Filter the data !!!
-
All,
Personally, I don’t widen the Find window for that purpose, but I often do it so that I can see my entire path in the
Directorybox on the Find in Files tab!@astrosofista The Toolbucket plugin provides multiline Find and Replace boxes, maybe that is to your liking. It’s probably been debated before many times that Notepad++ itself should have bigger boxes for these things, but I can’t cite any references.
-
Hello @peterjones, @alan-kilborn, @Astrosofista,
Oh my God ! This morning, I only realize how stupid and naive I’ve been. So, I was, as they say, completely out of it.
I just concentrated on developing a correct syntax of regular expressions, adapted to the OP problem, when I should have read @Alan-kilborn and @Peterjones previous posts more carefully.
Like them, I do not want my help to be used to cover up questionable work about passwords. Very sorry for my blatant error of judgment :-(( This will serve as a lesson to me !
BR
guy038
-
I understand the desire to see everything and would also welcome
if someone finds a solution, but right now I see two challenges.
If it were multiline search/replace textboxes, then inserting EOLs is possible.
How does Npp know that the inserted EOL should not be part of the search expression or replacement pattern?
If it is a kind of word wrapping, how can we make sure that it is wrapped at a reasonable position to avoid confusion?Personally, I’d prefer that the incremental search
- would be upgraded by regular expressions
- automatically adjusts to the window width
- provides a shortcut to easily switch to the editor and back again
- and, pure optional but really nice to have, a regex-lexer which colors and check my regexes.
-
@Ekopalypse said in Filter the data !!!:
How does Npp know that the inserted EOL should not be part of the search expression or replacement pattern?
If it is a kind of word wrapping, how can we make sure that it is wrapped at a reasonable position to avoid confusion?Very good points.
I’d prefer that the incremental search…
Very good feature requests
However, I don’t think Incremental Search has mass appeal or is used very much in Notepad++.
I have no evidence for this, aside from I don’t recall any questions here about it before.provides a shortcut to easily switch to the editor
I just press
Esc
Not ideal because it closes the window, but it works. -
I just press Esc
That was my workaround too :-)
However, I don’t think Incremental Search has mass appeal or is used very much in Notepad++.
Maybe because of the lacking RE feature - but if it would get it then it would be really cool
as, beside from the normal find dialog, it updates its find location while typing. -
@Ekopalypse said in Filter the data !!!:
Maybe because of the lacking RE feature - but if it would get it then it would be really cool
Since it runs a search at every keystroke, performance problem on huge files?
it updates its find location while typing.
Hmm, thinking of typing
.*into this window and having my caret immediately jump from where I was concentrating on my editing to now be at very end of file. :-) -
Since it runs a search at every keystroke, performance problem on huge files?
… yes but I would argue … don’t do it, use the find dialog instead :-)
my caret immediately jump from where I was concentrating
as this feature doesn’t exist yet it might be that it doesn’t do what you think it will do :-)
But I get your point, that would be, at least, confusing. :-D -
@Ekopalypse said in Filter the data !!!:
as this feature doesn’t exist yet it might be that it doesn’t do what you think it will do
So current implementation sets active selection to text matching incremental search data.
If you return to the editor, your caret is left at the end of the selected text (the end closer to end-of-file).
Default expectation is it would work same way if there was a regex mode.
Thus, my guess is that.*would leave one’s caret at end-of-file with everything above selected.
I supposed it would have to be(?s).*to be entirely correct.
But, yes, I guess Notepad++ devs could change how it logically works (i.e., leave caret at start of selection, closer to original caret pos)? -
@astrosofista said in Filter the data !!!:
implementation of a colored syntax to highligth groups and alternations at a glance - by the way, maybe I am not aware and this is currently feasible
I’m sure not quite what is being asked for, but here’s a curious little Pythonscript.
It takes a regex as its input and then highlights the current file according to the sections of the file that don’t match (yellow), and the overall match (left “uncolored”) and the capturing groups in the regex (group #1 = cyan, group #2 = orange, group #3 = purple, group #4 = dark-green, group #5 = red). Above group #5 I didn’t bother doing.
