Filter the data !!!
-
I think something is being missed here. First, should we truly be helping out the OP when we suspect we might only be aiding evil purposes? This is directed more to @guy038 because @astrosofista already acknowledged this.
Second, before it dawned on me (by @PeterJones hitting me over the head with it) that we might have a bad situation brewing, I already gave the answer for anyone that cared to follow it:
- reference the other thread I linked early on, where @guy038 provided the general solution
- use the regex I linked earlier in this thread which even included the capturing groups needed for the eventual (specific) solution!
-
Hello, @fake-trum, @alan-kilborn, @peterjones, @astrosofista and All,
Of course, I gave a solution, but you must admit that my post was quite succinct. As we say in France: the minimum trade union discourse ;-))
I mean that I wanted to express my disapproval and say that @fake-trum should have been more patient to fully examine our solutions, before giving up !
Perhaps it would have been better not to provide a solution at all, given that the PO did not want to get involved any further !
But the power and compactness of the regular expression code prevented me from doing so ;-))) So beautiful !
Cheers,
guy038
-
@Alan-Kilborn said in Filter the data !!!:
hitting me over the head with it
Well, I wasn’t trying to be violent to the regulars. I just saw the signs of hash/password pairs, and I couldn’t tell from the downloaded source code whether it was one of the “has my password been hacked” white-hat sites, or “here’s a list of password hashes for infiltrating poorly-written logins” black-hat-sites. The OP’s response wasn’t overly clarifiying.
Unfortunately, I realized last night while trying to fall asleep what regex I should have responded with, rather than my openly-antagonistic lingual response. It wouldn’t have been a solution to the OP’s question, but it might have helped the OP. See if you can figure out what it does before running it on the example data.
- FIND:
(?s)(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(.)?(\Z)? - REPLACE:
(?1\x{49})(?2\x{20})(?3\x{57})(?4\x{49})(?5\x{4C})(?6\x{4C})(?7\x{20})(?8\x{4E})(?9\x{4F})(?10\x{54})(?11\x{20})(?12\x{42})(?13\x{52})(?14\x{55})(?15\x{54})(?16\x{45})(?17\x{20})(?18\x{46})(?19\x{4F})(?20\x{52})(?21\x{43})(?22\x{45})(?23\x{20})(?24\x{50})(?25\x{41})(?26\x{53})(?27\x{53})(?28\x{57})(?29\x{4F})(?30\x{52})(?31\x{44})(?32\x{53}\x{0D}\x{0A})(?33\x{0D}\x{0A}\x{0D}\x{0A}\x{2D}\x{2D}\x{20}\x{73}\x{69}\x{67}\x{6E}\x{65}\x{64}\x{2C}\x{20}\x{74}\x{68}\x{65}\x{20}\x{65}\x{78}\x{2D}\x{73}\x{63}\x{72}\x{69}\x{70}\x{74}\x{2D}\x{6B}\x{69}\x{64}\x{64}\x{69}\x{65})
- FIND:
-
@PeterJones said in Filter the data !!!:
hitting me over the head with it
Slight language misinterpretation: I meant it more as me “getting hit by a lightening bolt of realization”…after you made it plain what could be going on.
-
Hi @Alan-Kilborn, All
What can I say! @guy038’s solution is very interesting and I don’t blame him for posting it. It’s worthy of analysis - at least I learned something - and I think it’s more geared towards the regulars on the list than to OP. As for my answer, it only describes a solution and is understandable only for those who know regular expressions, so I don’t see anything wrong with it.
To be honest, my first reaction was to suggest the direct selection of the passwords by means of Eko’s PS, something that doesn’t take more than a couple of seconds. However, as OP didn’t seem willing to learn anything and it was necessary to guide her/him to install the plugin and the script, I gave up this approach. But in the meantime I had noticed a different solution than yours, I tried it, it worked correctly, but didn’t publish it for the reasons seen.
Well, enough of this for me.
Now I would like to change the subject of the conversation a little, taking advantage of the fact that there are almost no new posts.
I have noticed that often the length of the regular expressions we are using exceeds by far the extension of the search and replacement fields, making it impossible to display the full expression. This limitation makes it difficult to analyze and understand other people’s expressions and to correct one’s own.
