Looking for a freelancer to develop a plugin: Misspelled Word Counter
-
Hello, @miguel-lescano and All,
Did you notice that, since the version
1.4.16of DSpellCheck, a new option to bookmark all lines, containing misspelled words, is available for further process, viaSearch > Bookmark?- Support bookmarking lines containing misspelled words via additional actions
Also, since the
1.14.0version, this hidden option, below, could be of some interest to you :- Add hidden option
Word_Minimum_Lengthto disable checking of words with length less or equal to its value
For any
DSpellCheckrelease, refer to :https://github.com/Predelnik/DSpellCheck/releases
Best Regards,
guy038
-
@Ekopalypse Thanks a lot! It’s fantastic! I just had to change the name of the dictionary file inside the .py file and it worked!
Yes, my customized dictionary files are in C:\Users\Miguel\AppData\Roaming\Notepad++\plugins\config\Hunspell
And yes, it has one word per line, starting with the number of words. Here’s how it looks:
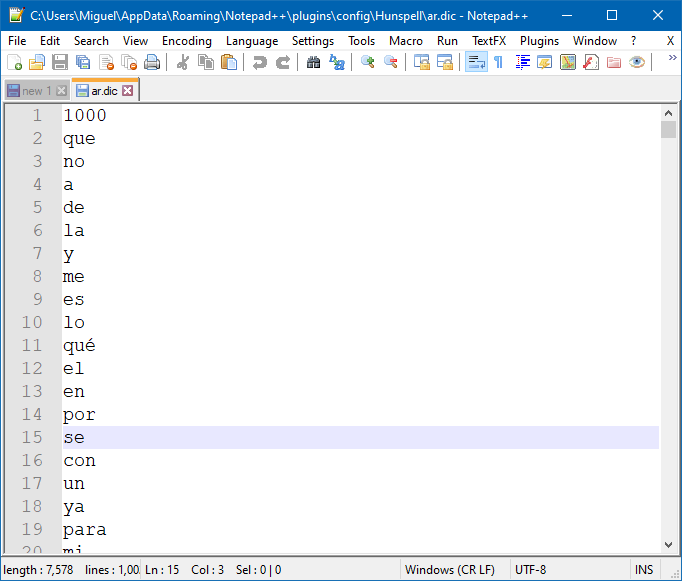
Your tip to just change the name of the .aff and the .dic files worked! The weird thing is, if I copy the .aff from arabic and just rename it, say, “Spanish TOP1000”, it works, but if I change the contents of the .aff file it treats all words with diacritics as misspellings. Strange. I guess I’ll just keep the content of the arabic .aff file. What’s supposed to be inside the .aff, anyway? Without an .aff file I noticed the dictionary won’t appear, and if I just type “Spanish” inside the .aff file it, again, marks all words with diacritics as misspellings.
I don’t switch a lot between dictionaries when editing a story. I decide which level I’m going for and just go for it, unless I decide the story is too difficult to write at the level I chose and change the level. But I see I can just make 5 copies of the script and give them different names pointing to different dictionaries.
Having all documents affected is not a problem. I’m very unlikely to be working on two stories for different levels at the same time.
And yes, I noticed it calculates misspellings a bit different. The differences from DSpellCheck default settings are that DSpellCheck ignores:
-Numbers
-Words containing numbers
-ALL CAPS words, such as USA or V&M.
-Words containing _There also seem to be some non-visible characters being counted as misspellings. The file I’m linking to here has 37 misspellings, but the script counts 38.
https://www.spanishinput.com/uploads/1/1/9/0/11905267/37_misspellings.txtThanks a lot for your help! I’ve just donated to the link you provided. The donation buttons didn’t play nice with my Chrome cookies, so I had to open an incognito window.
-
@guy038 Thanks for the tips!
-
I have already found two problems, replacing the regex string
\w+with[[:alpha:]]+
should eliminate many false positives and in addition, creating an
insensitive error_words list will reduce the number of unique errors,
because then Amèrica and amèrica are the same, which brings me to
the first question, which encoding do you use?When I open the uploaded file, I see the following

If possible, you should use utf8 encoded files.
As far as the aff files are concerned and as far as I understand it, they
are basically rule files that the hunspell engine tells how to treat the file
and how it should treat certain rules for words with special notation.But treat this information with skepticism, since I only started to
investigate hunspell yesterday.
I will try to see if I can find more information about the aff format,
maybe this will help to get the same results as hunspell itself.By the way, if I were you, I would use the spanish.aff as a template for all your TOP dictionaries.
