Filter the data !!!
-
Hello, @alan-kilborn and All,
I tested your Python script : Works nice :-)
I noticed that the
idof styles1to5are in reverse order, giving their names !So :
Mark Style 1 = 25 Mark Style 2 = 24 Mark Style 3 = 23 Mark Style 4 = 22 Mark Style 5 = 21 Find Mark Style = 31I also noted that the first indicator, of the
indic_list, is the color with highlights parts of text which do not match the user regexPersonally, I preferred that this specific color was the
Find Mark style, which allows me to wipe out the color of all non-matched parts, using theClear all marksbutton of theMarkdialog !And to clear the different highlighting groups, I just use the
Remove style > Clear all Stylesoption, of the Context menu !Now, Alan, would it be possible to show the
$0group, with the kind of highlighting, in the picture below :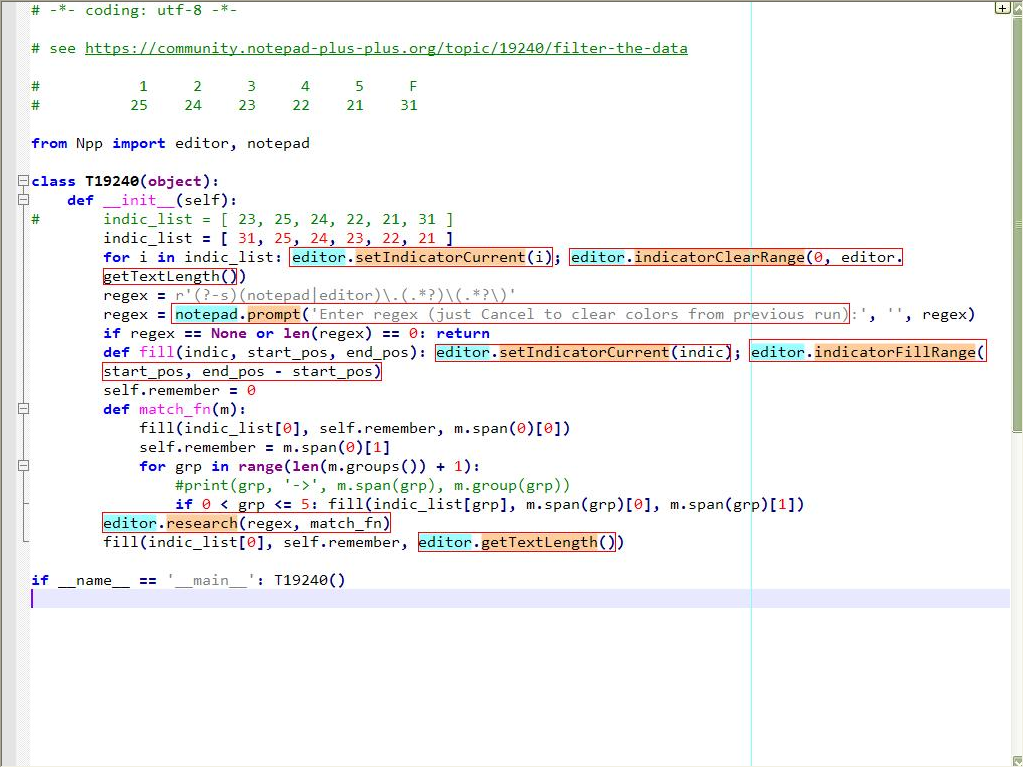
Just a suggestion, of course ! Only if interested and if you get some spare time !
Best Regards,
guy038
P.S. :
I know, I abuse, but would it also be possible to easily modify the border color of that
$0group ? -
@guy038 said in Filter the data !!!:
with the kind of highlighting, in the picture below
Yes! That’s a better idea.
Of course, since you’ve already shown what it looks like, I wonder how you did that; maybe you already wrote the code!? :-) -
It took me a bit to figure out how to do the boxing, but thanks to this OLD THREAD I see how to get it going. Update to be posted soon!
