Search for character classes but not replace them
-
Hi there!
I want to replace every “2” appearing between two letters with a “4”. I searched for [:alpha:]2[:alpha:] but how do I replace only the “2” in the middle and keep the two letters around it unchanged?
Maybe a dumb question but I couldnt really find a straightforward answer to this in the user manual’s Substitutions section…
Thanks in advance! :)
-
You could use lookbehind and lookahead assertions, like so:
(?<=[[:alpha:]])2(?=[[:alpha:]])Assertion matches aren’t part of the “real” match.
Also, not sure why you show only single
[and]in your posting – that isn’t going to work for what you’re trying to do. -
There are multiple ways of doing it.
You could put the alpha’s in capture groups, with
([[:alpha:]])2([[:alpha:]]), then use a substitution of${1}4${2}which will insert the contents of the first group using the ${ℕ} substitution escape sequence, then the literal4, then the contents of the second group.Alternately, you could use lookahead and lookbehind assertions in the search expression to require that the characters are there, but don’t include them in the “matched text” for the replacement:
(?<=[[:alpha:]])2(?=[[:alpha:]])with a replacement of4(the links go to the appropriate section of https://npp-user-manual.org/docs/searching/)
-
@Alan-Kilborn, @PeterJones Thanks a lot, that worked! Thanks also for pointing towards the relevant passages of the user manual :)
-
@Alan-Kilborn said in Search for character classes but not replace them:
Also, not sure why you show only single [ and ] in your posting – that isn’t going to work for what you’re trying to do.
@Benjamin-Sasse , in case you check back… This is a subtle issue, that depending on your “test data” might not have come up.
[:alpha:]is a normal character class which will match any one of the literal characters:,a,l,p, orh. If your test expression wasa2a, you would have thought it was working.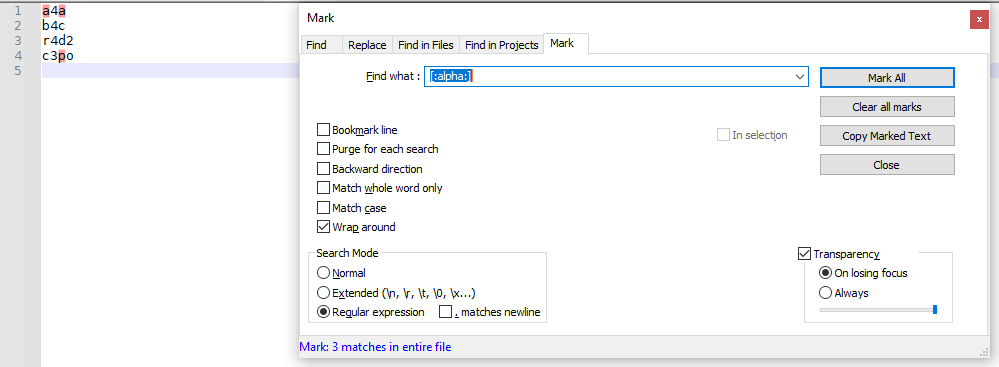
[[:alpha:]]is a named character class, which will match any alphabetic characters:
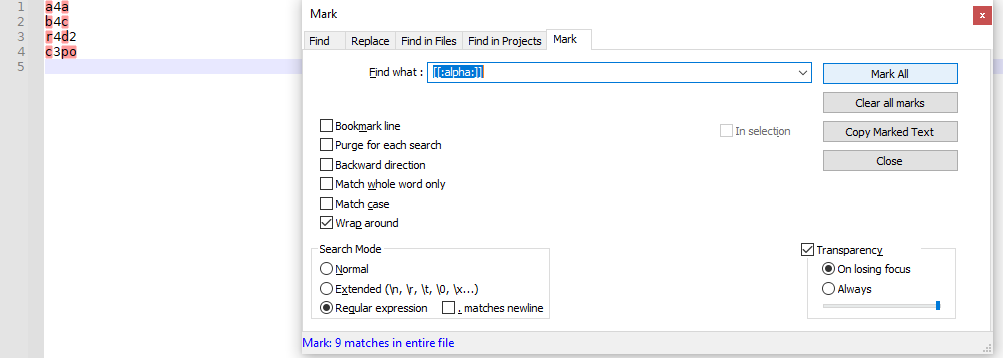
The usermanual tries to emphasize the need for both brackets for the named character class, but there’s a lot to read, so you might not have noticed that.
-
Hello @benjamin-sasse, @peterjones, @alan-kilborn, and All
I think that true
Posixcharacter classes are, indeed, defined as[:xxxxxx:]However, the important point is that a
Posixcharacter class is active ONLY IF it is contained in a standard character class !
