Help for an ANSI file
-
Re: Convert to ANSI
Hi !
I open a new file “tmp.txt” with Notepad++ on Windows 10,
I set Encodage to ANSI.
I write “éèàÔ€” in the file.
I close the file.
I close the tab.
I can read the file “tmp.txt” with Notepad.
I cannot read the file with Notepad++.
Is it my problem ? -
Not sure what you are saying here.
Do you mean that if you reopen the file with Notepad++ it does not appear to be the same as when you lasted edited it? -
@Alan-Kilborn
Yes, it’s not possible to set codage is ANSI. -
@jfaset ,
A lesson in how Windows handles encodings: it doesn’t, and leaves it up to applications. The files are a series of bytes, and it does not store any meta-data to tell applications what encoding the file is.
Notepad++ is thus presented a series of bytes, and has only a few different ways of determining what the encoding is:
- If you are wise, and using a Unicode encoding like UCS-2 LE/BE, which require a BOM, or UTF-8, which allows a BOM but doesn’t require it, then the presense of the BOM sequence will tell Notepad++ unambiguously what Unicode-compatible encoding is being used
- If you tell/allow Notepad++ to guess (by using the Settings > Preferences > MISC
autodetect character encodingsetting), Notepad++ will try some heuristics to guess the encoding, but it’s often wrong. It’s often recommended you disable that setting in posts in this Forum. - In the Settings > Preferences > New Document settings, if UTF-8 is chosen as your default encoding, you can also choose to always apply UTF-8 interpretation to files that Notepad++ opens and guesses are ANSI, not just to new files.
- If it’s guessed wrong, or your default selections are wrong for a given file, then you can manually change the encoding back to what it should be. Notepad++ will remember this selection until you close the file (even remembering it if you close Notepad++, as long as you are remembering the current session). However, once the file leaves the current session, Notepad++ no longer tracks what encoding you had chosen for a file, so you’ll have to tell it again. But you can do it every time, with no loss in information.
Please note: the legacy “ANSI” encoding (which is incorrectly named), and any of the “character set” options are all that: legacy. In the ancient world of 80s and early-90s computing, you had to use a variety of 8-bit encodings for different character sets, depending on where you were in the world. But then Unicode was invented, and in the intervening 2 decades has become the standard for representing characters in a compatible way. The only reason for ever choosing a non-Unicode encoding is to maintain compatibility with some legacy application that still insists on doing things the old way, or because you’re on a computer with an OS too old to handle any Unicode encoding – and if the latter is the case, your OS is too old to run Notepad++. If you are tied to a legacy encoding because of some other product, I recommend converting to and storing in UTF-8 (with or without BOM) while you’re using the files in Notepad++, and only converting back to “ANSI” when you’re passing it back to the legacy app.
-
@PeterJones
Nice lesson.
You mean it is my problem I presume. -
Thank you,
I apologize,When in Settings > Preferences > MISC - Autodetect character encoding setting
is disabled Notepad++ can read the file.It should be possible to disable this option for the file opened in
Encodage (Coding) of the top menu ? -
@PeterJones
In fact, with Autodetect character encoding, it is possible to read the file.
Click on Encodage of the top menu and then specify
Character encoding - Western european languages - Windows-1252.
. -
@jfaset
Notepad ++ has a lifelong problem with ANSI encodings. -
What @PeterJones was trying to tell you was that autodetection of an encoding is not always possible because there is no way to tell with 100% certainty which encoding a file is in.
This is because it is possible for the same file of raw bytes to potentially be valid sequences in several different encodings at the same time.
It might be interesting to see if a script could be written to pair a user’s previous filepath on a file with an (user-chosen!) encoding in some sort of database. If a file is closed and reopened, the database would be consulted to see what the chosen encoding should be.
This sounds familiar. I wonder if there is already a plugin for doing this…
Notepad ++ has a lifelong problem with ANSI encodings.
What does this mean?
In the context of what @PeterJones and I have stated about autodetection of encoding? -
In my opinion, I made myself very clear about the problems with ANSI encodings. My native language is Russian and I face ANSI encoding problems every day. Very often you have to correct the incorrect saving of the encoding through the AkelPad editor, while Notepad ++ breaks the encoding and it is not always possible to recover this file!