-
Hi, @alan-kilborn and All,
No, sorry, Alan ! I wish I could create such a Python script like that ;-)) I simply used paint.exe and added a red rectangular box around specific zones of a screenshot picture ! Moreover you can notice that, for
2of the$0occurrences which are distributed on two lines, I drew two rectangles whereas, by script, there will be certainly only one zone!I posted this request about the
$0group because I remembered the old post you mentioned in your last post. But I was a bit lazy and I’ve given up to find where it could be, on our forum. However, I was sure it has been created by @scott-sumner or @claudia-frank !Therefore, as a first step, I preferred to omit this precious link. I just assumed you would not have any particular problem with this kind of highlighting ! So, sorry for letting you do this research on your own :-(
Cheers,
guy038
-
Hello everyone. I sincerely thank everyone for supporting me. And this is how I did:
- Because my files are very big, but it’s similar to what I posted so I shortened them with the Plugin Remove Duplicate line
- Next I delete the blank lines and Indent all
- Next remove the first <div><div> with the command: ^<div><div>
- And continue to use the command: <div><div>.* —> Remove the characters after <div><div> and itself.
- And finally use the command: .{90}.+(\R?\N|\n|$) -> Remove lines with more than 90 characters: Such as this line: There is a grandtotal of <span id=“stats_s1” style=“font-weight:bold;”>27,018,552,748</span> user hash requests made to this database, <span id=“stats_s2” style=“font-weight:bold;”>180,510,988</span> are of unique hashes (about <span id=“stats_s3” style=“font-weight:bold;”>0%</span> of grandtotal). Out of the grandtotal number of requests, <span id=“stats_s4” style=“font-weight:bold;”>26,403,484,047</span> were successful or cracked (about <span id=“stats_s5” style=“font-weight:bold;”>97%</span>). Regardingly only unique hashes, <span id=“stats_s6” style=“font-weight:bold;”>144,717,104</span> were successful or cracked (about <span id=“stats_s7” style=“font-weight:bold;”>80%</span>). </p>
Because it is not the same, it is impossible to eliminate duplicate lines. And I have the results I need.
-
Second version of script with desired change (mainly boxing the entire match; doing nothing with non-matching text):
# -*- coding: utf-8 -*- # see https://community.notepad-plus-plus.org/topic/19240/filter-the-data # see https://community.notepad-plus-plus.org/topic/14501/has-a-plugin-like-sublime-plugin-brackethighlighter from Npp import editor, notepad, INDICATORSTYLE class T19240a(object): def __init__(self): free_indicator_to_use = 17 self.indicator_set_options(free_indicator_to_use, INDICATORSTYLE.STRAIGHTBOX, (238,121,159), 0, 255, True) indic_list = [ free_indicator_to_use, 25, 24, 23, 22, 21, 31, 29, 28 ] for i in indic_list: self.clear_all(i) regex = r'(?-s)(notepad|editor)\.(.*?)\(.*?\)' regex = notepad.prompt('Enter regex (just Cancel to clear colors from previous run):', '', regex) if regex == None or len(regex) == 0: return def match_fn(m): for grp in range(len(m.groups()) + 1): #print('{g} -> {s} |{text}|'.format(g=grp, s=m.span(grp), text=m.group(grp))) if grp < len(indic_list): # we only have a finite number of colors but we could have more groups than that if m.span(grp)[0] != m.span(grp)[1]: # don't bother with zero-length groups; or groups not matched: (-1, -1) self.fill(indic_list[grp], m.span(grp)[0], m.span(grp)[1]) editor.research(regex, match_fn) def fill(self, indic, start_pos, end_pos): editor.setIndicatorCurrent(indic) editor.indicatorFillRange(start_pos, end_pos - start_pos) def clear_all(self, indic): editor.setIndicatorCurrent(indic) editor.indicatorClearRange(0, editor.getTextLength()) def indicator_set_options(self, indicator_number, indicator_style, rgb_color_tup, alpha, outline_alpha, draw_under_text): for ed in (editor1, editor2): ed.indicSetStyle(indicator_number, indicator_style) # e.g. INDICATORSTYLE.ROUNDBOX ed.indicSetFore(indicator_number, rgb_color_tup) ed.indicSetAlpha(indicator_number, alpha) # integer ed.indicSetOutlineAlpha(indicator_number, outline_alpha) # integer ed.indicSetUnder(indicator_number, draw_under_text) # boolean if __name__ == '__main__': T19240a()@Fake-Trum Sorry for hijacking your thread a bit.
