Regex. Remove headings that has no full stop at the end (.)
-
Re: Help - Remove a line from a specific text but keep a part of the text
I read your post above and I thought that it matches my own subject, so I wrote directly here.
I have many headings in a text and it ends with a Carriage return and Line Feed(CRLN):
Subject:Beginning of the heading words words words end of header with no full stop at the endCRLN
Abc 200:1 words words words and the end of sentence.I used this regex:
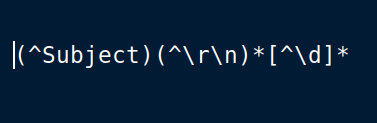
and it matches until Abc. But, I need to remove only the heading without Abc. I would really appreciate your input. Thank you! -
Hello, @dumitru-s and All,
If I fully understand you, you would like to remove lines :
- Which begin with the word
Subject, with this exact case
AND
- Which does not end with a full stop sign
.
If so, the following S/R should work :
SEARCH
(?-si)^Subject.+(?<!\.)\RREPLACE
Leave EMPTYBest Regards
guy038
- Which begin with the word
-
@guy038 said in Regex. Remove headings that has no full stop at the end (.):
(?-si)^Subject.+(?<!.)\R
Yes, you did understand me very well. I tried your code and fully works. So, thank you.
Only that my text being of 34900 lines I just discovered that some headings are broken in the middle ones, twice or even more times by Carriage Return and Feed Line. Like this:
Subject:Beginning of the heading wordsCRLN
words words words words words words wordsCRLN
words end of header with no full stop at the endCRLN
Abc 200:1 words words words and the end of sentence.So, in this case that match goes only until the first CRLN, and not al the way until the end just before Abc, as I need it to go.
I tried to tweak your code but I need to study more before I really can understand what you did.
I further appreciate you help. Thank you a lot @guy038 !
-
Hi, @dumitru-s and All,
OK ! So, in other words, you expect to delete any block of lines :
-
Beginning with the word
Subject, with this exact case -
Ending with the last complete line which does not end with a full stop sign
.
Try this S/R :
SEARCH
(?s-i)^Subject[^.]+\RREPLACE
LEave EMPTYNotes :
-
The part
[^.]+matches the greatest non-null range of any character, including EOL chars like\rand\n, different from a dot char (.) -
The
\Rsyntax matches any EOL char(s), so\r\nin Windows files,\nin Unix files and\rin Mac files
BR
guy038
-
-
Thank you for S/R, and thank you for your Notes.
What I want is also to delete ALL the block of lines and only those block lines:
-
Beginning from the word Subject, with this exact case
-
Ending with the word that is just before the Abc but without Abc.
…as seen below:
Subject: Beginning of the heading wordsCRLN
words words words words words words wordsCRLN
words end of header with no full stop at the endCRLN
Abc 200:1 words words words and the end of sentence.The trick is that the word just before Abc si at the end of the line, but it does not have a full stop.
Thank you again! -
-
@Dumitru-S said in Regex. Remove headings that has no full stop at the end (.):
The trick is that the word just before Abc si at the end of the line, but it does not have a full stop
No, the trick is that you have not defined the rule for when
words CRLF wordsshould be treated as not the end, butend CRLF abcshould be treated as the end. Because in our reading of your fake text, we cannot see any difference betweenwordsandabc–abcis still alphabetic text, just likewordsis. Guy works magic with regex, but he cannot actually read your mind. -
Hi, @dumitru-s, @peterjones and All,
Sorry, @dumitru-s, But I’m still confused about what you want. I surely miss something obvious !
Let’s suppose the sample text below :
Subject: BEGINNING of the heading words words words words words ( Line A ) words words words words words words words words words words words ( Line B ) words words words words END of header with NO full stop at the end ( Line C ) Abc 200:1 words words words and the end of sentence with a FULL STOP. ( Line D ) Subject: BEGINNING of the heading words words words words words ( Line A ) words words words words words words words words words words words ( Line B1 ) words words words words words words words words words words words ( Line B2 ) words words words words words words words words words words words ( Line B3 ) words words words words words words words words words words words ( Line B4 ) words words words words END of header with NO full stop at the end ( Line C ) Abc 200:1 words words words and the end of sentence with a FULL STOP. ( Line D )The regex, given in my previous post (
(?s-i)^Subject[^.]+\R), does select from beginning of LineA(Subject) till the very end of LineC( So, till the closing parenthesis AND theEOLchars\rand\n). In other words it selects till right before theAbcstring. Isn’t it ?Best Regards,
guy038
-
Hi @peterjones, @guy038 and All,
You both are right. I myself was wondering how is it that you are wrong and also in the same time I was wrong, too. I was sure I was wrong somewhere, but I just did not know where, but I found it.
