Help for an ANSI file
-
If you open a file, what shows npp in the statusbar? ANSI or cp1251?
-
@Ekopalypse
Example:
Initially the file is encoded OEM 866And notepad ++ opens up different options: Macintosh, Windows-1251, ANSI, UTF-8
-
Hmmm … why should npp do this if you have automatic encoding detection disabled? Strange, it does not do this for me.
Is OEM866 much different to cp1251? -
I am interested in how this conversation turns out.
I would like to know if there is a bug with this or not.
Note that I would not consider N++'s lack of autodetection of what the user thinks is the correct encoding a bug, but I would if the user sets and encoding, saves a file, and somehow N++ messes that up. -
@Ekopalypse
@Alan-Kilborn
My file is OEM 866 and notepad ++ opens it as Macintosh, Windows-1251, ANSI, UTF-8 (options are always different)For bat files, I need exactly the OEM 866 encoding.
(sorry for my google translate) -
Если Вы отключили автоматическое распознавание и используете набор символов, противоречащий Вашим настройкам “ANSI”, блокнот++ не сможет отобразить документ в правильном формате.
Вот пример:
Я использую OEM850 и сохранил этот текст: “Неприятности в раю”.
Если я сейчас запущу блокнот++ и открою файл, то блокнот++ покажет мне это.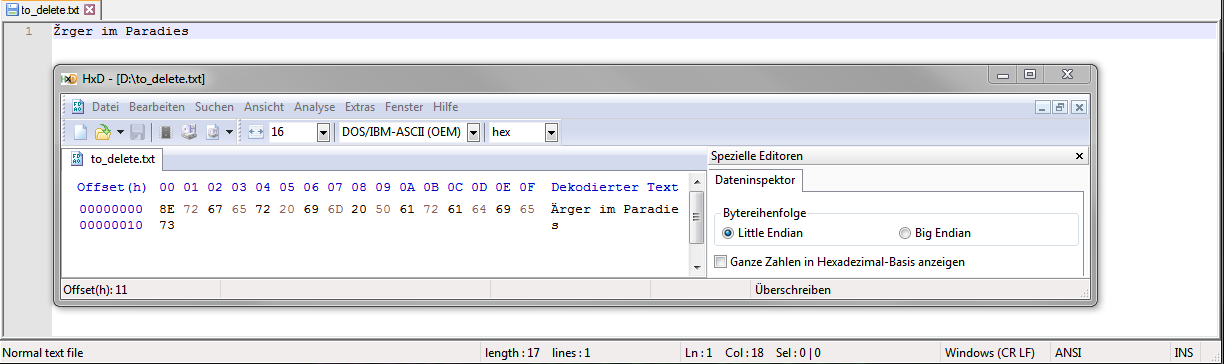
Он использует настройку операционной системы ANSI, которой для меня является CP1251.
Это нормально, но блокнот++ всегда сообщает ANSI и больше ничего.
Тот факт, что ты сообщаешь о разных вещах, вот что путает меня с твоим заявлением.
Почему ANSI не всегда отображается? Странно. -
Конечно, моя кодировка 1252, а не 1251.
-
In my humble opinion this is a user interface failure.
What is the meaning of disable autodetect character encoding? If Notepad++ does not autodetect then it must assume some default. What is this default? – I tested and it is not the new file encoding.The UI should have had a radio button that selects one of two options:
- Autodetect character encoding.
- Assume any opened files is <combo box>
There could be more advanced features like letting the user select a group of acceptable encodings for his region where Notepad++ must guess one of them. But that goes beyond UI.
-
If Notepad++ does not autodetect then it must assume some default.
I thought then it is ANSI, which depends on what GetACP returns for the current setup.
-
@Ekopalypse
It is the first time I ever heard of GetACP and I wonder how a typical user should anticipate the behavior when he disables autodetect.