The reason I left the overall match (group #0) uncolored is that we’d have had overlapping colors that way, and I thought that would have made things less clear.
So if we take the text of the script itself:
# -*- coding: utf-8 -*- # see https://community.notepad-plus-plus.org/topic/19240/filter-the-data from Npp import editor, notepad class T19240(object): def __init__(self): indic_list = [ 23, 25, 24, 22, 21, 31 ] for i in indic_list: editor.setIndicatorCurrent(i); editor.indicatorClearRange(0, editor.getTextLength()) regex = r'(?-s)(notepad|editor)\.(.*?)\(.*?\)' regex = notepad.prompt('Enter regex (just Cancel to clear colors from previous run):', '', regex) if regex == None or len(regex) == 0: return def fill(indic, start_pos, end_pos): editor.setIndicatorCurrent(indic); editor.indicatorFillRange(start_pos, end_pos - start_pos) self.remember = 0 def match_fn(m): fill(indic_list[0], self.remember, m.span(0)[0]) self.remember = m.span(0)[1] for grp in range(len(m.groups()) + 1): #print(grp, '->', m.span(grp), m.group(grp)) if 0 < grp <= 5: fill(indic_list[grp], m.span(grp)[0], m.span(grp)[1]) editor.research(regex, match_fn) fill(indic_list[0], self.remember, editor.getTextLength()) if __name__ == '__main__': T19240()and we run the script on that, and accept the suggested regex, we get:
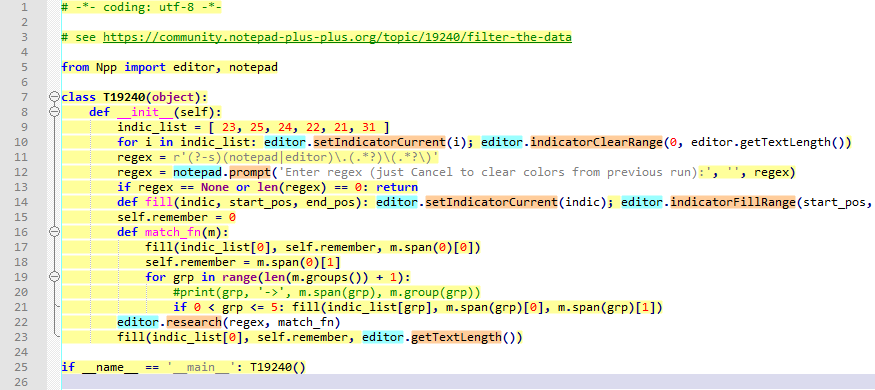
-
Hello, @alan-kilborn and All,
I tested your Python script : Works nice :-)
I noticed that the
idof styles1to5are in reverse order, giving their names !So :
Mark Style 1 = 25 Mark Style 2 = 24 Mark Style 3 = 23 Mark Style 4 = 22 Mark Style 5 = 21 Find Mark Style = 31I also noted that the first indicator, of the
indic_list, is the color with highlights parts of text which do not match the user regexPersonally, I preferred that this specific color was the
Find Mark style, which allows me to wipe out the color of all non-matched parts, using theClear all marksbutton of theMarkdialog !And to clear the different highlighting groups, I just use the
