Identical strings in column
-
Hi, @petr-jaja, @peterjones, @astrosofista, @alan-kilborn and All,
@astrosofista, thanks for your insight, but I worked on my side and I’ve found out a coherent explanation which means that is, finally, a predictable bug !
Yes, I’m glad because I find out the algorithm which fully explains how the
column-modesort behaves ;-))
-
First, it only concerns the
TABcharacters, located before the position of your zero-lengthcolumn-modeselection. Now : -
For each
TABcharacter, estimate the numbernof positions, taken by theTABcharacter and, then, note the numbern - 1 -
Add up all these numbers
n- 1( so,n1 - 1+n2 - 1+n3 - 1+ … =S)
This sum
Sis the offset between the user columnCuof your zero-length selection AND the real columnCr, used to perform thecolumn-modesort. Hence the relationCr = Cu + S
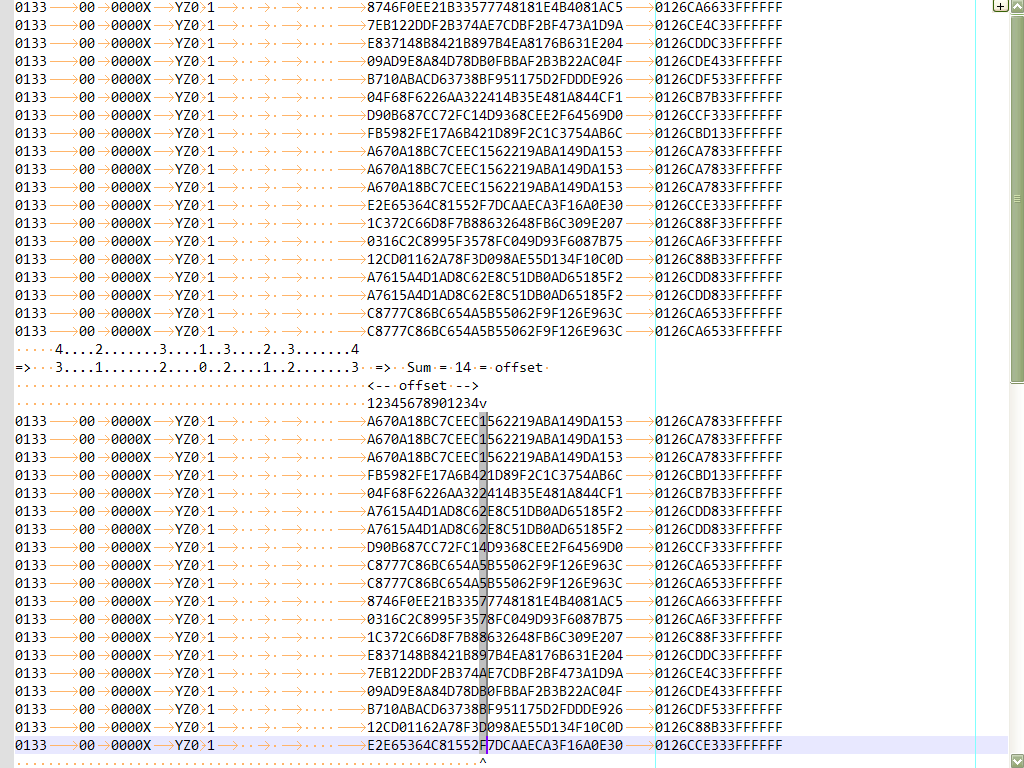
One example ( refer to the picture, below )
-
The first table, before the sort, with a zero-length column-mode selection, at column
45 -
The second table, after the sort, is not sorted, obviously, at column
45 -
Each line contains
8tabulations before column45 -
The positions, taken by each tabulation, are, respectively,
4,2,3,132,3and4 -
So, the numbers
n - 1are, respectively,3,1,2,021,2and3 -
The sum of all these “
n - 1” numbers is14 -
So, although you think to sort at column
45, where you did thecolumn-modeselection, the effective sort will begin at column
45 + 14, so at column59of each line ! ( The column-selected column, in the picture )
Best Regards
guy038
P.S. :
-
I also verified that, after changing the number of positions for tabulations, in
normaltext, either below or above the default value4, in thePreferencesdialog, my algorithm is still correct and always gives, in all cases, the real column of the sort ! -
Text in an
ANSIencoded file, is sorted, using this same algorithm, too
Oh, I forgot to give the raw text :
0133 00 0000X YZ0 1 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF 0133 00 0000X YZ0 1 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF 0133 00 0000X YZ0 1 E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF 0133 00 0000X YZ0 1 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF 0133 00 0000X YZ0 1 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF 0133 00 0000X YZ0 1 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF 0133 00 0000X YZ0 1 D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF 0133 00 0000X YZ0 1 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF 0133 00 0000X YZ0 1 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 0133 00 0000X YZ0 1 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 0133 00 0000X YZ0 1 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 0133 00 0000X YZ0 1 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF 0133 00 0000X YZ0 1 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF 0133 00 0000X YZ0 1 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF 0133 00 0000X YZ0 1 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF 0133 00 0000X YZ0 1 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 0133 00 0000X YZ0 1 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 0133 00 0000X YZ0 1 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 0133 00 0000X YZ0 1 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF
Last thought :
If you intend to use a
column-modeselection for a sort, starting at a specific column, the best would be to run, first, aEdit > Blank Operations > TAB to Spacecommand in order to delete anytabulationcharacter, without changing the presentation of the text ! -
-
So something smells bad here, and it isn’t just tab characters.