So, for instance, the character class
(?-i)[AB[:digit:]x-z]would match, either :-
The uppercase letter
AorB -
Any single digit from
0to9 -
The lowercase letter
x,yorz
As you can see, the outer character class contains two distinct values
AandB, aPosixcharacter class[:digit:]and, finally, a range of charactersx-z
Thus, the negative class character
(?-i)[^AB[:digit:]x-z]would match any character different from[AB0123456789xyz]If a
Posixcharacter class is used alone, within a standard character class, two syntaxes are possible for the negative form :[^[:.....:]]or[[:^.....:]]For instance, all these regexes are equivalent :
[^[:word:]]=[[:^word:]]=[^[:w:]]=[[:^w:]]=\W=[^_\d\l\u]
Our
Boostregex engine handles the15character classesPosix, below, when embedded in a standard positive or negative character class :[:space:] [:digit:] [:lower:] [:upper:] [:word:] [:blank:] [:v:] [:alnum:] [:alpha:] [:cntrl:] [:graph:] [:print:] [:punct:] [:xdigit:] [:unicode:]Best Regards,
guy038
-
-
@guy038 just for understanding : the posix character class
[:unicode:]can only contain characters of the basic posix character set “portable character set” (256 characters) ? maybe outdated , but regex buddy only lists 12 posix character classeshttps://www.regular-expressions.info/posixbrackets.html#class .uhmm , when i follow the npp-manual , guiding me to the boost - perl-regex 1.7.0 there are again other character classes , default always supported and ones that are unicode extended . https://www.boost.org/doc/libs/1_70_0/libs/regex/doc/html/boost_regex/syntax/perl_syntax.html https://www.boost.org/doc/libs/1_70_0/libs/regex/doc/html/boost_regex/syntax/character_classes/std_char_classes.html https://www.boost.org/doc/libs/1_70_0/libs/regex/doc/html/boost_regex/syntax/character_classes/optional_char_class_names.html .
but still my question is : can only the posix portable character set match the search posix character classes ? i wouldnt have cared about , but the “posix” definition now confuses me .
-
Hello, @carypt and all,
EDIT : Feb, 3 2025
- Firstly, Notepad++ uses the standard
Boostregex library, which is not compiled with fullUnicodesupport. Thus, all the regexes syntaxes of the page, below, in order to get all characters of a particularUnicode General Categorycategory, cannot be used and just output anInvalid regular expressionmessage ! Of course, we lose a functionality but, in return, we gain in speed of execution, as the regex engine does not have to distinguish the numerousUnicodecharacters and properties !
- Secondly, from the three links, below :
https://www.regular-expressions.info/posixbrackets.html#clas
https://en.wikipedia.org/wiki/Regular_expression#Character_classes
We deduce that our
Boostregex engine :-
Does not handle the
[[:ascii:]]Posix character class, which is not standard and which can easily be replaced with the[\x00-\x7F]regex -
Can handle the
[[:v:]]Posix character class, equivalent to\v, which is not a standardPosixclass and matches a vertical blank character, so the regex[\n\x0B\f\r\x85\x{2028}\x{2029}] -
Can handle the
[[:unicode:]]Posix character class. Apparently, after a lot ofGooglesearches, it does not seem to be aPosixstandard class ( An addition to theBoostregex library ? ). It matches any Unicode character which code-point over\x{00FF}Note, however, that the present N++ implementation misses all Unicode chars with code over\x{FFFF}, so all the characters over theBMP:-((
Its name seems also misnommed as, anyway, all characters are
Unicodecharacters ! Actually, it should be the class of all characters which do not belong to theC0 Control and Basic Latin (ASCII)andC1 Control and Latin-1 SupplementUnicode scripts andshould beis found with the regex[^\x00-\xFF]Unfortunately, given the above restriction, the right regex, in order to match any character with code-point over\x{00FF}, is, rather :(?![\x00-\xFF]).[\x{D800}-\x{DFFF}]?Best Regards,
guy038
- Firstly, Notepad++ uses the standard
-
@guy038 ty , for your detailed and elaborate answer . oh my , that question has caused much research i presume . excuse me . its a mess that all is dependent on widespread definitions .
so now i know npp has a faster speed for dropping higher unicode characters , ok , the main used chinese etc characters seem to be contained in the base multi plane of unicode .
i was interested in what characters are element of the set of posix character class (as in set theory). posix should give a set of characters for region specific needs , the set can be modified with localedef (in posix) and gives then a “posix locale” . the normal posix character set is the “portable character set” (103 characters).
i was interested if the posix-character-classes
[[:????:]]were only matching to these specific “posix locale”- set of characters . as for a not posix-supporting operating system like windows this would be obsolete anyway .i assume the posix character class is just another writing for a bracket expression
[??-??], just the posix-syntax of regular expression , not the perl-syntax. a better name would then be posix-syntax-character-class . ffff , it is just a boost-regex-implemented-syntax from posix . so it does not only match a posix-set of characters . excuse my misinterpretation .posix resource : https://pubs.opengroup.org/onlinepubs/9699919799/
posix locale : https://pubs.opengroup.org/onlinepubs/9699919799/
posix portable character set : https://pubs.opengroup.org/onlinepubs/9699919799/ -
Hi, @carypt,
Be patient ! I will answer you, later. Right now, I’m trying to build up a valid
UTF-8test file containing all the1,114,112Unicode code-points !BR
guy038
-
@guy038 ty , there is no need to answer , i think i got it now . i just confused the posix character set with the posix syntax for regexes , a kind of dumb mistake . sry
-
Hello, @carypt, @benjamin-sasse, @peterjones, @alan-kilborn and All,
Finally, I answer you !
First, you said :
so now i know npp has a faster speed for dropping higher unicode characters , ok , the main used chinese etc characters seem to be contained in the base multi plane of unicode .
This statement is not correct and, may be, I was misunderstood !
As I said, the fact to not use the full Unicode support with the N++ Boost regex implementation surely speed up the regex engine, but, in return, prevent us to use any the Unicode regex syntaxes, listed in this page :
However, we still should be able to get the individual characters, with code-point over the
BMPplane, with the logical syntax\x{.....}
( from\x{10000}to\x{10FFFF})Luckily we can access to an individual character, over the
BMP, by using thesurrogatemechanism ! For instance, to match the🚂character (STEAM LOCOMOTIVE), with Unicode code-pointU+1F682, we can use the couple\x{D83D}\x{DE82}as the valuesD83DandDE82represent the high and lowsurrogatepair, of theUTF-16encoding of the code-pointU+1F682!