The donation buttons didn’t play nice with my Chrome cookies, so I had to open an incognito window.
@donho, maybe something you are interested in??
-
ok, after some more research I guess I can confirm my opinion on
affix files. They are more or less rule files. In your case there is only
a few lines needed and these can be the same for all your 5 aff
files. If you want to go into detail about the file format, here the
link to the description.My aff file looks like this
SET UTF-8 FLAG UTF-8 TRY aeroinsctldumpbgfvhzóíjáqéñxyúükwAEROINSCTLDUMPBGFVHZÓÍJÁQÉÑXYÚÜKWHere the updated script which gets the same result as DSpellCheck on the example text I used earlier.
from Npp import notepad, editor, NOTIFICATION, SCINTILLANOTIFICATION, STATUSBARSECTION, MODIFICATIONFLAGS import os class WORD_CHECKER(object): def __init__(self): self.report = ('Total: {0:<5} ' 'Unique: {1:<5} ' 'Total non-misspelled: {2:<5}({3:.1%}) ' 'Total misspelled: {4:<4}({5:.1%}) ' 'Unique misspelled: {6:<4}({7:.1%})') editor.callbackSync(self.on_modified, [SCINTILLANOTIFICATION.MODIFIED]) notepad.callback(self.on_buffer_activated, [NOTIFICATION.BUFFERACTIVATED]) current_dict_path = os.path.join(notepad.getPluginConfigDir(), 'Hunspell') current_dict_file = os.path.join(current_dict_path, 'Spanish TOP972.dic') with open(current_dict_file, 'r') as f: self.current_dict = f.read().splitlines()[1:] # skip length entry self.on_buffer_activated({}) def check_words(self): words = [] editor.research('[[:alpha:]]+(?=[\h|[:punct:]|\R|\Z])', lambda m: words.append(m.group())) error_words = [word.lower() for word in words if word.lower() not in self.current_dict and # insensitive word check not word.isupper() # ignore all uppercase only words ] total = len(words) unique = len(set(words)) misspelled = len(error_words) misspelled_unique = len(set(error_words)) notepad.setStatusBar(STATUSBARSECTION.DOCTYPE, self.report.format(total, unique, total-misspelled, # non-misspelled (float(total-misspelled) / total) if misspelled else 1, # non-misspelled % misspelled, (float(misspelled) / total) if misspelled else 0, misspelled_unique, (float(misspelled_unique) / total) if misspelled_unique else 0)) def on_modified(self, args): if ((args['modificationType'] & MODIFICATIONFLAGS.INSERTTEXT) or (args['modificationType'] & MODIFICATIONFLAGS.DELETETEXT)): self.check_words() def on_buffer_activated(self, args): self.check_words() WORD_CHECKER()You stated that you want to run 5 copies of the script.
If you run it in 5 different npp instances, then yes, that might
be a solution but if you want to run this script in an npp instance with 5 different documents then it won’t do what you
probably expect. -
@Ekopalypse THANKS A LOT!!! It now exactly matches the number of misspellings reported by DSpellcheck!
The txt file I uploaded is UTF-8 on my PC. Maybe uploading it to Weebly changed the format. I should have zipped it.
BTW, I actually like the fact that you’re ignoring numbers and words with numbers from the total words, because when I type those I don’t want them to influence the statistics.
This will make it a LOT easier for me to write stories for my students.
I’d love to credit you in my website for writing this amazing tool. Should I credit you as “Ekopalypse” or do you prefer something else? May I post the script to my website for free so other language teachers can use it? Of course, crediting you. I’ll also post a video to my channel explaining why to use it and how to use it.
-
Thank you, yes you are welcome to publish this for free and there is no copyright claim from my side.
It is not necessary to mention me, but if you should mention me, please use my Ekopalypse pseudonym.I hope that this can be helpful for you and others, but I’m almost sure that with other languages
and/or other DSpellCheck settings this will not always achieve the same results as DSpellCheck.
Actually this feature would be better available in DSpellCheck I guess.
Maybe you could convince predelnik to implement it!? My approach could serve as a template.
Maybe another tab called Statistics under Settings… with an option to display this in realtime in the DocType field!?This brings us to another point.
I noticed that DSpellCheck produces an exception when you wants to start a Python script via the toolbar.
This will not happen if the script is started from either the Scripts submenu, the PythonScript main menu or via KeyboardShortcut.
I opened an issue for this here.Otherwise I can only wish you good luck for your stories.
