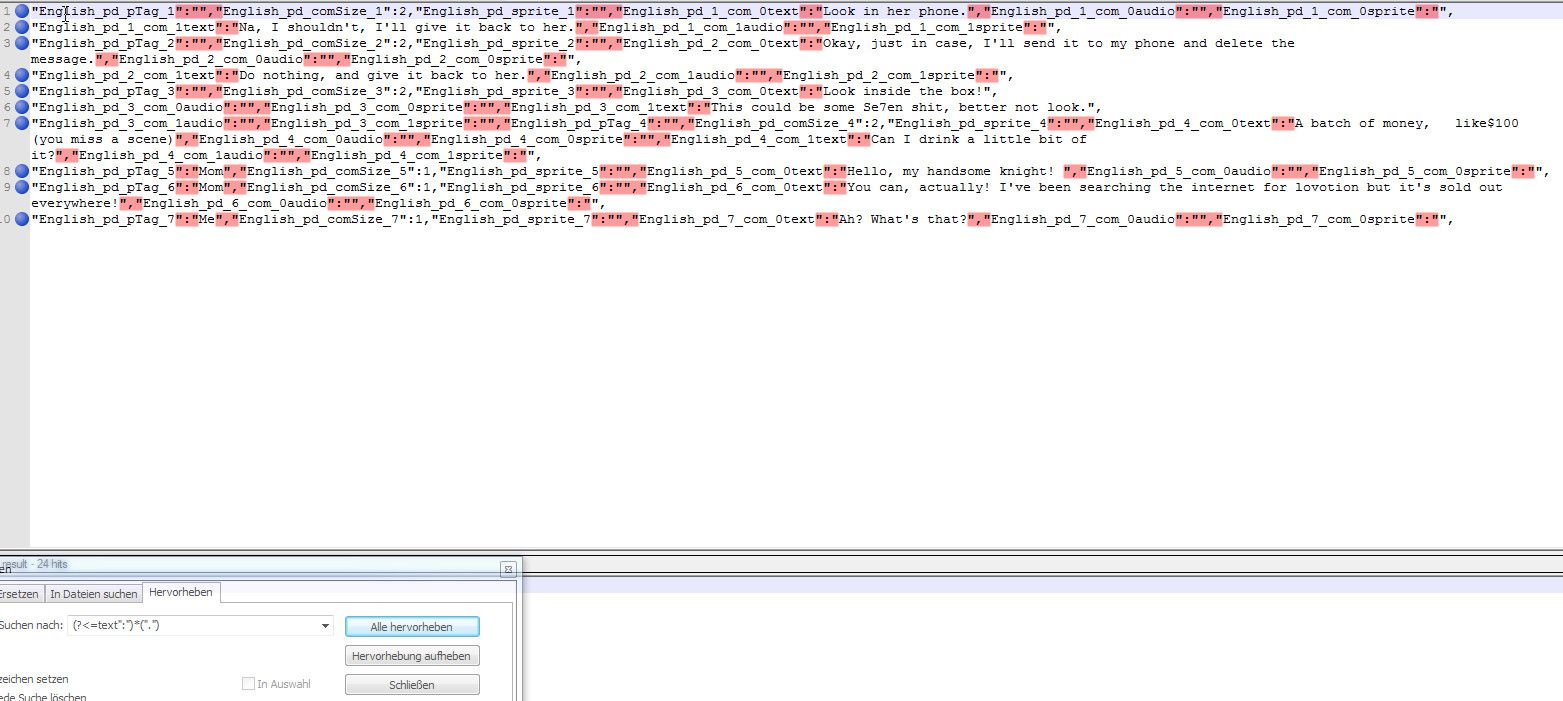
Without \ D only this:
-
I read that “\ D” stands for letters
No
\Dstands for a non-digit.\dstands for a digit, and is the same as[0-9]. Thus\Dwould match anything but0123456789. -
Hello, @hans-dampf, @Alan-kilborn @andrecool-68 and All,
@hans-dampf, I strongly advice you to study the regexes’s world , beginning with the excellent tutorial of the Regular-Expressions.info site, below :
https://www.regular-expressions.info/tutorialcnt.html
It will certainly take you a few weeks to get an overview of the syntax of regular expressions, but it’s really worth it. ;-))
If you are in a hurry, see this part :
https://www.regular-expressions.info/shorthand.html
Moreover, regarding your second regex construction
(?<=text":")*(","), this syntax seems incorrect as the quantifier*, meaningrepeated 0 or more timesshould be, either, preceded with a character, likes*, an expression embedded with parentheses like(123)*, a character class, like[abc]*or a shorthand class, like\h*. But, it should not follow a look-behind construction !However, I was really surprised that our Boost regex engine does not consider it as invalid !?
To explain this behavior, let us, first, consider the simple regex
(?<=abc)defwhich searches for the string def only if preceded with the string abc. If you add the same look-behind, giving the regex(?<=abc)(?<=abc)defit will do the same search, because look-arounds are just zero-length assertions and because they both refer about the same condition !You could add as many identical look-behind to get the same result ( For instance
(?<=abc)(?<=abc)(?<=abc)(?<=abc)(?<=abc)defwould match any string def, if preceded with the string abc ! )Indeed, the
*, right after the look-behind, is taken as a real quantifier. As consecutive values are useless, the unique interesting case seems to be(?<=abc)?defwhich would search for the string def OR for the string def only if preceded with the string abc. Of course, due to Boole algebra, this regex could just be simplified as the search ofdef;-))To be convinced you of that fact, consider the text, below :
1 "," 2 text":""," 3 ABCD":"","-
The regexes
","or(?<=text":")*","or(?<=text":")?","would find the string",", in the three lines -
The regexes
(?<=text":")","or(?<=text":")+","or(?<=text":"){1}","or(?<=text":"){10}","would find the string","in line2only
Best Regards,
guy038
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login