As I said, in my short previous post, I succeeded to create an
UTF-8-BOMencoded file containing all existing Unicode characters. But, unlike I said, I don’t have to store all the Unicode characters (1,114,112) as :-
Some zones are forbidden, as definitively declared
NON-Characterszones by the Unicode Consortium -
The Surrogates zone (
[\x{D800}-\x{DFFF}]), used to code the characters over theBMPin anUTF-16encoded file are forbidden -
Some Unicode planes ( Planes
3to14) are totally empty, as not used, up to now and probably for a long time -
The Unicode planes
15and16, standing for theSupplementary Private Use Areas, are generally not used, either
Here is a table which recapitulates the layout of all the Unicode characters :
•--------------------•-------------------•------------•---------------------------•------------•-------------------• | Range | Description | Status | Number of Chars | Encoding | Number of Bytes | •--------------------•-------------------•------------•-------------•-------------•------------•-------------------• | 0000 - 007F | PLANE 0 - BMP | Included | | 128 | 1 Byte | 128 | •--------------------•-------------------•------------•-------------•-------------•------------•-------------------• | 0080 - 0FFF | PLANE 0 - BMP | Included | | + 1.920 | 2 Bytes | 3,840 | •--------------------•-------------------•------------•-------------•-------------•------------•-------------------• | 0800 - D7FF | PLANE 0 - BMP | Included | | + 53,248 | | 159,744 | | | | | | | | | | D800 - DFFF | SURROGATES zone | EXCLUDED | - 2.048 | | | | | | | | | | | | | E000 - F8FF | PLANE 0 - PUA | Included | | + 6,400 | | 19,200 | | | | | | | | | | F900 - FDFC | PLANE 0 - BMP | Included | | + 1,232 | 3 Bytes | 3,696 | | | | | | | | | | FDD0 - FDEF | NON-characters | EXCLUDED | - 32 | | | | | | | | | | | | | FDF0 - FFFD | PLANE 0 - BMP | Included | | + 526 | | 1,578 | | | | | | | | | | FFFE - FFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------•------------•-------------------• | Plane 0 - BMP | SUB-Totals | - 2,082 | + 63,454 | / | 188,186 | •--------------------•-------------------•------------•-------------•-------------•------------•-------------------• | 10000 - 1FFFD | PLANE 1 - SMP | Included | | + 65,534 | | 262,136 | | | | | | | | | | 1FFFE - 1FFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------• •-------------------• | 20000 - 2FFFD | PLANE 2 - SIP | Included | | + 65,534 | | 262,136 | | | | | | | 4 Bytes | | | 2FFFE - 2FFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------• •-------------------• | 30000 - 3FFFD | PLANE 3 - TIP | Included | | + 65,534 | | 262,136 | | | | | | | | | | 3FFFE - 3FFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------•------------•-------------------• | 40000 - DFFFF | PLANES 4 to 13 | NOT USED | - 655,360 | | 4 Bytes | | •--------------------•-------------------•------------•-------------•-------------•------------•-------------------• | E0000 - EFFFD | PLANE 14 - SPP | Included | | + 65,534 | | 262,136 | | | | | | | | | | EFFFE - EFFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------• •-------------------• | FFFF0 - FFFFD | PLANE 15 - SPUA | NOT USED | - 65,334 | | | | | | | | | | | | | FFFFE - FFFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------• 4 Bytes •-------------------• | 100000 - 10FFFD | PLANE 16 - SPUA | NOT USED | - 65,334 | | | | | | | | | | | | | 10FFFE - 10FFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------•------------•-------------------• | GRAND Totals | - 788,522 | + 325,590 | | 1,236,730 | | | | | | | | Byte Order Mark - BOM | | | / | 3 | •-----------------------------------------------------•-------------•-------------• •-------------------• | | 1,114,112 Unicode chars | | Size 1,236,733 | •-----------------------------------------------------•---------------------------•------------•-------------------•Refer here for additional information
Thus, I’m left with a file with size
1,236,733and containing, exactly,325,590Unicode characters. Of course, depending on the current font used, it is generally not able to display the glyphs of all the characters ! But, it doesn’t matter because we just want to know which, and how many, characters are matched by a specific,POSIXor not,Character class;-))I close this post because any post is limited to
16,000bytes about ! -
-
Hi, @carypt, @benjamin-sasse, @peterjones, @alan-kilborn and All,
Continuation of the discussion :
Now, from this page, here is the summary list of the