-
@Ekopalypse Hi! I’ve been testing the script and I noticed, with this txt file, that the script reports 23 misspelled words (7 unique), but both DSpellCheck and a quick visual count tell me there are just 22 misspellings (6 unique). Maybe I’m doing something wrong? Could you please give this a look?
Here’s the TXT file. This time I zipped it so it does not lose the formatting:
https://www.spanishinput.com/uploads/1/1/9/0/11905267/lagrimas_de_acero_new.zipAnd here’s the dictionary I’m using:
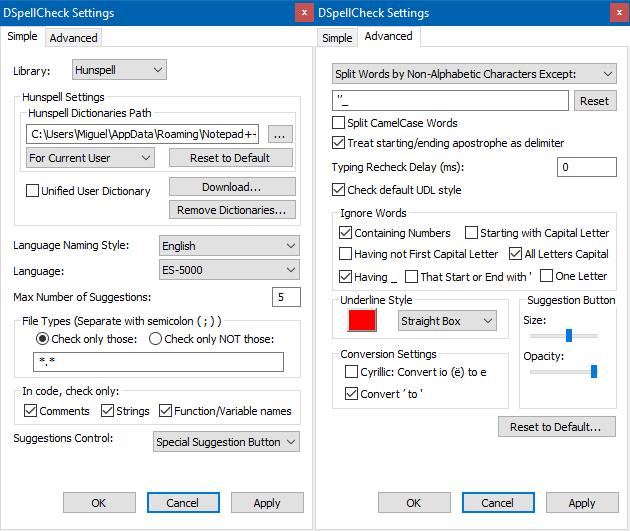
https://www.spanishinput.com/uploads/1/1/9/0/11905267/es-5000.zipAnd here are my DSpellCheck settings. Thanks again for all your help!
-
@Ekopalypse Hi! I found the problem. Words that start with a capital letter that has a diacritic are flagged as false positives. For example, Él.
-
@Ekopalypse Me again…
I also discovered that, if I do not type a period, or a space, after a word, but instead press “Enter” or just do nothing and stop writing, that word is not taken into account at all.
-
Hi, @Ekopalypse… Just wanted to report that I’ve been testing what kinds of letters with diacritics trigger a false positive when they’re the first letter and a capital letter:
Accent marks (acute):
Árbol, ÉlTilde over the N:
ÑañoThe umlaut:
Über
(We do have the umlaut in Spanish, but I’ve never seen it at the start of a word, so I used a German word here)Once again, thanks a lot for all the time you’ve devoted to this script!
-
Good testing, I will check that as soon as I get home.
-
I found the two issues.
First, a typo and second, a greeting from the past.The typo is responsible for the behavior when no more characters are attached to a word.
editor.research('[[:alpha:]]+(?=[\h|[:punct:]|\R|\Z])', lambda m: words.append(m.group()))must be
editor.research('[[:alpha:]]+(?=\h|[[:punct:]]|\R|\Z)', lambda m: words.append(m.group()))The second problem has to do with the fact that Python2 and Python3 handle Unicode text differently.
Since I have been working only with Python3 for quite some time now I completely ignored the fact that for example ‘Ü’ is a bytes object in Python2 and a Unicode object in Python3.
This means that we have to work with Unicode in our code as well, so that functions like .lower() work.from Npp import notepad, editor, NOTIFICATION, SCINTILLANOTIFICATION, STATUSBARSECTION, MODIFICATIONFLAGS import os class WORD_CHECKER: def __init__(self): print('__init__') self.report = ('Total: {0:<5} ' 'Unique: {1:<5} ' 'Total non-misspelled: {2:<5}({3:.1%}) ' 'Total misspelled: {4:<4}({5:.1%}) ' 'Unique misspelled: {6:<4}({7:.1%})') editor.callbackSync(self.on_modified, [SCINTILLANOTIFICATION.MODIFIED]) notepad.callback(self.on_buffer_activated, [NOTIFICATION.BUFFERACTIVATED]) current_dict_path = os.path.join(notepad.getPluginConfigDir(), 'Hunspell') current_dict_file = os.path.join(current_dict_path, 'ES-5000.dic') with open(current_dict_file, 'r') as f: self.current_dict = [word.decode('utf8') for word in f.read().splitlines()[1:]] # skip length entry self.DEBUG_MODE = False self.on_buffer_activated({}) # must be last line here as it triggers check_words def check_words(self): words = [] editor.research('[[:alpha:]]+(?=\h|[[:punct:]]|\R|\Z)', lambda m: words.append(m.group().decode('utf8'))) if self.DEBUG_MODE: print(u'words contains:\n {}'.format(' '.join(words))) error_words = [word.lower() for word in words if word.lower() not in self.current_dict and # insensitive word check not word.isupper() # ignore all uppercase only words ] if self.DEBUG_MODE: print(u'error_words contains:\n {}'.format(' '.join(error_words))) print(u'error_words unique contains:\n {}'.format(' '.join(set(error_words)))) total = len(words) unique = len(set(words)) misspelled = len(error_words) misspelled_unique = len(set(error_words)) notepad.setStatusBar(STATUSBARSECTION.DOCTYPE, self.report.format(total, unique, total-misspelled, # non-misspelled (float(total-misspelled) / total) if misspelled else 1, # non-misspelled % misspelled, (float(misspelled) / total) if misspelled else 0, misspelled_unique, (float(misspelled_unique) / total) if misspelled_unique else 0)) def on_modified(self, args): if ((args['modificationType'] & MODIFICATIONFLAGS.INSERTTEXT) or (args['modificationType'] & MODIFICATIONFLAGS.DELETETEXT)): self.check_words() def on_buffer_activated(self, args): self.check_words() WORD_CHECKER()The new code has an additional DEBUG_MODE, which, if set to True,
will print the content of words-, error_words- and unique error_words-list
to the python script console.At the moment I am checking if it is possible or if it makes sense to read the DSpellCheck.ini to apply the settings automatically if necessary.