-
Hello, @alan-kilborn and All,
Many thanks for your second try ;-)) As for me, I preferred to slightly color all the group
0zones ! So I used an alpha transparency of50instead of0Here is a regex which enables the
8possible highlightings :~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ (?x) # Start of Regex # Number group Name of Style Indicator (\l[\l\r\n]+)\h+\d+\h+ # Group 1 Mark Style 1 25 (\l[\l\r\n]+)\h+\d+\h+ # Group 2 Mark Style 2 24 (\l[\l\r\n]+)\h+\d+\h+ # Group 3 Mark Style 3 23 (\l[\l\r\n]+)\h+\d+\h+ # Group 4 Mark Style 4 22 (\l[\l\r\n]+)\h+\d+\h+ # Group 5 Mark Style 5 21 (\l[\l\r\n]+)\h+\d+\h+ # Group 6 Find Mark Style 31 (\l[\l\r\n]+)\h+\d+\h+ # Group 7 Smart Highlighting 29 (\l[\l\r\n]+) # Group 8 Incremental highlight all 28 # End of Regex Color = (240,128,160) , Alpha = 40 , Outline Alpha = 255 , StraightBox Style 17 ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~Tested against the text below :
abcde fghij 012345 abcde fghij 012345 abcde fghij 012345 abcde fghij 012345 abcdefg hij 012345 abc defghij 012345 abc defghij 012345 abc defghijIf you click on the
¶button to visualize all characters, it’s great to see that highlighting goes also over theLFandCRchars and that the straight box embeds them, either, when a group containsline-break(s);-))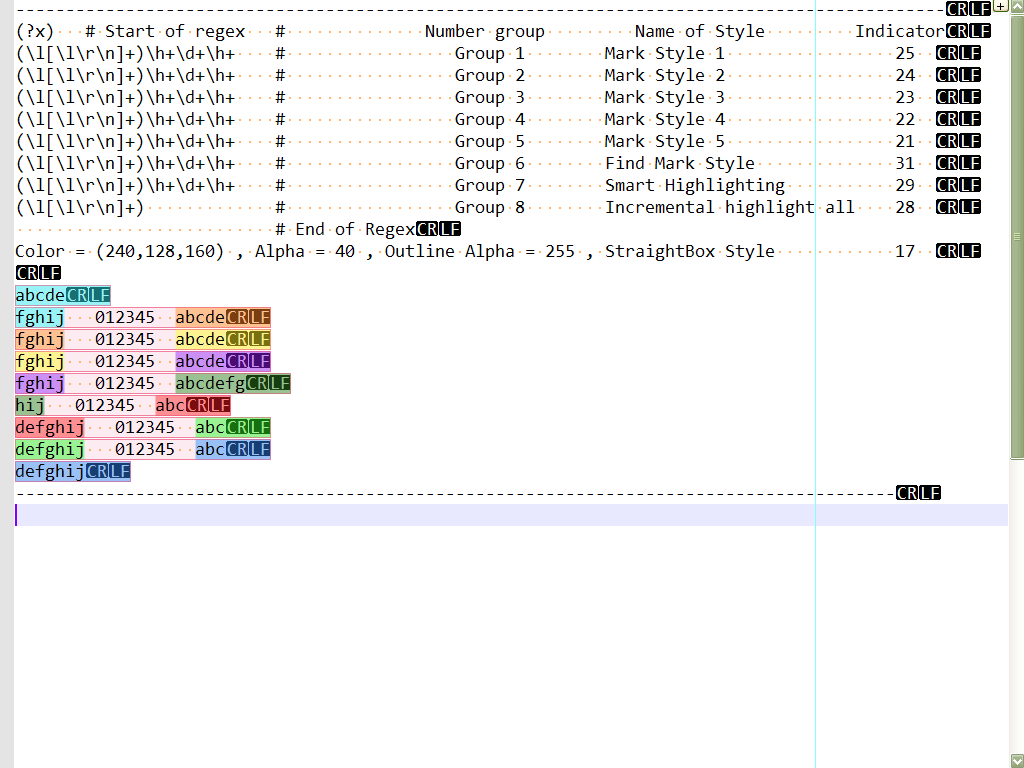
Now, we already have a default regex, with the line
regex = r'.............'But, Allan (and this is my last request, I promise !), could you add the automatic assignment of the current selection to the regex variable ?I mean something like :
If no current main *selection THEN
regex = notepad.prompt...ELSE regex = current selection ( without any dialog )TIA,
Cheers,
guy038
-
@guy038 said in Filter the data !!!:
Alan (and this is my last request, I promise !), could you add the automatic assignment of the current selection to the regex variable ?