15availableCharacter class, known of ourBoostregex engine :•=========================•===============================•==============•===========•===========================================•===============================================================================================================================================• | INSIDE a Class [....] | OUTSIDE a Class [....] | EVERYTHERE | Total | SIMPLIFIED and / or APPROXIMATIVE regex | EXACT or Win-1252-EQUIVALENT regex | •=========================•===============================•==============•===========•===========================================•===============================================================================================================================================• | [:alpha:] | \p{alpha} | | | | 45,813 | (?i)[A-Z] | [^\W\d\x5f] | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:digit:] | [:d:] | \p{digit} | \p{d} | \pd | \d | 201 | [0-9] | [0-9¹²³.....] or [0-9¹²³] ( with "Win-1252" Encoding ) | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:alnum:] | \p{alnum} | | | | 46,014 | (?i)[0-9A-Z] | [^\W\x5f] | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:word:] | [:w:] | \p{word} | \p{w} | \pw | \w | 46,015 | (?i)[0-9_A-Z] | [[:alnum:]\x5F] | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:punct:] | \p{punct} | | | | 334 | (?!\w)[[:graph:]] | [!"#$%&'()*+,-./:;<=>?@[\\]^`{|}~‚„…†‡‰‹‘’“”•–—›¡¢£¤¥¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿×÷] ( with "Win-1252" Encoding ) | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:graph:] | \p{graph} | | | | 46,342 | [[:punct:]\w] | (?!ªº_¹²³µ)[[:punct:]]|[[:word:]] or [^[:^punct:][:^word:]] | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:print:] | \p{print} | | | | 46,368 | [[:punct:]\w\s] | [[:space:][:graph:]\x{FEFF}] | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:space:] | [:s:] | \p{space} | \p{s} | \ps | \s | 25 | [\t\n\r\x20] | [\t\n\x0B\f\r\x20\x85\xA0\x{1680}\x{2000}-\x{200B}\x{2028}\x{2029}\x{202F}\x{3000}] | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:h:] | \p{h} | \ph | \h | 18 | [\t\x20] | [\t\x20\xA0\x{1680}\x{2000}-\x{200B}\x{202F}\x{3000}] | •-------------------------•-----------------------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:v:] | \p{v} | \pv | \v | 7 | [\r\n] | [\n\x0b\f\r\x85\x{2028}\x{2029}] | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:upper:] | [:u:] | \p{upper} | \p{u} | \pu | \u | 717 | (?-i)[A-Z] | (?-i)[A-ZŠŒŽŸÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞ..........] or (?-i)[A-ZŠŒŽŸÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞ] ( with "Win-1252" Encoding ) | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:lower:] | [:l:] | \p{lower} | \p{l} | \pl | \l | 835 | (?-i)[a-z] | (?-i)[a-zƒšœžªµºßàáâãäåæçèéêëìíîïðñòóôõöøùúûüýþÿ.....] or (?-i)[a-zƒšœžªµºßàáâãäåæçèéêëìíîïðñòóôõöøùúûüýþÿ] ( with "Win-1252" Encoding ) | •---------------•---------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:cntrl:] | \p{cntrl} | | | | 89 | [\x00-\x1F\x7F\x80-\x9F] | [\x00-\x1F\x7F\x80-\x9F\x{070F}\x{180B}-\x{180E}\x{200C}-\x{200F}\x{202A}-\x{202E}\x{206A}-\x{206F}\x{FEFF}\x{FFF9}-\x{FFFB}] | •-------------------------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:xdigit:] | \p{xdigit} | | | | 44 | (?i)[A-F0-9] | (?i)[A-F0-9\x{FF10}-\x{FF19}\x{FF21}-\x{FF26}] | •-------------------------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:blank:] | \p{blank} | | | | 5 | [\t\x20\xA0] | [\t\x20\xA0\x{3000}\x{FEFF}] | •-------------------------•-------------•---------•-------•--------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | [:unicode:] | \p{unicode} | | | | 325,334 | [^\x00-\xFF] | [^\x00-\xFF] | •------------------------------------------------------------------------•-----------•-------------------------------------------•-----------------------------------------------------------------------------------------------------------------------------------------------• | ANY Unicode character | 325,590 | (?s). | (?s). | •========================================================================•===========•===========================================•===============================================================================================================================================•Notes :
-
As you can see, the regex syntaxes are different according to the location of the
Character class! -
The Total column shows the number of characters, matched by the respective
Character class, out of the325,590characters -
To express a negative
Character class, use the syntax :-
[:^class:]or[:^c:]when thisPOSIXclass is located inside a classical[.....]Character class -
\P{class}or\P{c}or\Pc, when located outside a classical[.....]Character class -
\<Uppercase_letter>, whatever its location
-
-
If a
POSIXclass is isolated into aCharacter class, you can use, either, the[^[:class:]]or[^[:class:]]syntax
Between
Character Classes, we have the following mathematical relations :-
[[:alnum:]]=[[alpha:]]+[[digit:]] -
[[word:]]=[[:alnum:]]+\x5F(_char ) -
[[:graph:]]=[[:punct:]]-[ªº_¹²³µ]+[[word:]] -
[[:print:]]=[[:space:]]+[[:graph:]]+\x{FEFF}( ZWNBSP = Zero_With_No_Break_Space ) -
[[:space:]]=[[:h:]]+[[:v:]] -
[[unicode:]]= <All> (325,590) - First256( from\x00to\xFF)
See you in next post !