-
is your windows system also setup with Russian language pack?
If so, by disabling autodetect chacacter encoding you shouldn’t have any issues with cp1251 encoded files.
Afaik npp uses your os encoding if you haven’t configured something else. -
@Ekopalypse
Automatic encoding detection is always disabled for me. And when I need to reopen in the desired encoding, and Notepad ++ does the re-saving of the document without the possibility of rollback. So in such a situation, I need to do it in another editor, so as not to irrevocably lose this file. For example, AkelPad4 editor never breaks the Russian encoding. -
If you open a file, what shows npp in the statusbar? ANSI or cp1251?
-
@Ekopalypse
Example:
Initially the file is encoded OEM 866And notepad ++ opens up different options: Macintosh, Windows-1251, ANSI, UTF-8
-
Hmmm … why should npp do this if you have automatic encoding detection disabled? Strange, it does not do this for me.
Is OEM866 much different to cp1251? -
I am interested in how this conversation turns out.
I would like to know if there is a bug with this or not.
Note that I would not consider N++'s lack of autodetection of what the user thinks is the correct encoding a bug, but I would if the user sets and encoding, saves a file, and somehow N++ messes that up. -
@Ekopalypse
@Alan-Kilborn
My file is OEM 866 and notepad ++ opens it as Macintosh, Windows-1251, ANSI, UTF-8 (options are always different)For bat files, I need exactly the OEM 866 encoding.
(sorry for my google translate) -
Если Вы отключили автоматическое распознавание и используете набор символов, противоречащий Вашим настройкам “ANSI”, блокнот++ не сможет отобразить документ в правильном формате.
Вот пример:
Я использую OEM850 и сохранил этот текст: “Неприятности в раю”.
Если я сейчас запущу блокнот++ и открою файл, то блокнот++ покажет мне это.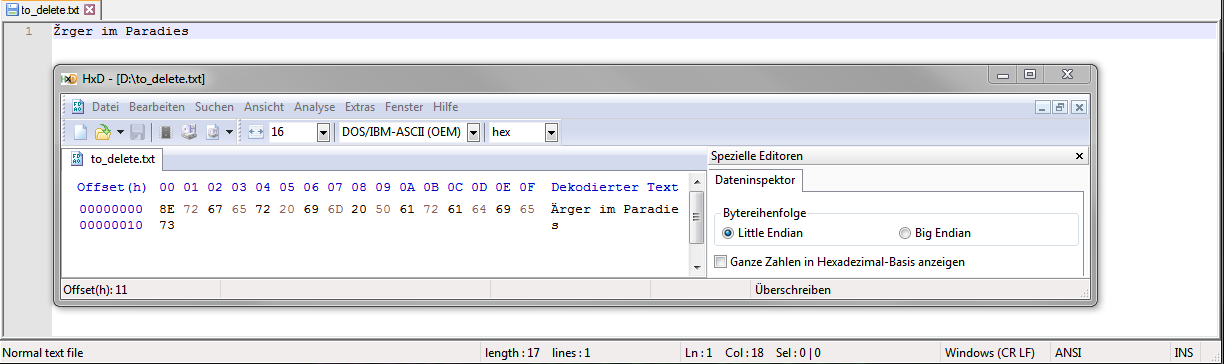
Он использует настройку операционной системы ANSI, которой для меня является CP1251.
Это нормально, но блокнот++ всегда сообщает ANSI и больше ничего.
Тот факт, что ты сообщаешь о разных вещах, вот что путает меня с твоим заявлением.
Почему ANSI не всегда отображается? Странно. -
Конечно, моя кодировка 1252, а не 1251.
-
In my humble opinion this is a user interface failure.
What is the meaning of disable autodetect character encoding? If Notepad++ does not autodetect then it must assume some default. What is this default? – I tested and it is not the new file encoding.The UI should have had a radio button that selects one of two options:
- Autodetect character encoding.
- Assume any opened files is <combo box>
There could be more advanced features like letting the user select a group of acceptable encodings for his region where Notepad++ must guess one of them. But that goes beyond UI.