Remove style > Clear all Stylesoption, of the Context menu !Now, Alan, would it be possible to show the
$0group, with the kind of highlighting, in the picture below :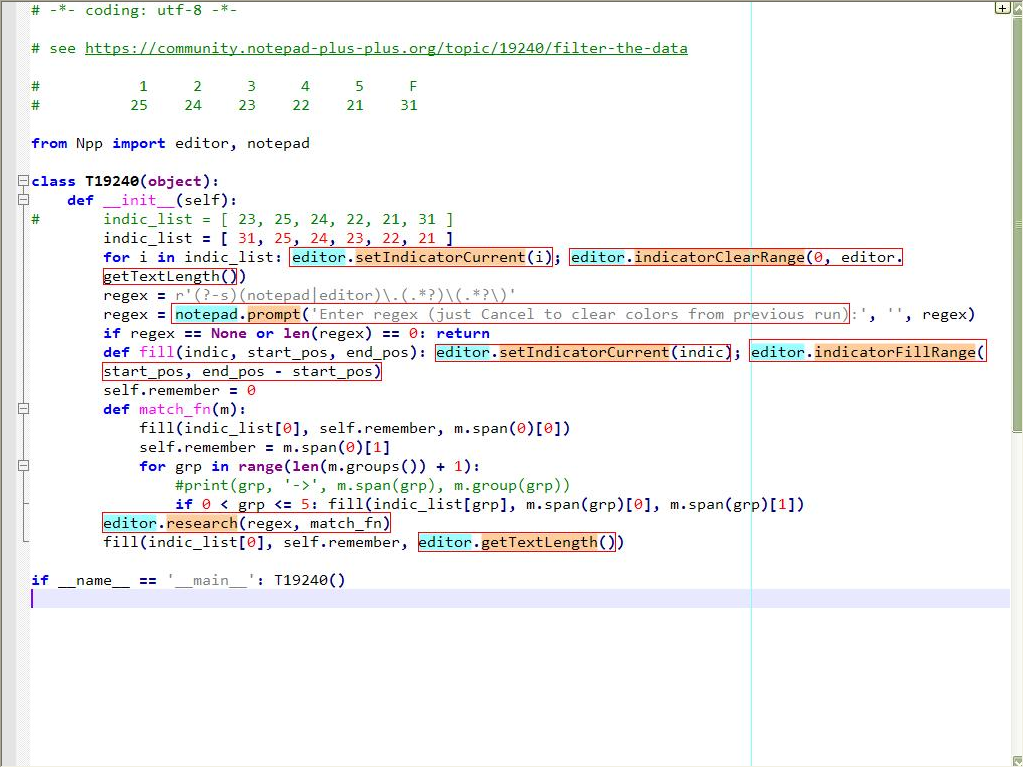
Just a suggestion, of course ! Only if interested and if you get some spare time !
Best Regards,
guy038
P.S. :
I know, I abuse, but would it also be possible to easily modify the border color of that
$0group ? -
@guy038 said in Filter the data !!!:
with the kind of highlighting, in the picture below
Yes! That’s a better idea.
Of course, since you’ve already shown what it looks like, I wonder how you did that; maybe you already wrote the code!? :-) -
It took me a bit to figure out how to do the boxing, but thanks to this OLD THREAD I see how to get it going. Update to be posted soon!
-
Hi, @alan-kilborn and All,
No, sorry, Alan ! I wish I could create such a Python script like that ;-)) I simply used paint.exe and added a red rectangular box around specific zones of a screenshot picture ! Moreover you can notice that, for
2of the$0occurrences which are distributed on two lines, I drew two rectangles whereas, by script, there will be certainly only one zone!I posted this request about the
$0group because I remembered the old post you mentioned in your last post. But I was a bit lazy and I’ve given up to find where it could be, on our forum. However, I was sure it has been created by @scott-sumner or @claudia-frank !Therefore, as a first step, I preferred to omit this precious link. I just assumed you would not have any particular problem with this kind of highlighting ! So, sorry for letting you do this research on your own :-(
Cheers,
guy038
-
Hello everyone. I sincerely thank everyone for supporting me. And this is how I did:
- Because my files are very big, but it’s similar to what I posted so I shortened them with the Plugin Remove Duplicate line
- Next I delete the blank lines and Indent all
- Next remove the first <div><div> with the command: ^<div><div>
- And continue to use the command: <div><div>.* —> Remove the characters after <div><div> and itself.