-
-
Hi, @carypt, @benjamin-sasse, @peterjones, @alan-kilborn and All,
End of the discussion :
Now, our
Boostregex engine correctly handles the Collating symbol syntax ([.•••••.])Here is the table of all the available
POSIXsymbolic names, as described here•============================•============================•=============•=============•=============• | POSIX symbolic name | ESCAPED symbolic name | Character | DEC value | HEX Value | •============================•============================•===========================•=============• | [.NUL.] | \N{NUL} | NUL | 000 | \x00 | | [.SOH.] | \N{SOH} | SOH | 001 | \x01 | | [.STX.] | \N{STX} | STX | 002 | \x02 | | [.ETX.] | \N{ETX} | ETX | 003 | \x03 | | [.EOT.] | \N{EOT} | EOT | 004 | \x04 | | [.ENQ.] | \N{ENQ} | ENQ | 005 | \x05 | | [.ACK.] | \N{ACK} | ACK | 006 | \x06 | | [.alert.] | \N{alert} | BEL | 007 | \x07 | | [.backspace.] | \N{backspace} | BS | 008 | \x08 | | [.tab.] | \N{tab} | TAB | 009 | \x09 | | [.newline.] | \N{newline} | LF | 010 | \x0A | | [.vertical-tab.] | \N{vertical-tab} | VT | 011 | \x0B | | [.form-feed.] | \N{form-feed} | FF | 012 | \x0C | | [.carriage-return.] | \N{carriage-return} | CR | 013 | \x0D | | [.SO.] | \N{SO} | SO | 014 | \x0E | | [.SI.] | \N{SI} | SI | 015 | \x0F | | [.DLE.] | \N{DLE} | DLE | 016 | \x10 | | [.DC1.] | \N{DC1} | DC1 | 017 | \x11 | | [.DC2.] | \N{DC2} | DC2 | 018 | \x12 | | [.DC3.] | \N{DC3} | DC3 | 019 | \x13 | | [.DC4.] | \N{DC4} | DC4 | 020 | \x14 | | [.NAK.] | \N{NAK} | NAK | 021 | \x15 | | [.SYN.] | \N{SYN} | SYN | 022 | \x16 | | [.ETB.] | \N{ETB} | ETB | 023 | \x17 | | [.CAN.] | \N{CAN} | CAN | 024 | \x18 | | [.EM.] | \N{EM} | EM | 025 | \x19 | | [.SUB.] | \N{SUB} | SUB | 026 | \x1A | | [.ESC.] | \N{ESC} | ESC | 027 | \x1B | | [.IS4.] | \N{IS4} | FS | 028 | \x1C | | [.IS3.] | \N{IS3} | GS | 029 | \x1D | | [.IS2.] | \N{IS2} | RS | 030 | \x1E | | [.IS1.] | \N{IS1} | US | 031 | \x1F | | [.space.] | \N{space} | SP | 032 | \x20 | | [.exclamation-mark.] | \N{exclamation-mark} | ! | 033 | \x21 | | [.quotation-mark.] | \N{quotation-mark} | " | 034 | \x22 | | [.number-sign.] | \N{number-sign} | # | 035 | \x23 | | [.dollar-sign.] | \N{dollar-sign} | $ | 036 | \x24 | | [.percent-sign.] | \N{percent-sign} | % | 037 | \x25 | | [.ampersand.] | \N{ampersand} | & | 038 | \x26 | | [.apostrophe.] | \N{apostrophe} | ' | 039 | \x27 | | [.left-parenthesis.] | \N{left-parenthesis} | ( | 040 | \x28 | | [.right-parenthesis.] | \N{right-parenthesis} | ) | 041 | \x29 | | [.asterisk.] | \N{asterisk} | * | 042 | \x2A | | [.plus-sign.] | \N{plus-sign} | + | 043 | \x2B | | [.comma.] | \N{comma} | , | 044 | \x2C | | [.hyphen.] | \N{hyphen} | - | 045 | \x2D | | [.period.] | \N{period} | . | 046 | \x2E | | [.slash.] | \N{slash} | / | 047 | \x2F | | [.zero.] | \N{zero} | 0 | 048 | \x30 | | [.one.] | \N{one} | 1 | 049 | \x31 | | [.two.] | \N{two} | 2 | 050 | \x32 | | [.three.] | \N{three} | 3 | 051 | \x33 | | [.four.] | \N{four} | 4 | 052 | \x34 | | [.five.] | \N{five} | 5 | 053 | \x35 | | [.six.] | \N{six} | 6 | 054 | \x36 | | [.seven.] | \N{seven} | 7 | 055 | \x37 | | [.eight.] | \N{eight} | 8 | 056 | \x38 | | [.nine.] | \N{nine} | 9 | 057 | \x39 | | [.colon.] | \N{colon} | : | 058 | \x3A | | [.semicolon.] | \N{semicolon} | ; | 059 | \x3B | | [.less-than-sign.] | \N{less-than-sign} | < | 060 | \x3C | | [.equals-sign.] | \N{equals-sign} | = | 061 | \x3D | | [.greater-than-sign.] | \N{greater-than-sign} | > | 062 | \x3E | | [.question-mark.] | \N{question-mark} | ? | 063 | \x3F | | [.commercial-at.] | \N{commercial-at} | @ | 064 | \x40 | | [.A.] | \N{A} | A | 065 | \x41 | | ....... | ........ | ... | ..... | ...... | | [.Z.] | \N{Z} | Z | 090 | \x5A | | [.left-square-bracket.] | \N{left-square-bracket} | [ | 091 | \x5B | | [.backslash.] | \N{backslash} | \ | 092 | \x5C | | [.right-square-bracket.] | \N{right-square-bracket} | ] | 093 | \x5D | | [.circumflex.] | \N{circumflex} | ^ | 094 | \x5E | | [.underscore.] | \N{underscore} | _ | 095 | \x5F | | [.grave-accent.] | \N{grave-accent} | ` | 096 | \x60 | | [.a.] | \N{a} | a | 097 | \x61 | | ....... | ........ | ... | ..... | ...... | | [.z.] | \N{z} | z | 122 | \x7A | | [.left-curly-bracket.] | \N{left-curly-bracket} | { | 123 | \x7B | | [.vertical-line.] | \N{vertical-line} | | | 124 | \x7C | | [.right-curly-bracket.] | \N{right-curly-bracket} | } | 125 | \x7D | | [.tilde.] | \N{tilde} | ~ | 126 | \x7E | | [.DEL.] | \N{DEL} | DEL | 127 | \x7F | •============================•============================•=============•=============•=============•Notes :
-
The case of the symbolic name must be exactly respected !