Taking into account that there is still some blank space in the Find window, wouldn’t it be a good idea to implement a line wrapping in the search and replacement fields, so that an expression exceeding 36 characters - the maximum displayable in my configuration - continues on the next line and so on until the expression is complete? Even if a limit is set for each field, say 3 lines, these would still give a better picture of the expression than one limited to a single line.
A bonus to facilitate the analysis and construction of regular expressions would be the implementation of a colored syntax to highligth groups and alternations at a glance - by the way, maybe I am not aware and this is currently feasible, you tell me.
Of course, I am aware that it is uncommon for the average user to run searches that go beyond the current length of the find field, let alone use regular expressions, so these features would not directly benefit most users. However I still find them valuables and I think they would be useful additions to Notepad++. Having made this caveat, I would like to hear your opinions. If these topics have been discussed before, I would appreciate links to those discussions.
Sorry for the long post :)
-
Hi, @astrosofista and All,
Personally, after dragging on the right, with the mouse, the
Finddialog to its maximum, I’m able to type in up to100characters, with the monospaced search font ;-))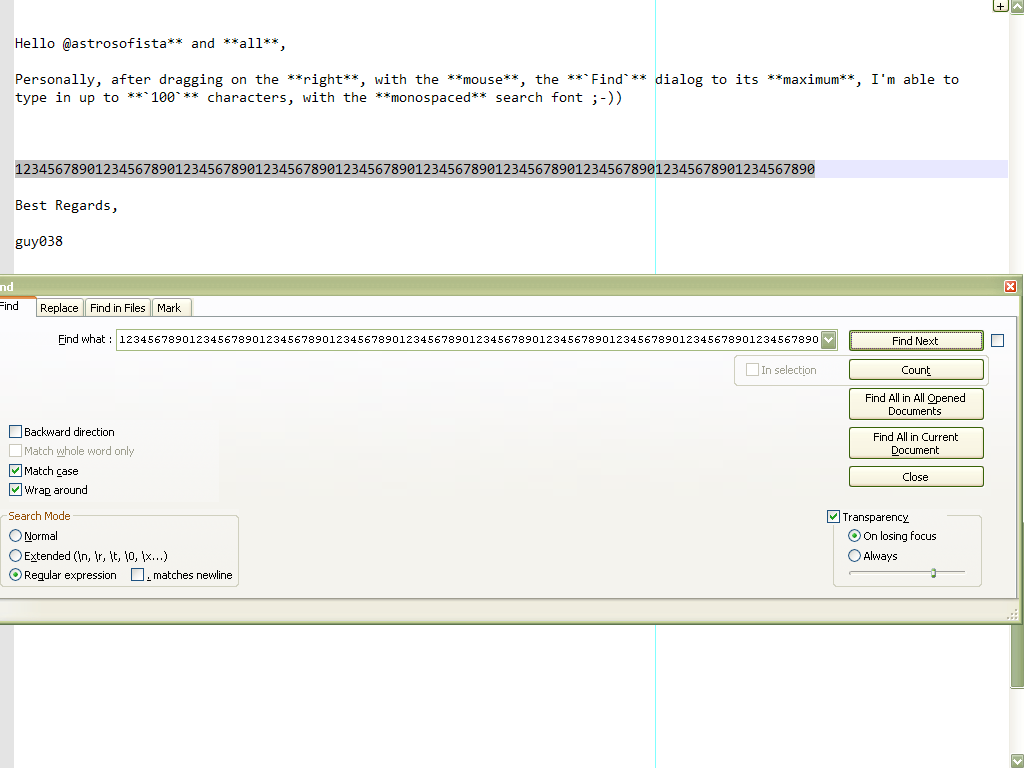
Best Regards,
guy038
-
All,
Personally, I don’t widen the Find window for that purpose, but I often do it so that I can see my entire path in the
Directorybox on the Find in Files tab!@astrosofista The Toolbucket plugin provides multiline Find and Replace boxes, maybe that is to your liking. It’s probably been debated before many times that Notepad++ itself should have bigger boxes for these things, but I can’t cite any references.