- And finally use the command: .{90}.+(\R?\N|\n|$) -> Remove lines with more than 90 characters: Such as this line: There is a grandtotal of <span id=“stats_s1” style=“font-weight:bold;”>27,018,552,748</span> user hash requests made to this database, <span id=“stats_s2” style=“font-weight:bold;”>180,510,988</span> are of unique hashes (about <span id=“stats_s3” style=“font-weight:bold;”>0%</span> of grandtotal). Out of the grandtotal number of requests, <span id=“stats_s4” style=“font-weight:bold;”>26,403,484,047</span> were successful or cracked (about <span id=“stats_s5” style=“font-weight:bold;”>97%</span>). Regardingly only unique hashes, <span id=“stats_s6” style=“font-weight:bold;”>144,717,104</span> were successful or cracked (about <span id=“stats_s7” style=“font-weight:bold;”>80%</span>). </p>
Because it is not the same, it is impossible to eliminate duplicate lines. And I have the results I need.
-
Second version of script with desired change (mainly boxing the entire match; doing nothing with non-matching text):
# -*- coding: utf-8 -*- # see https://community.notepad-plus-plus.org/topic/19240/filter-the-data # see https://community.notepad-plus-plus.org/topic/14501/has-a-plugin-like-sublime-plugin-brackethighlighter from Npp import editor, notepad, INDICATORSTYLE class T19240a(object): def __init__(self): free_indicator_to_use = 17 self.indicator_set_options(free_indicator_to_use, INDICATORSTYLE.STRAIGHTBOX, (238,121,159), 0, 255, True) indic_list = [ free_indicator_to_use, 25, 24, 23, 22, 21, 31, 29, 28 ] for i in indic_list: self.clear_all(i) regex = r'(?-s)(notepad|editor)\.(.*?)\(.*?\)' regex = notepad.prompt('Enter regex (just Cancel to clear colors from previous run):', '', regex) if regex == None or len(regex) == 0: return def match_fn(m): for grp in range(len(m.groups()) + 1): #print('{g} -> {s} |{text}|'.format(g=grp, s=m.span(grp), text=m.group(grp))) if grp < len(indic_list): # we only have a finite number of colors but we could have more groups than that if m.span(grp)[0] != m.span(grp)[1]: # don't bother with zero-length groups; or groups not matched: (-1, -1) self.fill(indic_list[grp], m.span(grp)[0], m.span(grp)[1]) editor.research(regex, match_fn) def fill(self, indic, start_pos, end_pos): editor.setIndicatorCurrent(indic) editor.indicatorFillRange(start_pos, end_pos - start_pos) def clear_all(self, indic): editor.setIndicatorCurrent(indic) editor.indicatorClearRange(0, editor.getTextLength()) def indicator_set_options(self, indicator_number, indicator_style, rgb_color_tup, alpha, outline_alpha, draw_under_text): for ed in (editor1, editor2): ed.indicSetStyle(indicator_number, indicator_style) # e.g. INDICATORSTYLE.ROUNDBOX ed.indicSetFore(indicator_number, rgb_color_tup) ed.indicSetAlpha(indicator_number, alpha) # integer ed.indicSetOutlineAlpha(indicator_number, outline_alpha) # integer ed.indicSetUnder(indicator_number, draw_under_text) # boolean if __name__ == '__main__': T19240a()@Fake-Trum Sorry for hijacking your thread a bit.