Remember, you promised!
Here’s the “b” version:
# -*- coding: utf-8 -*- # see https://community.notepad-plus-plus.org/topic/19240/filter-the-data # see https://community.notepad-plus-plus.org/topic/14501/has-a-plugin-like-sublime-plugin-brackethighlighter from Npp import editor, notepad, INDICATORSTYLE class T19240b(object): def __init__(self): free_indicator_to_use = 17 self.indicator_set_options(free_indicator_to_use, INDICATORSTYLE.STRAIGHTBOX, (240,128,160), 40, 255, True) indic_list = [ free_indicator_to_use, 25, 24, 23, 22, 21, 31, 29, 28 ] for i in indic_list: self.clear_all(i) if editor.getSelectionEmpty(): regex = r'(?-s)(notepad|editor)\.(.*?)\(.*?\)' # a regex just for demo purposes regex = notepad.prompt('Enter regex (just Cancel to clear colors from previous run):', '', regex) else: regex = editor.getSelText() if regex == None or len(regex) == 0: return def match_fn(m): for grp in range(len(m.groups()) + 1): #print('{g} -> {s} |{text}|'.format(g=grp, s=m.span(grp), text=m.group(grp))) if grp < len(indic_list): # we only have a finite number of colors but we could have more groups than that if m.span(grp)[0] != m.span(grp)[1]: # don't bother with zero-length groups; or groups not matched: (-1, -1) self.fill(indic_list[grp], m.span(grp)[0], m.span(grp)[1]) editor.research(regex, match_fn) def fill(self, indic, start_pos, end_pos): editor.setIndicatorCurrent(indic) editor.indicatorFillRange(start_pos, end_pos - start_pos) def clear_all(self, indic): editor.setIndicatorCurrent(indic) editor.indicatorClearRange(0, editor.getTextLength()) def indicator_set_options(self, indicator_number, indicator_style, rgb_color_tup, alpha, outline_alpha, draw_under_text): for ed in (editor1, editor2): ed.indicSetStyle(indicator_number, indicator_style) # e.g. INDICATORSTYLE.ROUNDBOX ed.indicSetFore(indicator_number, rgb_color_tup) ed.indicSetAlpha(indicator_number, alpha) # integer ed.indicSetOutlineAlpha(indicator_number, outline_alpha) # integer ed.indicSetUnder(indicator_number, draw_under_text) # boolean if __name__ == '__main__': T19240b() -
Hi, @Alan-kilborn and All,
Alan, this version is just perfect ! Up to now, when building a complicated search regex, containing some groups, I was used to type in this regex, in the Replace dialog, to clearly see the contents of each group :
REPLACE
\r\n>$1<\r\n>$2<\r\n>$3<\r\n>$4<\r\n>$5<\r\n......>$n<\r\nNow, with your script :
-
Select the regex where you want to notice the different groups, from
1to8, as well as the overall match$0, for each occurrence, in current file -
Execute the last version of your Python script, that I renamed
Groups_Highlighter.py, BTW ;-))
Much more elegant, isn’t it ?
Best Regards
guy038
P.S. : Two more points :
-
Out of curiosity, what means, exactly, the syntax
T19240? -
I tried to change the draw_under_text value from
TruetoFalse. But I did not see any difference ?!
Thanks, again, Alan, for this valuable script :-))
-
-
I renamed Groups_Highlighter.py
I called my copy
ColorizeRegex.pybut to each his own!what means, exactly, the syntax T19240 ?
It’s the topic id of this thread in the forum! :-)
This is a Peter-ism. :-)tried to change the draw_under_text value from True to False. But I did not see any difference ?!
Not sure, it was in the code I stole from the earlier referenced thread, about bracket-highlighting.
I don’t think I fully follow the DOCS about it, either. -
Of course, with this new script, aren’t we somewhat reinventing a four-year-old WHEEL ??