The fact that I was not able to clearly define my text it just shows what a rooky I am in Regex.My text being so long I missed some aspects of it. I apologize, but now I got it. Thank you for patience.
As you see it in the picture and in the video link below, the difference is in the punctuation at the end of the lines. That is where, in some of my lines, your code did not work and I did not know why.
Watch MyTextStrucure.mp4 and see how the code works on it.So, what I need is to remove text starting from the word Subject all the away until the first Abc without deleting Abc. Note that at the end of the heading, which is just before the start of the first Abc line can be punctuation OR it cannot appear any punctuation, but there will never be a full stop.
This is a real challenge, I know, at least for me it is. I hope I defined it clearly this time.
-
@Dumitru-S ,
(I don’t know what’s in your video, because my I.T. department blocks dropbox and most other such services.)
You still have not explained how the regex is supposed to tell the difference between a line that starts with
wordsand a line that starts withAbc. IsAbcliteral text, and we’re supposed to recognize that the Subject header ends on the line before literalAbceach time? Or can thatAbcbe different text each time? Is the real indicator that the line starts with text followed by a number and a colon (likeAbc 200:orXyz 555:)? Or is it that the line starts with a capital letter? Or is it that the line starts with a capital letter and has a colon?Please notice that your examples have completely ignored the advice that I gave to the other poster in the “Remove a line from a specific text…” discussion that you linked in the first post in this topic. That advice said that you should always give examples of text/lines that should match and text/lines that should not match, and that the example data should have as much variation as your real data. We cannot tell if you are using
Abcas literal text, or as a placeholder meaning that multiple different text can go in that slot. And since you useAbcevery time, it keeps re-inforcing that literalAbcis what you’re looking for, but the textAbclooks like a placeholder, so we’re afraid that you do not actually mean that, and that you’re going to come back and complain that it only worked onAbcnot onXyzdespite the fact that you’ve never mentionedXyz.For example, which of these situations should be regarded as a “missing full stop” situation?
Chapter 1 Subject: This is a multiline header, Abc and this isn't part of the header Chapter 2 Subject: Another multiline header goes here, Abc 200:1 and more text Chapter 3 Subject: Third header that goes across multiple lines, Abc 555: how about this one Chapter 4 Subject: Fourth multiple lines, all in the same header, as evidenced here Xyz 200: what about this one? Chapter 5 Subject: And here's a fifth example Xyz without colon or number Chapter 6 Subject: Yet another example, two lines this time, Xyz: with colon, no number Chapter 7 Subject: this has multiple lines, and the next will start, abc 200: this has lower case, so is "start," still part of a matching header or not? Chapter 7 Subject: what about multiline followed by abc: with lowercase, and with colon, but no number Chapter 8 Subject: here is one last subject, abc without colon and no number and all lowercaseThis is a real challenge, I know, at least for me it is
The real challenge is that you cannot even describe what you want in language and examples. How you can expect us to guess it is beyond me.
However, if you hadn’t had the history of this whole confusing thread, if you were to have just said,
So, what I need is to remove text starting from the word Subject all the away until the first literal
Abcwithout deleting Abc. The subject section is possibly crossing multiple linesI would have replied,
FIND =
(?s)Subject:.*?(?=^Abc)
REPLACE = empty
MODE = regular expression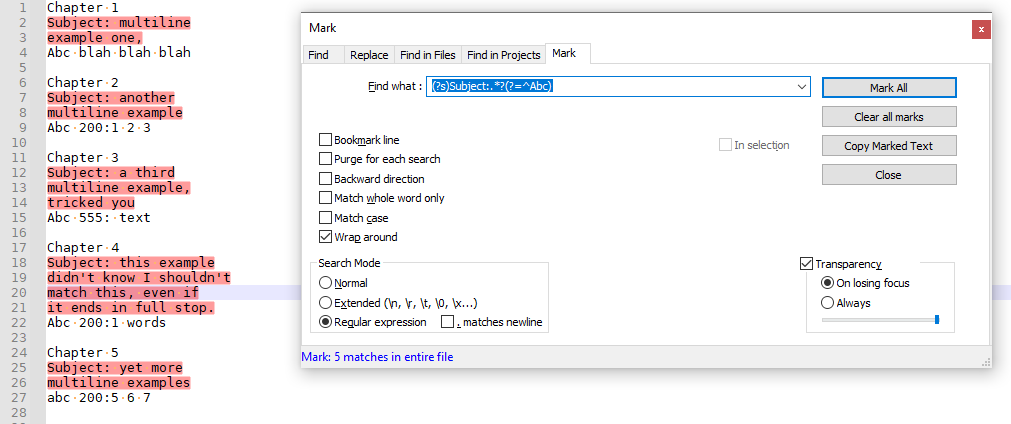
If you had said,
So, what I need is to remove text starting from the word Subject all the away until the first Abc without deleting Abc. The subject section is possibly crossing multiple lines. Never delete a subject section if it ends with a full stop.