-
Hello, @alan-kilborn and All,
Many thanks for your second try ;-)) As for me, I preferred to slightly color all the group
0zones ! So I used an alpha transparency of50instead of0Here is a regex which enables the
8possible highlightings :~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ (?x) # Start of Regex # Number group Name of Style Indicator (\l[\l\r\n]+)\h+\d+\h+ # Group 1 Mark Style 1 25 (\l[\l\r\n]+)\h+\d+\h+ # Group 2 Mark Style 2 24 (\l[\l\r\n]+)\h+\d+\h+ # Group 3 Mark Style 3 23 (\l[\l\r\n]+)\h+\d+\h+ # Group 4 Mark Style 4 22 (\l[\l\r\n]+)\h+\d+\h+ # Group 5 Mark Style 5 21 (\l[\l\r\n]+)\h+\d+\h+ # Group 6 Find Mark Style 31 (\l[\l\r\n]+)\h+\d+\h+ # Group 7 Smart Highlighting 29 (\l[\l\r\n]+) # Group 8 Incremental highlight all 28 # End of Regex Color = (240,128,160) , Alpha = 40 , Outline Alpha = 255 , StraightBox Style 17 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~Tested against the text below :
abcde fghij 012345 abcde fghij 012345 abcde fghij 012345 abcde fghij 012345 abcdefg hij 012345 abc defghij 012345 abc defghij 012345 abc defghijIf you click on the
¶button to visualize all characters, it’s great to see that highlighting goes also over theLFandCRchars and that the straight box embeds them, either, when a group containsline-break(s);-))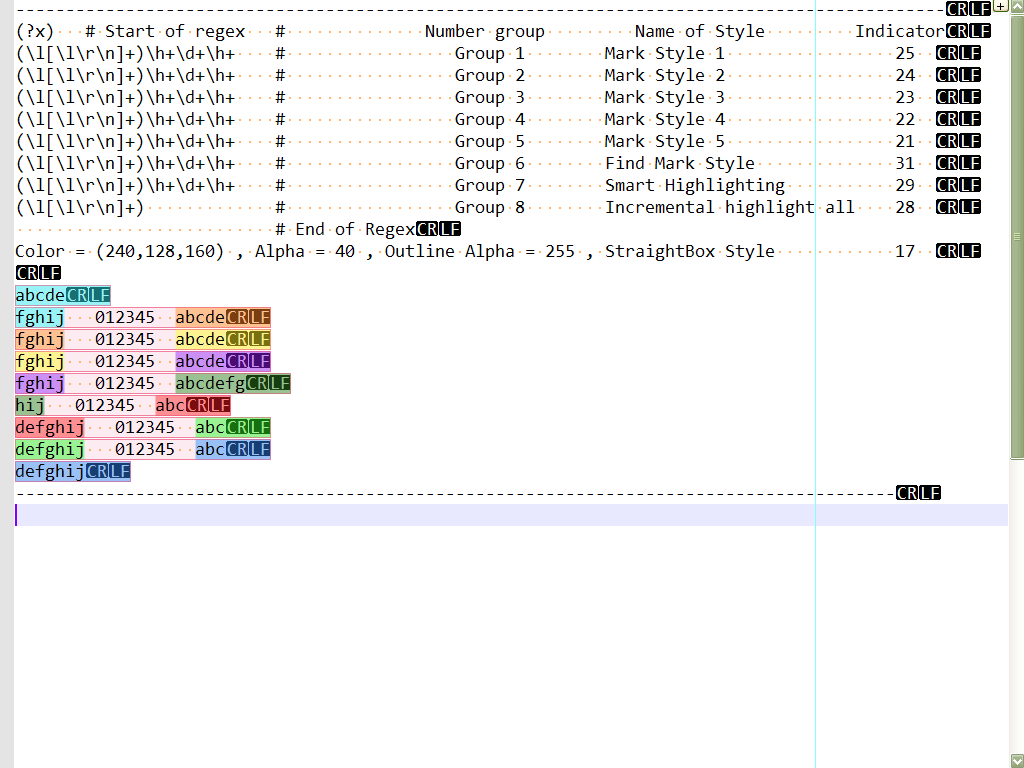
Now, we already have a default regex, with the line
regex = r'.............'But, Allan (and this is my last request, I promise !), could you add the automatic assignment of the current selection to the regex variable ?I mean something like :
If no current main *selection THEN
regex = notepad.prompt...ELSE regex = current selection ( without any dialog )TIA,
Cheers,
guy038
-
@guy038 said in Filter the data !!!:
Alan (and this is my last request, I promise !), could you add the automatic assignment of the current selection to the regex variable ?