-
Hello @peterjones, @alan-kilborn, @Astrosofista,
Oh my God ! This morning, I only realize how stupid and naive I’ve been. So, I was, as they say, completely out of it.
I just concentrated on developing a correct syntax of regular expressions, adapted to the OP problem, when I should have read @Alan-kilborn and @Peterjones previous posts more carefully.
Like them, I do not want my help to be used to cover up questionable work about passwords. Very sorry for my blatant error of judgment :-(( This will serve as a lesson to me !
BR
guy038
-
I understand the desire to see everything and would also welcome
if someone finds a solution, but right now I see two challenges.
If it were multiline search/replace textboxes, then inserting EOLs is possible.
How does Npp know that the inserted EOL should not be part of the search expression or replacement pattern?
If it is a kind of word wrapping, how can we make sure that it is wrapped at a reasonable position to avoid confusion?Personally, I’d prefer that the incremental search
- would be upgraded by regular expressions
- automatically adjusts to the window width
- provides a shortcut to easily switch to the editor and back again
- and, pure optional but really nice to have, a regex-lexer which colors and check my regexes.
-
@Ekopalypse said in Filter the data !!!:
How does Npp know that the inserted EOL should not be part of the search expression or replacement pattern?
If it is a kind of word wrapping, how can we make sure that it is wrapped at a reasonable position to avoid confusion?Very good points.
I’d prefer that the incremental search…
Very good feature requests
However, I don’t think Incremental Search has mass appeal or is used very much in Notepad++.
I have no evidence for this, aside from I don’t recall any questions here about it before.provides a shortcut to easily switch to the editor
I just press
Esc
Not ideal because it closes the window, but it works. -
I just press Esc
That was my workaround too :-)
However, I don’t think Incremental Search has mass appeal or is used very much in Notepad++.
Maybe because of the lacking RE feature - but if it would get it then it would be really cool
as, beside from the normal find dialog, it updates its find location while typing. -
@Ekopalypse said in Filter the data !!!:
Maybe because of the lacking RE feature - but if it would get it then it would be really cool
Since it runs a search at every keystroke, performance problem on huge files?
it updates its find location while typing.
Hmm, thinking of typing
.*into this window and having my caret immediately jump from where I was concentrating on my editing to now be at very end of file. :-) -
Since it runs a search at every keystroke, performance problem on huge files?
… yes but I would argue … don’t do it, use the find dialog instead :-)
my caret immediately jump from where I was concentrating
as this feature doesn’t exist yet it might be that it doesn’t do what you think it will do :-)
But I get your point, that would be, at least, confusing. :-D -
@Ekopalypse said in Filter the data !!!:
as this feature doesn’t exist yet it might be that it doesn’t do what you think it will do
So current implementation sets active selection to text matching incremental search data.
If you return to the editor, your caret is left at the end of the selected text (the end closer to end-of-file).
Default expectation is it would work same way if there was a regex mode.
Thus, my guess is that.*would leave one’s caret at end-of-file with everything above selected.
I supposed it would have to be(?s).*to be entirely correct.
But, yes, I guess Notepad++ devs could change how it logically works (i.e., leave caret at start of selection, closer to original caret pos)? -
@astrosofista said in Filter the data !!!:
implementation of a colored syntax to highligth groups and alternations at a glance - by the way, maybe I am not aware and this is currently feasible
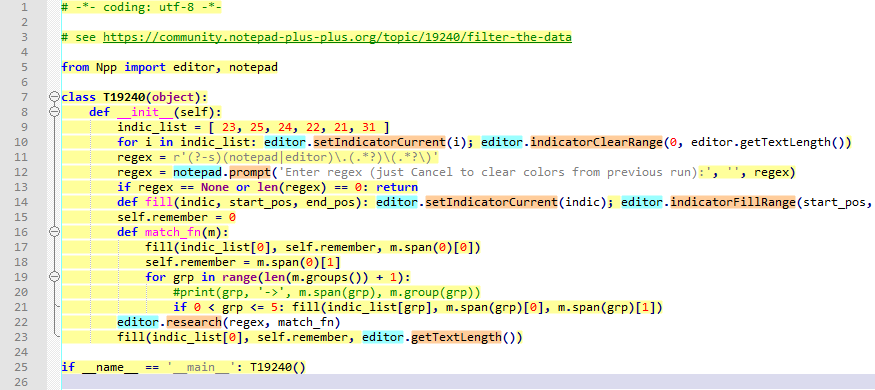
I’m sure not quite what is being asked for, but here’s a curious little Pythonscript.