I’m sure Peter will be scanning your tabs in your screenshot HERE looking for interesting things. :-)
-
Hi, @alan-kilborn,
Yes, I also remember the @claudia-frank’s regex_tester script However it does not behave the same way than your script !
As far as I can remember, it just used two colors for two consecutive groups + a third color for the overall match. So, if your regex contained, for instance,
3groups => groups1and3were highlighted with the first color, the group2with the second color and the overall regex/occurrence with the third color !And I think that your script, with a different color for each group, is quite interesting, too !
Ah… too late, I promised ! I just forgot the case when two
$0regexes are consecutive. then the straight-boxes are joined and no separation appears to show where the boundary between the two occurrences, is !I will survive this ;-))
BR
guy038
-
@guy038 said in Filter the data !!!:
Ah… too late, I promised ! I just forgot the case when two $0 regexes are consecutive. then the straight-boxes are joined and no separation appears
It’s a critical bug, not a new feature request. I will work on it.
-
@Alan-Kilborn said in Filter the data !!!:
I’m sure Peter will be scanning your tabs in your screenshot HERE looking for interesting things. :-)
Well, I’m mildly surprised. One, because I’d forgotten I’d passed my four-year anniversary in December. Two, because I had only about 8 posts (if the search for my posts, sorted by ascending date doesn’t miss any). He had replied once or twice to me in that timeframe, but I’m surprised I was “on his radar” yet – at least enough to save a tab for that long.
While looking at the early posts, I was amused to see me say, in this Jan 2016 post,
I am not a Notepad++ expert
I don’t think I can rightly claim that anymore. :-)
-
Hello, @alan-kilborn, @peterjones and All,
I first joined the Notepad++ forum, on
SourceForge.net, onMay 08 2013. Then, fromJun 24 2015, as others, I migrated to ourNodeBBforumI’m used to save any of my posts in a simple
.txtfile , in a specific folder, giving the OP’s name to that file. So, at any moment, I keeps opened tabs of my recent posts because, sometimes, the OP does not answer immediately !Of course, I should, daily, close some of these tabs, when either, the OP succeeded to solve his problem or do not reply, after a while ! But, I have to admit that I do not apply myself to this daily task, but only from time to time, which explains the numerous tabs of my session !
However, and this seems obvious, regarding your case, Alan and Peter, and some others, you are quite active on our forum. Therefore, I simply keeps your tab opened permanently ;-))
Up to now, after a look into
Users > Most Reputation, I created2,361posts. The specific folder, where are all my saved posts, contains1,265text files. Let’s say that a couple of them are from mine : this means that I created about1.87post per OP ;-)) (2,361 / 1,260)Best Regards,
guy038
-
Hi, @alan-kilborn,
Regarding the issue of consecutive
$0ranges of text :May be using two different styles, let’s say
17and18( if free, of course ), and swapping, successively, to each style, for each$0occurrence ?BR
guy038
-
@guy038 said in Filter the data !!!:
May be using two different styles, let’s say 17 and 18 ( if free, of course ), and swapping, successively, to each style, for each $0 occurrence ?
Exactly what I had in mind, I just have to find a bit of free time to do it. :-)
17 and 18 ( if free, of course )
I believe these are “free” on a default system, but of course, it is worth pointing out that if others happen to be using these, and still want to use this script, they should alter the numbers.