Remember, you promised!
Here’s the “b” version:
# -*- coding: utf-8 -*- # see https://community.notepad-plus-plus.org/topic/19240/filter-the-data # see https://community.notepad-plus-plus.org/topic/14501/has-a-plugin-like-sublime-plugin-brackethighlighter from Npp import editor, notepad, INDICATORSTYLE class T19240b(object): def __init__(self): free_indicator_to_use = 17 self.indicator_set_options(free_indicator_to_use, INDICATORSTYLE.STRAIGHTBOX, (240,128,160), 40, 255, True) indic_list = [ free_indicator_to_use, 25, 24, 23, 22, 21, 31, 29, 28 ] for i in indic_list: self.clear_all(i) if editor.getSelectionEmpty(): regex = r'(?-s)(notepad|editor)\.(.*?)\(.*?\)' # a regex just for demo purposes regex = notepad.prompt('Enter regex (just Cancel to clear colors from previous run):', '', regex) else: regex = editor.getSelText() if regex == None or len(regex) == 0: return def match_fn(m): for grp in range(len(m.groups()) + 1): #print('{g} -> {s} |{text}|'.format(g=grp, s=m.span(grp), text=m.group(grp))) if grp < len(indic_list): # we only have a finite number of colors but we could have more groups than that if m.span(grp)[0] != m.span(grp)[1]: # don't bother with zero-length groups; or groups not matched: (-1, -1) self.fill(indic_list[grp], m.span(grp)[0], m.span(grp)[1]) editor.research(regex, match_fn) def fill(self, indic, start_pos, end_pos): editor.setIndicatorCurrent(indic) editor.indicatorFillRange(start_pos, end_pos - start_pos) def clear_all(self, indic): editor.setIndicatorCurrent(indic) editor.indicatorClearRange(0, editor.getTextLength()) def indicator_set_options(self, indicator_number, indicator_style, rgb_color_tup, alpha, outline_alpha, draw_under_text): for ed in (editor1, editor2): ed.indicSetStyle(indicator_number, indicator_style) # e.g. INDICATORSTYLE.ROUNDBOX ed.indicSetFore(indicator_number, rgb_color_tup) ed.indicSetAlpha(indicator_number, alpha) # integer ed.indicSetOutlineAlpha(indicator_number, outline_alpha) # integer ed.indicSetUnder(indicator_number, draw_under_text) # boolean if __name__ == '__main__': T19240b() -
Hi, @Alan-kilborn and All,
Alan, this version is just perfect ! Up to now, when building a complicated search regex, containing some groups, I was used to type in this regex, in the Replace dialog, to clearly see the contents of each group :
REPLACE
\r\n>$1<\r\n>$2<\r\n>$3<\r\n>$4<\r\n>$5<\r\n......>$n<\r\nNow, with your script :
-
Select the regex where you want to notice the different groups, from
1to8, as well as the overall match$0, for each occurrence, in current file -
Execute the last version of your Python script, that I renamed
Groups_Highlighter.py, BTW ;-))
Much more elegant, isn’t it ?
Best Regards
guy038
P.S. : Two more points :
-
Out of curiosity, what means, exactly, the syntax
T19240? -
I tried to change the draw_under_text value from
TruetoFalse. But I did not see any difference ?!
Thanks, again, Alan, for this valuable script :-))
-
-
I renamed Groups_Highlighter.py
I called my copy
ColorizeRegex.pybut to each his own!what means, exactly, the syntax T19240 ?
It’s the topic id of this thread in the forum! :-)
This is a Peter-ism. :-)tried to change the draw_under_text value from True to False. But I did not see any difference ?!
Not sure, it was in the code I stole from the earlier referenced thread, about bracket-highlighting.
I don’t think I fully follow the DOCS about it, either. -
Of course, with this new script, aren’t we somewhat reinventing a four-year-old WHEEL ??
I’m sure Peter will be scanning your tabs in your screenshot HERE looking for interesting things. :-)