I looked at @guy038 's data, from the post where he said:

If I paste this data into a new tab, and convert tabs-to-spaces (to forget about tabs for now), I get something that appears like this:

If I then try to make a zero-width column selection, it looks like this:
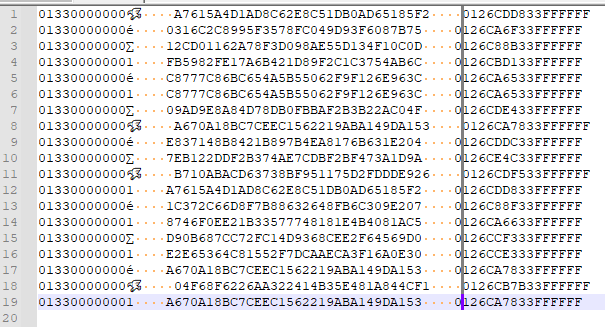
But this isn’t right…the column caret should be to the left of the leading zero of the third column of data for the entire block, but it isn’t.
Thus if I attempt a sort, I definitely don’t obtain what I intend.
And no tabs involved.
This problem goes deeper than sorting, I think this is a Scintilla problem.
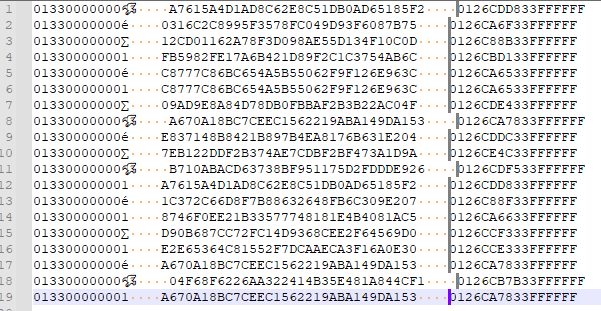
Just because the “little birdie” appears to take up two columns, he doesn’t–he’s only one character, just like all the rest of the final characters in column 1 of the data.The following is what a proper column selection should look like for this data:
-
Hello,
Great :-) It looks very nice. I have tested three files and the algorithm worked fine. I have found there only one problem. If there are more than two equal strings in the file, the sequence 3 indicates only first two of them.
Tested on v.7.9.3 - 32bit -
Thanks for this idea.
I have used at first TextFX Tools – sort lines by column and then marking lines according to your solution. Option A looks most suitable for my issue.
Tested on v.7.9.3 - 32bit -
Hello @alan-kilborn,
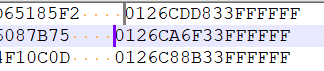
As you can see, in the picture below, sometines, even with
Monospacedfonts, some characters as the∑and other symbols like🦅do not have the same width than standardANSIcharacters, when displayed in Notepad++ !The raw text is :
01330000000🦅 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 01330000000é 0316C2C8995F3578FC049D93F6087B75 0126CA6F33FFFFFF 01330000000∑ 12CD01162A78F3D098AE55D134F10C0D 0126C88B33FFFFFF 013300000001 FB5982FE17A6B421D89F2C1C3754AB6C 0126CBD133FFFFFF 01330000000é C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 013300000001 C8777C86BC654A5B55062F9F126E963C 0126CA6533FFFFFF 01330000000∑ 09AD9E8A84D78DB0FBBAF2B3B22AC04F 0126CDE433FFFFFF 01330000000🦅 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 01330000000é E837148B8421B897B4EA8176B631E204 0126CDDC33FFFFFF 01330000000∑ 7EB122DDF2B374AE7CDBF2BF473A1D9A 0126CE4C33FFFFFF 01330000000🦅 B710ABACD63738BF951175D2FDDDE926 0126CDF533FFFFFF 013300000001 A7615A4D1AD8C62E8C51DB0AD65185F2 0126CDD833FFFFFF 01330000000é 1C372C66D8F7B88632648FB6C309E207 0126C88F33FFFFFF 013300000001 8746F0EE21B33577748181E4B4081AC5 0126CA6633FFFFFF 01330000000∑ D90B687CC72FC14D9368CEE2F64569D0 0126CCF333FFFFFF 013300000001 E2E65364C81552F7DCAAECA3F16A0E30 0126CCE333FFFFFF 01330000000é A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFF 01330000000🦅 04F68F6226AA322414B35E481A844CF1 0126CB7B33FFFFFF 013300000001 A670A18BC7CEEC1562219ABA149DA153 0126CA7833FFFFFFSo,if your going to use the
colum-modefeature, I think that the best is to switch, first, to a classical true monospaced font, likeConsolasorCourier New!