-
The POSIX
[.•••.]syntax must be used inside a classicalCharacter class, only -
The
\N{...}syntax can be used whatever its location -
A
POSIXsymbolic name can also represents the character itself !
Examples :
-
[[.IS2.]]represents the RECORD SEPARATOR (RS) character, of code\x1E -
\N{plus-sign}is the+sign, of code\x2B -
[\N{number-sign}[.six.][.].]]represents the#sign or the6digit or the closing bracket]
As you can see, @carypt, this above list respects, exactly, the
Portable character Setnorm, as described in these articles :https://en.wikipedia.org/wiki/Portable_character_set
https://pubs.opengroup.org/onlinepubs/009695399/basedefs/xbd_chap06.html
Our
Boostregex engine also knows somedigraphs, when used as acollatingname :•----------•----------•------------------------------------------------• | Regex | Digraph | Origin | •----------•----------•------------------------------------------------• | [.AE.] | AE | | | [.Ae.] | Ae | Latin ligature | | [.ae.] | ae | | •----------•----------•------------------------------------------------• | [.CH.] | CH | | | [.Ch.] | Ch | Spanish | | [.ch.] | ch | | •----------•----------•------------------------------------------------• | [.DZ.] | DZ | | | [.Dz.] | Dz | Hungarian - Polish - Slovak - Serbo-Croatian | | [.dz.] | dz | | •----------•----------•------------------------------------------------• | [.LJ.] | LJ | | | [.Lj.] | Lj | Serbo-Croatian | | [.lj.] | lj | | •----------•----------•------------------------------------------------• | [.LL.] | LL | | | [.Ll.] | Ll | Spanish | | [.ll.] | ll | | •----------•----------•------------------------------------------------• | [.NJ.] | NJ | | | [.Nj.] | Nj | Serbo-Croatian | | [.nj.] | nj | | •----------•----------•------------------------------------------------• | [.SS.] | SS | | | [.Ss.] | Ss | German | | [.ss.] | ss | | •----------•----------•------------------------------------------------•Refer here and here for further information !
Example :
- The regex
(?-i)[[.Dz.]-[.Lj.]]matches the digraphDz( but notD), or one of the uppercase letters[EFGHIJKL]or the digraphLj. Test this regex against this text :
C c D d DZ Dz dz E e F f G g H h I i J j K k L l LJ Lj lj LL Ll ll M m N n -- - - - - - - - - •• -- •• •Note that, if the N++
Boostlibrary had been build with full Unicode support, all the Unicode names would had been recognized ! For example, in this page :Instead of using the classical syntax
\x{0418}to match the Cyrillic capital letterI, we could use a Unicode symbolic name, with the collating name[[.CYRILLIC CAPITAL LETTER I.]], which match the Cyrillic letterИ
Finally, we must speak of an interesting feature, named
Equivalence class:An equivalent class matches all the equivalent characters of a specific Unicode character, whatever the case, the accentuation, the size and other specificities of these characters
Its syntax is
[=Char=], where char represents an unique character and must be inserted in a classicalCharacter classFor instance :
-
The regex
[[=A=]]matches one<A>character of the range :[AaªÀÁÂÃÄÅàáâãäåĀāĂ㥹ǍǎǞǟǠǡǺǻȀȁȂȃɐɑɒḀḁẚẠạẢảẤấẦầẨẩẪẫẬậẮắẰằẲẳẴẵẶặÅ⒜ⒶⓐAa] -
The regex
[[=1=]]is equivalent to the regex[1¹₁⅟①⑴⒈❶➀➊1] -
The
[[===]]finds any single character of the range[=⁼₌⊜=] -
The
[[=plus-sign=]]regex matches one character from[⁺₊⊕⊞+] -
The
[[=Ae=]]syntax finds any one-char from the range[ÆæǢǣǼǽ]
Notes :
-
The char, between the two
=signs may also bedigraphor asymbolic name -
Any single character of the range may be used. For instance, the regexes
[[=A=]],[[=⒜=]], and[[=Ȁ=]]are equivalent and would match the same characters
To this purpose, have a look to the collation charts here
I hope, @carypt, that you have found some interesting things for your daily work !
Best Regards,
guy038
-
-
@guy038 said:
the right regex, in order to match any character with code-point over
\x{00FF}, is, rather :(?![\x00-\xFF]).[\x{D800}-\x{DFFF}]?I’m looking for a regex to match “any single UTF-8 character”, and I found this topic thread.
At first I obviously tried
.which clearly did NOT work. Why should it be that easy? :-)BEFORE I found this thread, I was trying
[^\x00-\xFF]|[\x00-\xFF]which seems to work but I’m guessing doesn’t always due to @guy038’s more complicated regex above. In other words, I’m sure the @guy038 regex is not shorter because it needs to be longer. :-)
Plus…this one maybe just seems “odd”. :-PSo then I modified @guy038’s regex to be
(?![\x00-\xFF]).[\x{D800}-\x{DFFF}]?|[\x00-\xFF]and, again, that seems to work but I wonder if it really does?Maybe @guy038 has some comments and advice…
-
Hello, @alan-kilborn and All,
You said :
I’m looking for a regex to match “any single UTF-8 character” and I found this topic thread.
Well, personally, for such a goal, I would simply use this regex
(?s).. Running this regex against myTotal_Chars.txtfile, whose I spoke of, in the second part of this post, above :https://community.notepad-plus-plus.org/post/66322
It does found out
325,590characters which is the total number of chars for thisUTF8-BOMfile with size =1,236,733(EF + BB + BF + LF + CR + 126 × 1 byte + 1,920 × 2 bytes + 61,406 × 3 bytes + 262,136 × 4 bytes )
Now, Alan, I edit my second post as I was wrong in many ways !