For example one might treat ALL Letters Capital as misspelled words. -
@Ekopalypse Thanks a lot! I can’t find the typo to save my life…
I’ve been using your script today to write the cues for my very first crossword puzzle for Spanish learners:
http://crossword.info/spanishinput/Spanish_Input_Level_1_Puzzle_001
All the cues use only words from the top 1000, except for proper names.BTW, I have a couple of special request, so feel free to charge me for this. I know this is taking from your time, and I’m grateful for it:
Is there a way to add comment lines that are completely ignored from the calculation? I mean, not even counted in the word total. Maybe lines that start with // or with an asterisk or something like that.Yes, I’ve been thinking about the All caps letters thing… Sometimes it does make sense to treat them the same as the other words. Still thinking…
Thanks a lot!
-
@Ekopalypse said in Looking for a freelancer to develop a plugin: Misspelled Word Counter:
Maybe you could convince predelnik to implement it!? My approach could serve as a template.
Maybe another tab called Statistics under Settings… with an option to display this in realtime in the DocType field!?I agree with this, you could request a new feaure here:
https://github.com/Predelnik/DSpellCheck/issuesSo like “feature request: count misspelled words” or “report/stats of misspelled words” or something like that, and refer to this forum thread.
-
@Miguel-Lescano said in Looking for a freelancer to develop a plugin: Misspelled Word Counter:
I’ve been using your script today to write the cues for my very first crossword puzzle for Spanish learners:
Cool :-)
BTW, I have a couple of special request, so feel free to charge me for this. I know this is taking from your time, and I’m grateful for it:
As long as I have time to do it and enjoy making it work, no problem.
Is there a way to add comment lines that are completely ignored from the calculation? I mean, not even counted in the word total. Maybe lines that start with // or with an asterisk or something like that.
Yes, this is possible, but that will mean that misspelled-word-synchronization with DSpellCheck isn’t working anymore, correct?
-
@Ekopalypse Yes, this would kinda break things with DSpellCheck, but it’s not a problem.
I’d love to be able to add notes between Spanish dialogues. The notes would not be actually recorded for my students. I have a YouTube channel where I publish recordings of my stories:
https://www.youtube.com/watch?v=XfpbG_5Im9QIn the future, I plan to learn to use Unreal Engine to create short animations, so the notes would also include scene descriptions.
-
The easiest way would be if the comment always starts at the
beginning of a line. But it can also be solved if the comment appears at
the end. What wouldn’t be so nice is if something like text comment text
is thought of or comment goes over several lines without the
new lines having a comment character at the beginning.Assuming we use
//as the “comment sign”Relatively easy
// Comment Text // CommentNot so easy:
// Comment still comment // Text Text //comment comment// TextWhat do you think?
-
@Ekopalypse Hi!
Yes, my plan is to have comment-only lines that could start with //, so the “relatively easy” option is what I’m looking for. I guess the line can be as long as I want it to be, right? -
@Miguel-Lescano said in Looking for a freelancer to develop a plugin: Misspelled Word Counter:
I guess the line can be as long as I want it to be, right?
Theoretically yes, but there is a known problem with szintilla and the handling of “really” long lines but I do not assume that your comments
are longer than 1000 characters, right?Ok, I give it a try.