And it is obviously still broken because a user should be allowed to instruct Notepad++ to assume some specific UNICODE encoding rather than codepage. -
@gstavi said in Help for an ANSI file:
user should be allowed to instruct Notepad++ to assume some specific UNICODE encoding rather than codepage
This might be relevant to that:
HERE @PeterJones says:
- In the Settings > Preferences > New Document settings, if UTF-8 is chosen as your default encoding, you can also choose to always apply UTF-8 interpretation to files that Notepad++ opens and guesses are ANSI, not just to new files.
It seems a bit strange, or downright bad, that this option is buried in with the “New Document” settings?
-
@gstavi said in Help for an ANSI file:
I am also not convinced that it works 100%, and I have tried to understand this part of the code, but I have to admit that it is quite confusing for me.
I agree, it would be nice to have a possibility to force an encoding but
what I would like to have is to force a lexer to a specific encoding.
Like batch to OEM850 and python to utf8 … -
I did some more tangential playing around with this.
I found that N++ will open a “7-bit ASCII” file (not sure how to really say that!) that has a NUL character in it, as ANSI. All other characters are your typical A-z0-9.
But if the NUL is replaced with a SOH character, N++ opens it as UTF-8.
Curious about why it does it differently.Of course, I’m mostly set up (I think) to have it work with UTF-8, but I’m less and less sure as the discussion goes on, what I should have selected in the Preferences to do this. :-)
-
My understanding, when having autodetection disabled, is the following:
A Scintilla buffer is initialized with _codepage = ::GetACP().
The entry point isNotepad_plus::doOpen(const generic_string& fileName, bool isRecursive, bool isReadOnly, int encoding, const TCHAR *backupFileName, FILETIME fileNameTimestamp)The following steps are performed
- npp checks if the file is an html or xml file and if the encoding can be read from the prolog.
- when it is loaded from a session, it gets the encoding that was used before
else - Npp tries to find out if it is Unicode or ANSI (I don’t understand this part of the code)
if it is a Unicode, the encoding is set accordingly
otherwise Npp checks if “open ANSI as utf8” is configured and sets either ANSI or utf8
-
Hello, @alan-kilborn and All,
Well, Alan, I guess the problem and there is a real bug !
First, I suppose that, in your
Settings > Preferences... > New Document > Encoding:-
The
UTF-8encoding ( Not theUTF-8 with BOMone ) is selected -
The
Apply to opened ANSI filesoption is selected
And in
Settings > Preferences... > New Document > MISC.:- The
Autodetect character encodingoption is UNCHECKED
Note Alan, that is also my own configuration, too !
Now, let’s suppose that you open an N++ new file => So, in the status bar, the
UTF-8encoding is displayed : logical !Now just write the string ABCD, save this new file as
Test.txtand close Notepad++While opening this file, any editor, without any other indication, cannot tell which is its right encoding :
-
It could be encoded with four bytes
41424344in anANSIfile ( so any Windows encoding asWin-1252,Win-1251, … because theASCIIpart, from00to7Fis identical -
It could be encoded, also, with four bytes
41424344in a N++UTF-8file ( so without aBOM). Indeed, with theUTF-8encoding, any character with code-point under\x{0080}is coded with in1byte only, from00to7F
But, as we have the setting
Apply to opened ANSI filesset, when you re-open theTest.txtfile, again, you should see theUTF-8indication in the status barAnd, adding the SOH character (
\x{01}) , or any character till\x{1F}( I verified ), between AB and CD does not change anything. The encoding will remainUTF-8!But, adding the NUL character change does change the encoding as
ANSI, which is in contradiction with our user settings ! However, this particular case ( NUL char + pureASCIIchars, only ) does not really matter as current contents file do not change when switching from ANSI toUTF-8and vice-versa, anyway !
Now, what’s more annoying is that the presence of the NUL character still forces the
ANSIencoding, even if a character, with code over\x{007F}, is added to the file :-(( For instance, if you add the very common French charé, to get the stringABNULCDéand save this file with anUTF-8encoding, when you re-open this file, the encoding is wrongly changed toANSI. So, the wrong stringABNULCDéis displayed !Remember that the contents of
Test.txtfile, the stringABNULCDé, after saving, are4142004344C3A9with theUTF-8encoding ( This same string, would be coded4142004344E9in anANSIfile )So, although files with NUL characters are not common in classical text files, I suppose that this bug need creating an issue. What is your feeling about it ?