IMPORTANT : for testing the following regexes, you must check the
Match caseoption-
The regex
[[:unicode:]]does find all unicode characters over\x{00FF}, as well as the regex[^\x00-\xFF]. So325,334chars in myTotal_Chars.txtfile -
Thus the regex
[^[:unicode:]]( or[[:^unicode:]]) is identical to the regex[\x{0000}-\x{00FF}]or simply[\x00-\xFF]which finds256chars -
Finally, my complicated regex
(?![\x00-\xFF]).[\x{D800}-\x{DFFF}]?finds325,332characters and is equivalent to the regex(?!\x{2028})(?!\x{2029})[[:unicode:]]( Note :\x2028}is theLSchar and\x{2029}is thePSchar ). Don’t know why the tiny difference of two characters ?
BTW, Alan, the following regex would also grap all characters of an
UTF-8[BOM]file :[\x00-\xFF]|[[:unicode:]]Like the
(?s).regex, it would match the325,590characters of myTotal_Chars.txtfile !Best Regards,
guy038
-
-
@guy038 said in Search for character classes but not replace them:
( Note : \x2028} is the LS char and \x{2029} is the PS char ). Don’t know why the tiny difference of two characters ?
LS and PS are among the characters classified as “end of line” characters. LS and PS will get matched by things such as
\Rand\v. If you don’t have dot matches newline enabled then dot will not match either LS or PS. Searching for~[[:unicode:]]~will match both~LS~and~PS~but a search for~.~does not match either of those. All of the other characters matched by\Rand\vhave character values less than\xFF. The LS and PS characters are the exception.I don’t know if that detail explains why @guy038 needed to special case them.
-
@guy038 said:
for such a goal, I would simply use this regex
(?s).Now, you don’t think I’d bother you, or revive this old thread, if I were finding things that simple, do? I can easily show that that doesn’t work, on just a small bit of text:
💙☀🡢⮃🠧🠉…👍👌👎I see and count 10 characters there.
If I do a Find All in Current Document, it yields 11 hits, but I only see 3 characters highlighted as matches:
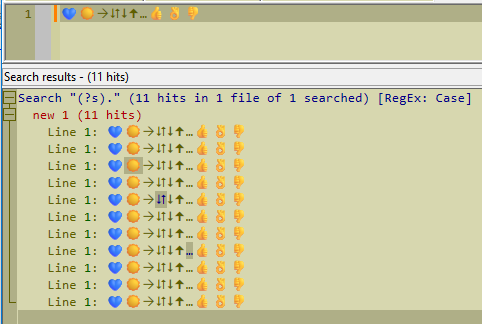
Worse, if I put my caret at the start of line 1 and repeatedly press Find Next, I have to press it 18 times before it runs out of matches (Wrap around not enabled) – many of these matches are “zero-length”, not one character at a time.
I have yet to try some of the other suggestions…but I will.
-
Hello, @alan-kilborn, @mkupper and All,
@mkupper, a BIG thanks to you : your assumption was exact !
Indeed, my complicated regex
(?![\x00-\xFF]).[\x{D800}-\x{DFFF}]?must be rewritten as(?s-i)(?![\x00-\xFF]).[\x{D800}-\x{DFFF}]?And, against my
Total_Chars.txtfiles, this new formulation does give the same amount of chars (325,334) than the[[:unicode:]]or the[^\x00-\xFF]regexes !
BTW, the nice thing about my
Total_Chars.txtis that it does not bother whether the unicode code-point is assigned or unnassigned to a character !Probably, depending on your current font, a lot of glyhs will not be reproduced correctly but we don’t care about it. We just want to be able to search any character from its code-point
\x{####}if inside theBMPor from its surrogate pairs\x{D###}\x{D###}if outside theBMPPresently, it just lists, one character after another, all valid characters from
U + 0000toU + EFFFD, described below ( as long as the Unicode Consortium does not decide to use the planes4to13)•--------------------•-------------------•------------•---------------------------•----------------•-------------------• | Range | Description | Status | Number of Chars | UTF-8 Encoding | Number of Bytes | •--------------------•-------------------•------------•-------------•-------------•----------------•-------------------• | 0000 - 007F | PLANE 0 - BMP | Included | | 128 | 1 Byte | 128 | •--------------------•-------------------•------------•-------------•-------------•----------------•-------------------• | 0080 - 0FFF | PLANE 0 - BMP | Included | | + 1,920 | 2 Bytes | 3,840 | •--------------------•-------------------•------------•-------------•-------------•----------------•-------------------• | 0800 - D7FF | PLANE 0 - BMP | Included | | + 53,248 | | 159,744 | | | | | | | | | | D800 - DFFF | SURROGATES zone | EXCLUDED | - 2,048 | | | | | | | | | | | | | E000 - F8FF | PLANE 0 - PUA | Included | | + 6,400 | | 19,200 | | | | | | | | | | F900 - FDFC | PLANE 0 - BMP | Included | | + 1,232 | 3 Bytes | 3,696 | | | | | | | | | | FDD0 - FDEF | NON-characters | EXCLUDED | - 32 | | | | | | | | | | | | | FDF0 - FFFD | PLANE 0 - BMP | Included | | + 526 | | 1,578 | | | | | | | | | | FFFE - FFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------•----------------•-------------------• | Plane 0 - BMP | SUB-Totals | - 2,082 | + 63,454 | | 188,186 | •--------------------•-------------------•------------•-------------•-------------•----------------•-------------------• | 10000 - 1FFFD | PLANE 1 - SMP | Included | | + 65,534 | | 262,136 | | | | | | | | | | 1FFFE - 1FFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------• •-------------------• | 20000 - 2FFFD | PLANE 2 - SIP | Included | | + 65,534 | | 262,136 | | | | | | | 4 Bytes | | | 2FFFE - 2FFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------• •-------------------• | 30000 - 3FFFD | PLANE 3 - TIP | Included | | + 65,534 | | 262,136 | | | | | | | | | | 3FFFE - 3FFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------•----------------•-------------------• | 40000 - DFFFF | PLANES 4 to 13 | NOT USED | - 655,360 | | 4 Bytes | | •--------------------•-------------------•------------•-------------•-------------•----------------•-------------------• | E0000 - EFFFD | PLANE 14 - SPP | Included | | + 65,534 | | 262,136 | | | | | | | | | | EFFFE - EFFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------• •-------------------• | FFFF0 - FFFFD | PLANE 15 - SPUA | NOT USED | - 65,334 | | | | | | | | | | | | | FFFFE - FFFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------• 4 Bytes •-------------------• | 100000 - 10FFFD | PLANE 16 - SPUA | NOT USED | - 65,334 | | | | | | | | | | | | | 10FFFE - 10FFFF | NON-characters | EXCLUDED | - 2 | | | | •--------------------•-------------------•------------•-------------•-------------•----------------•-------------------• | GRAND Totals | - 788,522 | + 325,590 | | 1,236,730 | | | | | | | | Byte Order Mark - BOM | | | | 3 | •-----------------------------------------------------•-------------•-------------• •-------------------• | | 1,114,112 Unicode chars | | Size 1,236,733 | •-----------------------------------------------------•---------------------------•----------------•-------------------•
Of course, due to the line-breaks, produced by the
LFandCRcharacters, this file contains three physical lines :-
A first line from
\x00to\x0A, so11chars -
A second line from
\x0Bto\x0D, so3chars -
A third long line from
\x0Eto\xEFFFD, so325,576chars
If anyone is interested by this file, I could send it by e-mail. Just tell me ! But I suppose that it could be easily implemented with a
Pythonscript.Simply list, in a
UTF-8-BOMfile, all ranges of characters defined asIncludedin theStatuscolumn of the above table !You should get a file containing
325,590characters for an exact size of1,236,733bytesNow, if you decide to include all the
NOT USEDareas, too, you’ll get aTotal_UNICODE_Chars.txtfile, of1,111,998chars for a size of4,372,765bytes which would be exact for… eternity ;-))
Alan, I"ve just seen your last post ! Give me some time to study your example and I’ll answer you very soon !
Best Regards,
guy038
P.S. : I created a macro which changes any selected regex synntax
\x{#####}into its correspondant surrogate pair\x{D###}\x{D###}:<Macro name="Surrogates Pairs in Selection" Ctrl="no" Alt="no" Shift="no" Key="0"> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?-i)\\x\{(10|[[:xdigit:]])[[:xdigit:]]{4}" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="$0\x1F" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?i)(?:(1)|(2)|(3)|(4)|(5)|(6)|(7)|(8)|(9)|(A)|(B)|(C)|(D)|(E)|(F)|(10))(?=[[:xdigit:]]{4}\x1F\})|(?:(0)|(1)|(2)|(3)|(4)|(5)|(6)|(7)|(8)|(9)|(A)|(B)|(C)|(D)|(E)|(F))(?=[[:xdigit:]]{0,3}\x1F\})" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="(?{1}0000)(?{2}0001)(?{3}0010)(?{4}0011)(?{5}0100)(?{6}0101)(?{7}0110)(?{8}0111)(?{9}1000)(?{10}1001)(?{11}1010)(?{12}1011)(?{13}1100)(?{14}1101)(?{15}1110)(?{16}1111)(?{17}0000)(?{18}0001)(?{19}0010)(?{20}0011)(?{21}0100)(?{22}0101)(?{23}0110)(?{24}0111)(?{25}1000)(?{26}1001)(?{27}1010)(?{28}1011)(?{29}1100)(?{30}1101)(?{31}1110)(?{32}1111)" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="([01]{10})([01]{10})(?=\x1F)" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="110110\1\x1F}\\x{110111\2" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> <Action type="3" message="1700" wParam="0" lParam="0" sParam="" /> <Action type="3" message="1601" wParam="0" lParam="0" sParam="(?:(0000)|(0001)|(0010)|(0011)|(0100)|(0101)|(0110)|(0111)|(1000)|(1001)|(1010)|(1011)|(1100)|(1101)|(1110)|(1111))(?=[[:xdigit:]]*\x1F\})|\x1F" /> <Action type="3" message="1625" wParam="0" lParam="2" sParam="" /> <Action type="3" message="1602" wParam="0" lParam="0" sParam="(?{1}0)(?{2}1)(?{3}2)(?{4}3)(?{5}4)(?{6}5)(?{7}6)(?{8}7)(?{9}8)(?{10}9)(?11A)(?12B)(?13C)(?14D)(?15E)(?16F)" /> <Action type="3" message="1702" wParam="0" lParam="640" sParam="" /> <Action type="3" message="1701" wParam="0" lParam="1609" sParam="" /> </Macro>For instance, if you select the regex
\x{10000}\x72\x{27}\x0\x{EFFFD}Is changed, with this macro, into
\x{D800}\x{DC00}\x72\x{27}\x0\x{DB7F}\x{DFFD}which correctly matches the 𐀀R’ string ! -
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login