It takes a regex as its input and then highlights the current file according to the sections of the file that don’t match (yellow), and the overall match (left “uncolored”) and the capturing groups in the regex (group #1 = cyan, group #2 = orange, group #3 = purple, group #4 = dark-green, group #5 = red). Above group #5 I didn’t bother doing.
The reason I left the overall match (group #0) uncolored is that we’d have had overlapping colors that way, and I thought that would have made things less clear.
So if we take the text of the script itself:
# -*- coding: utf-8 -*- # see https://community.notepad-plus-plus.org/topic/19240/filter-the-data from Npp import editor, notepad class T19240(object): def __init__(self): indic_list = [ 23, 25, 24, 22, 21, 31 ] for i in indic_list: editor.setIndicatorCurrent(i); editor.indicatorClearRange(0, editor.getTextLength()) regex = r'(?-s)(notepad|editor)\.(.*?)\(.*?\)' regex = notepad.prompt('Enter regex (just Cancel to clear colors from previous run):', '', regex) if regex == None or len(regex) == 0: return def fill(indic, start_pos, end_pos): editor.setIndicatorCurrent(indic); editor.indicatorFillRange(start_pos, end_pos - start_pos) self.remember = 0 def match_fn(m): fill(indic_list[0], self.remember, m.span(0)[0]) self.remember = m.span(0)[1] for grp in range(len(m.groups()) + 1): #print(grp, '->', m.span(grp), m.group(grp)) if 0 < grp <= 5: fill(indic_list[grp], m.span(grp)[0], m.span(grp)[1]) editor.research(regex, match_fn) fill(indic_list[0], self.remember, editor.getTextLength()) if __name__ == '__main__': T19240()and we run the script on that, and accept the suggested regex, we get:
-
Hello, @alan-kilborn and All,
I tested your Python script : Works nice :-)
I noticed that the
idof styles1to5are in reverse order, giving their names !So :
Mark Style 1 = 25 Mark Style 2 = 24 Mark Style 3 = 23 Mark Style 4 = 22 Mark Style 5 = 21 Find Mark Style = 31I also noted that the first indicator, of the
indic_list, is the color with highlights parts of text which do not match the user regexPersonally, I preferred that this specific color was the
Find Mark style, which allows me to wipe out the color of all non-matched parts, using theClear all marksbutton of theMarkdialog !And to clear the different highlighting groups, I just use the
Remove style > Clear all Stylesoption, of the Context menu !Now, Alan, would it be possible to show the
$0group, with the kind of highlighting, in the picture below :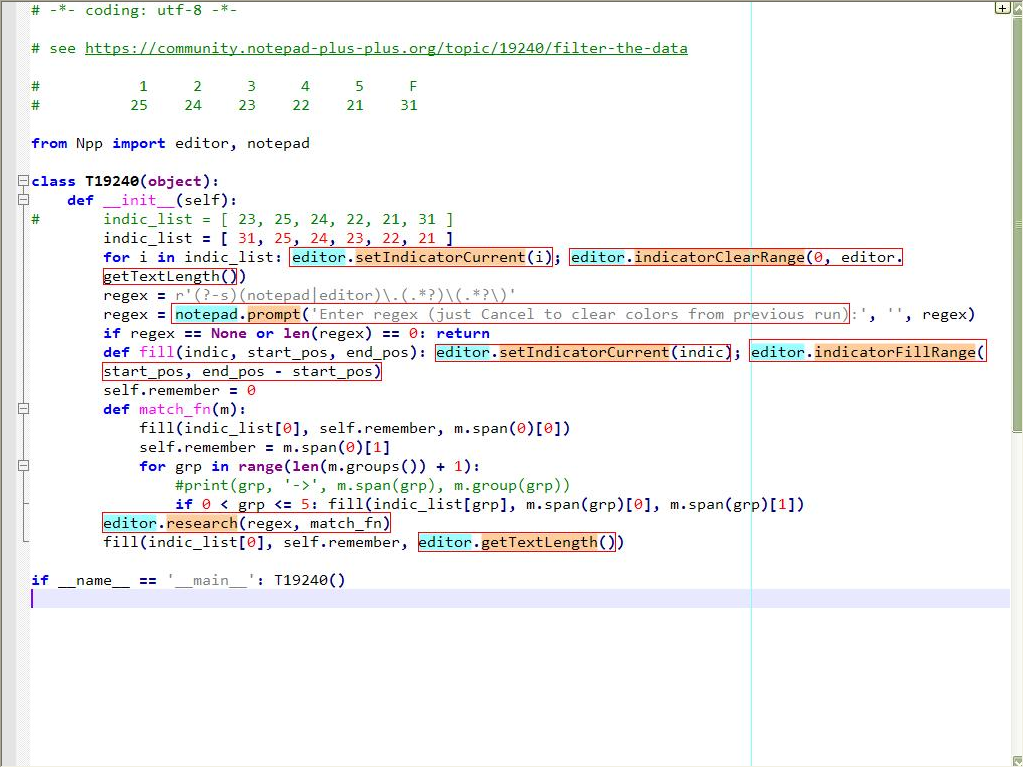
Just a suggestion, of course ! Only if interested and if you get some spare time !
Best Regards,
guy038
P.S. :