Best Regards
guy038
-
@guy038 said in Identical strings in column:
if … use the column-mode feature, … best is to switch … to … true monospaced font, like … Courier New !
So I’m confused.
My screenshots in my immediately previous post WERE made with the font set to Courier New.So remembering that I’ve converted all tabs to spaces, if I put my caret here:

and I press Shift+Alt+downArrow, I should get this:
because that is the only way to keep the same number of characters to the left of both carets in their respective lines.
But what I actually obtain is this:
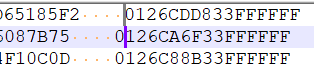
which puts 52 characters to the left of the caret on line 1, and 53 characters to the left of the caret on line 2. And for a column mode selection this makes no sense. It is like it is doing it on a visual basis…and what good is that?!
So as an example that should really hammer this home, what if I insert a character, for example, an
a. Here’s what happens: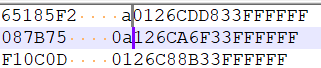
That’s wrong!
-
Hi, @alan-kilborn,
Don’t be bothered by my reply. Results can be different because of:
-
My old
Win XPmachine -
Old versions of some of my fonts
-
The
substitutionfonts, used by the system, to display particularUnicodeblocks -
The
fallbackfont used by the system
So, just be patient, for a while, and we’ll speak about this later, when I finally get this bloody
Win 10laptop ;-)) Otherwise, I’ll won’t be able to follow the latest N++ releases, any more !BR
guy038
-
-
Hmmm, well, Courier New seems to be about as “vanilla” as one can get, given that it is the default font in Notepad++, and every Windows computer since time began has it (I suppose).
It seems like a non-power user trying to do what I’ve shown, is going to encounter a similar problem, and complain. I guess it is debatable whether or not a non-power user is going to be doing column blocking, but maybe not out of the question.
I’m willing to keep talking about this (if there’s more to say), in the context of your old computer, because I feel this has been in existence in N++ for a long time, so such discussions should be valid.
-
Sorry. I thought briefly about that condition when I started, but I didn’t notice your 3+ example in your data when I was debugging my answer, so forgot.i am on my phone now. Maybe later today, I will get a chance to be on the computer and work on this more.
Also, maybe @guy038 solution would work better for you. ( I haven’t tried it. )
-
@Petr-Jaja said in Identical strings in column:
If there are more than two equal strings in the file, the sequence 3 indicates only first two of them.
Okay, I found a workaround. I tried a clever alternation with \K on one of them, or anchoring on \G, but that wasn’t working easily. So, as I often do for practical solutions rather than optimized solutions, I added another step.
Step 4 (as listed above) will catch 2, or 4, or 6, or any even number of replicated rows. But any odd number of rows will miss the last row. So added a step 4b:
- Find What =
(?-s)^([[:alnum:]]{32}).✗\x20{3}.*\R\K\1\x20{5}
Replace With =$1\x20✗\x20\x20\x20
This will take care of the odd rows out. (I tried on 2,3,4,5,6, and 7 repeats, and I see no reason it woudn’t work beyond that)
Someone cleverer than I am might be able to come up with the magical formula to reduce the number of steps. And that’s great if you’re writing an application that will be running the regex millions of times, where the efficiency improvement might save significant time (and thus money) over the lifetime of the regex. But for a sequence that you’re just running once, or only occasionally on a small number of rows, efficiency isn’t the most important.
- Find What =
-
I also tried @guy038 solution from his “I think that a solution, in fewer steps, should be possible !” post: it worked first try, without modification, on your example data, or on data modified to have two, three, four, five, six, and seven repeat rows (and thus there is no reason it shouldn’t on reasonable n>7). So his should work for you, too.
-
I have tested your solutions and both work fine. However, for futher work I will use probably the solution from @guy038 because it is a little bit faster.
Thank you very very much for your help.Tested - NP v.7.9.3 on Win10, Win7