FIND =
(?s)Subject:.*?(?!<\.\R)(?=^Abc)
REPLACE = empty
MODE = regular expression(this adds the restriction that a literal full-stop (
\.) cannot be the character just before the newline sequence (\R).)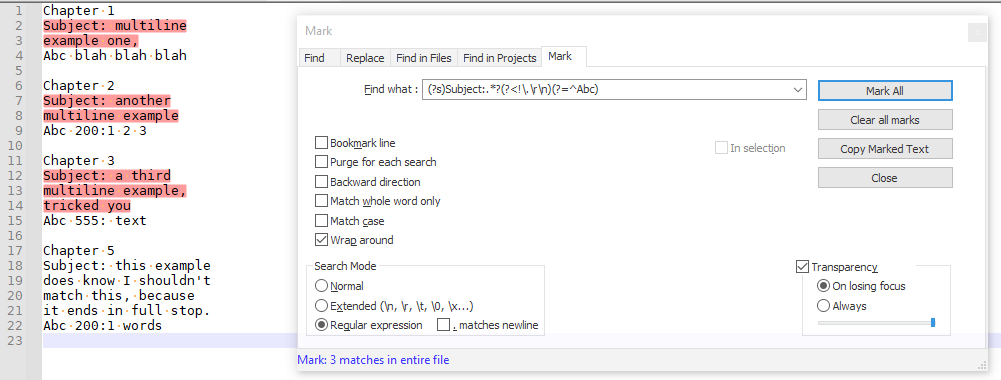
But, once again, this is all guessing, because you need to spend more effort in giving examples that will
Also, the regexes so far will have the problem that because they don’t want to match a Subject that does end in full stop, if it finds one that does, it might go across multiple chapters, like in the example
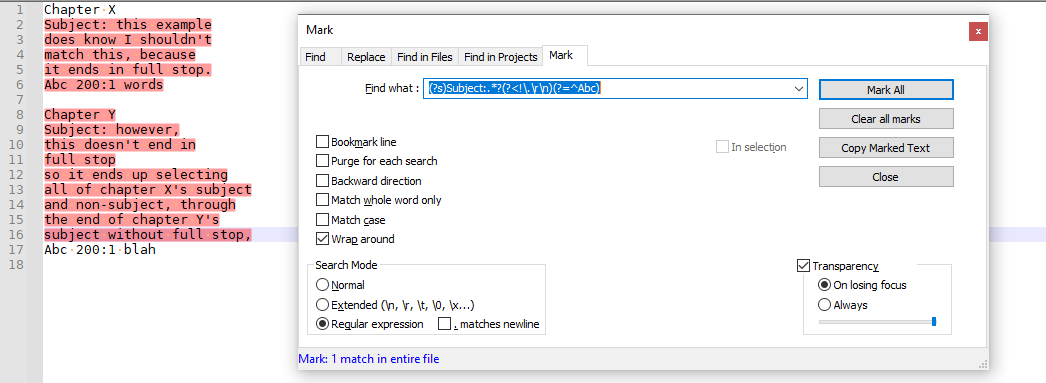
If this isn’t what you want, then you will have to give more examples of text that should match and text that shouldn’t.-—
Do you want regex search/replace help? Then please be patient and polite, show some effort, and be willing to learn; answer questions and requests for clarification that are made of you. All example text should be marked as literal text using the
</>toolbar button or manual Markdown syntax. To makeregex in red(and so they keep their special characters like *), use backticks, like`^.*?blah.*?\z`. Screenshots can be pasted from the clipboard to your post usingCtrl+Vto show graphical items, but any text should be included as literal text in your post so we can easily copy/paste your data. Show the data you have and the text you want to get from that data; include examples of things that should match and be transformed, and things that don’t match and should be left alone; show edge cases and make sure you examples are as varied as your real data. Show the regex you already tried, and why you thought it should work; tell us what’s wrong with what you do get. Read the official NPP Searching / Regex docs and the forum’s Regular Expression FAQ. If you follow these guidelines, you’re much more likely to get helpful replies that solve your problem in the shortest number of tries. -
Maybe we need a template that posters with a regular expression question have to fill out successfully in order to move to the first level of help.