-
This version seems to delineate the start of a following match beginning right where the previous match ended:
# -*- coding: utf-8 -*- # see https://community.notepad-plus-plus.org/topic/19240/filter-the-data # see https://community.notepad-plus-plus.org/topic/14501/has-a-plugin-like-sublime-plugin-brackethighlighter from Npp import editor, notepad, INDICATORSTYLE class T19240c(object): def __init__(self): free_indic_list_for_group0 = [ 17, 18 ] self.indicator_set_options(free_indic_list_for_group0[0], INDICATORSTYLE.ROUNDBOX, (240,128,160), 40, 255, True) self.indicator_set_options(free_indic_list_for_group0[1], INDICATORSTYLE.ROUNDBOX, (240,128,160), 40, 255, True) indic_list = [ free_indic_list_for_group0[0], 25, 24, 23, 22, 21, 31, 29, 28, free_indic_list_for_group0[1] ] for i in indic_list: self.clear_all(i) regex = editor.getSelText() if len(regex) == 0: regex = r'(?-s)(notepad|editor)\.(.*?)\(.*?\)' # a regex just for demo purposes; delete this line if desired regex = notepad.prompt('Enter regex (just Cancel to clear colors from previous run):', '', regex) if regex == None or len(regex) == 0: return def match_fn(m): for grp in range(len(m.groups()) + 1): print('{g} -> {s} |{text}|'.format(g=grp, s=m.span(grp), text=m.group(grp))) if m.span(grp)[0] != m.span(grp)[1]: # don't bother with zero-length groups; or groups not matched: (-1, -1) if grp < len(indic_list) - 1: # we only have a finite number of colors but we could have more groups than that self.fill(indic_list[grp], m.span(grp)[0], m.span(grp)[1]) (indic_list[0], indic_list[-1]) = (indic_list[-1], indic_list[0]) # toggle between 2 indicators for subsequent group 0 editor.research(regex, match_fn) def fill(self, indic, start_pos, end_pos): editor.setIndicatorCurrent(indic) editor.indicatorFillRange(start_pos, end_pos - start_pos) def clear_all(self, indic): editor.setIndicatorCurrent(indic) editor.indicatorClearRange(0, editor.getTextLength()) def indicator_set_options(self, indicator_number, indicator_style, rgb_color_tup, alpha, outline_alpha, draw_under_text): for ed in (editor1, editor2): ed.indicSetStyle(indicator_number, indicator_style) # e.g. INDICATORSTYLE.ROUNDBOX ed.indicSetFore(indicator_number, rgb_color_tup) # (red, green, blue) ed.indicSetAlpha(indicator_number, alpha) # integer ed.indicSetOutlineAlpha(indicator_number, outline_alpha) # integer ed.indicSetUnder(indicator_number, draw_under_text) # boolean if __name__ == '__main__': T19240c() -
Hello, @alan-kilborn, @ekopalypse, @peterjones and All,
Perfect, Alan ! I chose an other color for
Straightbox Style 2, which have the same Saturation and Lightness thanStraightbox Style 1color, in theHSLColor Space ( S ≈79and L ≈72). So, I could choose the same Alpha transparency (40).From their Hue (
343and201) we deduce that they come from the pure colors[255,0,73]and[0,164,255]([343,100,50]and[201,100,50]values in theHSLColor Space )Here is, in a screenshot, a summary of the different styles, with their
RGBvalues and theirAlphatransparency as well as an example of the color alpha blending process, used in Notepad++, relative to the mixing of the ID style25with the ID style17, over theWhitebackground ([255,255,255]) of the Default style of Default theme (Stylers.xml)

Two observations :
-
I noticed that you cannot use the
Smart Highlightingstyle, either, natively and with your script. Thus, I preferred to place it at the end of the list, so for group8 -
When less than
6groups are involved in the overall regex, after running your script, if we use the Context menuRemove style > Clear all Stylesoption, we just see the highlighting of each$0occurrence, alternatively, in light sky-blue or carmine color
Best Regards,
guy038
-
-
@guy038 said in Filter the data !!!:
a summary of the different styles, with their RGB values and their Alpha transparency as well as an example of the color alpha blending process,
You are the ColorMaster in addition to being the RegexMaster.
cannot use the Smart Highlighting style, either, natively and with your script.
True. If you run the script and it uses that color, the next time you use Smart Highlighting it will erase any of that color the script placed in favor of its own results. And the other way around.
if we use the Context menu Remove style > Clear all Styles option
What that command actually does in relation to the script is to remove the coloring that the script does with indicators 21 through 25.
For maximum flexibility, we could make the Notepad++ coloring features and this script’s coloring features totally independent. This would eat up unallocated indicators, but that’s ok, isn’t it? :-)
Really, all of the tools for you to go ahead and do this yourself @guy038 are already in the script. Just don’t use indicators 21 through 25, and 28 through 31. IIRC, 26 and 27 are also used by Notepad++ for something, so stay away from those. If you started, say at 20 and worked your way downward… Based upon Scintilla docs, I think they may be all unused until you get down to number 8.
What do you think? Is it worth me modifying the script? Or can you do it, if it is valuable?