I know, I abuse, but would it also be possible to easily modify the border color of that
$0group ? -
@guy038 said in Filter the data !!!:
with the kind of highlighting, in the picture below
Yes! That’s a better idea.
Of course, since you’ve already shown what it looks like, I wonder how you did that; maybe you already wrote the code!? :-) -
It took me a bit to figure out how to do the boxing, but thanks to this OLD THREAD I see how to get it going. Update to be posted soon!
-
Hi, @alan-kilborn and All,
No, sorry, Alan ! I wish I could create such a Python script like that ;-)) I simply used paint.exe and added a red rectangular box around specific zones of a screenshot picture ! Moreover you can notice that, for
2of the$0occurrences which are distributed on two lines, I drew two rectangles whereas, by script, there will be certainly only one zone!I posted this request about the
$0group because I remembered the old post you mentioned in your last post. But I was a bit lazy and I’ve given up to find where it could be, on our forum. However, I was sure it has been created by @scott-sumner or @claudia-frank !Therefore, as a first step, I preferred to omit this precious link. I just assumed you would not have any particular problem with this kind of highlighting ! So, sorry for letting you do this research on your own :-(
Cheers,
guy038
-
Hello everyone. I sincerely thank everyone for supporting me. And this is how I did:
- Because my files are very big, but it’s similar to what I posted so I shortened them with the Plugin Remove Duplicate line
- Next I delete the blank lines and Indent all
- Next remove the first <div><div> with the command: ^<div><div>
- And continue to use the command: <div><div>.* —> Remove the characters after <div><div> and itself.
- And finally use the command: .{90}.+(\R?\N|\n|$) -> Remove lines with more than 90 characters: Such as this line: There is a grandtotal of <span id=“stats_s1” style=“font-weight:bold;”>27,018,552,748</span> user hash requests made to this database, <span id=“stats_s2” style=“font-weight:bold;”>180,510,988</span> are of unique hashes (about <span id=“stats_s3” style=“font-weight:bold;”>0%</span> of grandtotal). Out of the grandtotal number of requests, <span id=“stats_s4” style=“font-weight:bold;”>26,403,484,047</span> were successful or cracked (about <span id=“stats_s5” style=“font-weight:bold;”>97%</span>). Regardingly only unique hashes, <span id=“stats_s6” style=“font-weight:bold;”>144,717,104</span> were successful or cracked (about <span id=“stats_s7” style=“font-weight:bold;”>80%</span>). </p>
Because it is not the same, it is impossible to eliminate duplicate lines. And I have the results I need.