Best Regards,
guy038
-
-
@guy038 said in Help for an ANSI file:
First, I suppose that, in your Settings > Preferences… > New Document > Encoding
Right on the settings assumptions, except for me The Autodetect character encoding option is CHECKED
So, although files with NUL characters are not common in classical text files, I suppose that this bug need creating an issue. What is your feeling about it ?
Well, I was just sort of experimenting around. NUL characters are not something I typically use. Although I do have the feeling that if Scintilla allows them in the buffer (and clearly it does because I can see a black-boxed “NUL”), then Notepad++ itself should try and “do the right thing” (whatever that is) about them.
-
But…
It does seem like I as a user should be able to tell the software: "If a file can’t officially be identified via a BOM, then open it as ‘xxxxxxx’ " (UTF-8 for me! but YMMV). -
@Ekopalypse An example of an error:
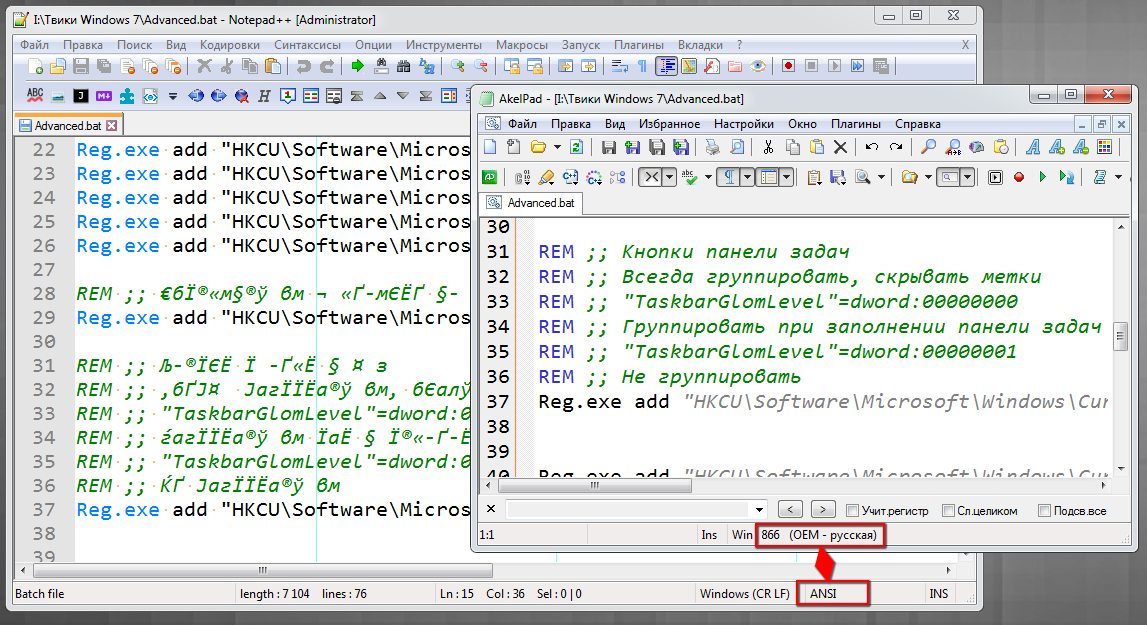
-
@andrecool-68
Npp has no chance to find out what encoding it is, neither does AkelPad.What AkelPad does is to save the selected encoding in HKEY_CURRENT_USER\Software\Akelsoft\AkelPad\Recent.
If you open enough other documents, more than 10, and you have not changed the default setting, you will see that AkelPad opens your batch file with ANSI encoding as well.
-
@Ekopalypse
In AkelPad you can reopen a document 1000 times and re-save 1000 times without breaking the file content, and Notepad ++ cannot boast of that.
I mean working with encoding))