If they can’t get through the template, then absolutely no help…not a bunch of back-and-forth-(pull-teeth)-to-get-an-accurate-statement-of-the-problem, not a lot of guessing about what is wanted, not a ton of lets-solve-every-possible-problem-this-could-be.
I don’t think we have anything to feel bad about in denying help if someone can’t accurately state what they need help with!
So, okay, I enjoy reading about these types of problems and their solutions, but if there is a huge amount of the “diversions” enumerated above in a thread, I get confused and lose interest – because it gets darned hard to follow. And maybe that way I miss out on a “gem” of a new technique. And I don’t want that to happen.
-
@PeterJones said in Regex. Remove headings that has no full stop at the end (.):
(?s)Subject:.*?(?=^Abc)
Thank you very much, sir, for answering with so much professionalism and in much detail.
This code worked very well for me: (?s)Subject:.*?(?=^Abc) , and this is exactly what I desired from the beginning, although it was not easy for me to explain in words what I need; I am just a beginner.
I would like to study carefully what you wrote. Thank you @guy038 @PeterJones @Alan-Kilborn and All.
Have an excellent day today!
-
Hello, @dumitru-s, @peterjones and All,
Sorry to reactivate this topic but, @dumitru-s, from the picture, below, could you just bookmark ALL the lines which should be matched, in each chapter, by the “future” regex ?
You are also invited to add some other chapters, with the corresponding bookmarks, if this way could improve our comprehension of what you want to match ;-))
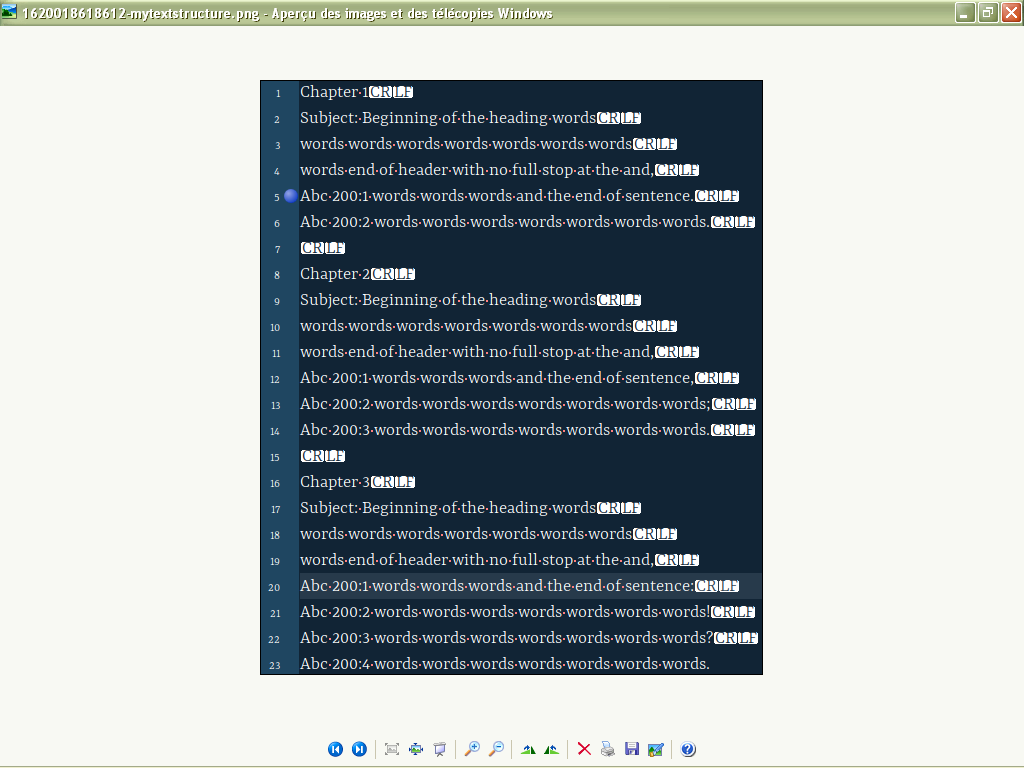
Thanks for this extra-work !
BR
guy038
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login