How to find and replace unrecognizable characters in multiple files of a folder with the correct character using Notepad ++?
-
@PeterJones I finally found a solution here: how-to-find-non-ascii-unprintable-characters-using-notepad-plus-plus
We have to select the Regular expression mode and search/find with this code: [\x00-\x08\x0B\x0C\x0E-\x1F\x7F-\x9F]
I will do the replacements one by one instead of using “Replace all” -
Find Allis making Notepad++ to stop working and close if I use the above code. Any suggestions to avoid that?
-
Find All is making Notepad++ to stop working and close if I use the above code.
Which Find All do you mean? Do you mean the Find > Find All in Current Document, Find > Find All in Opened Documents, or Find in Files > Find All ?
Please note that the Find in Files adds another level of confusion, because Notepad++ is trying to figure out the encoding on each file individually, and depending on the bytes in the file and your settings (as described above), it might think some are UTF-8 and others are ANSI or might pick a strange character-set value. The Find in Files isn’t great with non-ASCII characters, unfortunately. There are bug reports / feature requests, but they are taking time to get worked out.
I suggest doing one file at a time for now.
-
@PeterJones @Ekopalypse Thank you both for your time and help. @PeterJones Please post here if the bug is fixed and I can Find all/search in multiple files of a folder
-
Please post here if the bug is fixed and I can Find all/search in multiple files of a folder
Don’t misunderstand. Find in Files > Find All works for ASCII characters. And it works with valid characters in well-defined encodings (so a UTF-8-BOM or UCS-2-LE BOM file should properly search-and-replace with any valid character). It’s just when you’re making Notepad++ guess the encoding (one of the many character-set “encodings”) or when there are invalid characters (byte x93 all alone rather than in the appropriate mutli-byte sequence in a UTF-8 file). So, for your unusual use-case, it’s not currently working; but usually, it does.
-
@PeterJones By God’s grace, the Find all/search in multiple files of a folder using the Regular expression mode finally worked after I removed all the files that did not end with the
.htmlextension. I thank you again from the bottom of my heart!
-
(This post was in progress before your questions about Find All… I came back to this post later, so that future readers of the thread will know which character matches which.)
@Ramanand-Jhingade wrote:
I finally found a solution here: how-to-find-non-ascii-unprintable-characters-using-notepad-plus-plus
We have to select the Regular expression mode and search/find with this code:[\x00-\x08\x0B\x0C\x0E-\x1F\x7F-\x9F]Good job! I applaud your persistence.
However, the solution surprises me.
It didn’t make sense to me that
\x93wouldn’t find“but that[\x00-\x08\x0B\x0C\x0E-\x1F\x7F-\x9F]would. In an ANSI-encoded file, that search makes perfect sense, because those bytes aren’t in ASCII or extended-ASCII. But in a UTF-encoded file, those bytes aren’t valid unless they are part of a multi-byte UTF-8 encoding sequence.So I started cutting parts out of that expression until I narrowed it down to what’s matching:
\x13matched thex93byte.With a UTF-8 encoded file that has bad bytes with the MSB set that don’t get interpreted as part of a multi-byte UTF-8 character sequence, the following appears true:
\x13will match the
\x14will match the
For example:
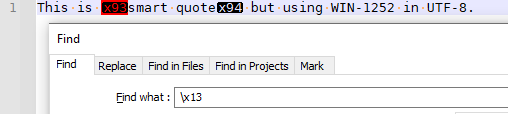
So I built up a test file , and started doing searches:
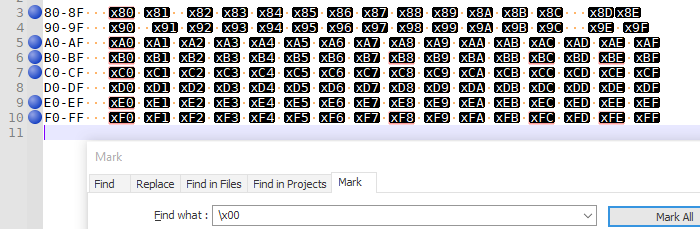
- searching
\x00matches many, including x80, xA0, xB0, xB8, xBC, xBE, xC0, xE0, xF0, xF8, xFC, xFE - searching
\x01matches eight, including x81, xA1, xB1, xB9, xBD, xC1, xE1, xF1, xF9, xFD - searching
\x02matches eight, including x82, xA2, xB2, xBA, xC2, xE2, xF2, xFA - searching
\x03matches eight, including x83, xA3, xB3, xBB, xC3, xE3, xF3, xFB - searching
\x04matches six, including x84, xA4, xB4, xC4, xE4, xF4 - searching
\x05,\x06, and\x07each match the seven in the same pattern as\x04 - searching
\x08only matches four, including x88, xA8, xC8, xF8 .\x09works analogously - searching
\x0Amatches that same pattern of four, but also matches all the line-feed character in the EOL sequences - searching
\x0Band\x0Ceach match four, including x8B, xAB, xCB, xFB, x8C, xAC, xCC, xFC, - searching
\x0Dmatches the pattern of four, and all the carriage returns in the EOL sequences - searching
\x0Ematches the pattern of four: x8E, xAE, xCE, xEE - searching
\x0Fmatches three of the four (but my file didn’t have x8F to match against) - searching
\x10matches two: x90 and xD0.\x11,\x12,\x13,\x14,\x15,\x16,\x17,\x18,\x19,\x1A,\x1B,\x1C,\x1D,\x1E,\x1Fall match the two entries from the 90 and D0 rows.
And no, @Alan-Kilborn , to answer your chat question, it does not change behavior inside of the
[]character class.As near as I can tell, in this poorly-encoded situation, the search engine seems to be applying certain bit-masks when searching for invalid bytes, where it masks out some of the upper bits while looking for matches. (My guess is that the multiple matches for a given search escape has to do with the fact that in valid UTF-8, 8-bit sequences that are
10xxxxxxcan only be the second, third, or fourth byte of the multibyute sequence (so that’s 0x80-0xBF);110xxxxxis the start of a 2-byte sequence (0xC0-0xDF);1110xxxxis the start of a 3-byte sequence (0xE0-0xEF); and1111xxxxis the start of a 4-byte sequence (0xF0-0xFF). But that’s a wild guess.)Remember, all of these were for my experiments, with a file that Notepad++ is interpreting as UTF-8, but have these badly-encoded single bytes with spaces in between. This isn’t a general search technique in a well-formed file with the right encoding selected. None of this is best-practice, but is only here to help correct mal-formed UTF-8 files.
-
Hello, @ramanand-jhingade, @peterjones, @ekopalypse, @alan-kilborn and All,
Many thanks for your insight about invalid bytes in
UTF8encoded files. Very strange indeed !So, in summary, if we use the non-regex notation
x[U][V]to represent the invalid characterxUV:- The regex \x00 matches the INVALID bytes x[8ABCEF][0] and x[BF][8CE] - The regex \x01 matches the INVALID bytes x[8ABCEF][1] and x[BF][9D] - The regex \x02 matches the INVALID bytes x[8ABCEF][2] and x[BF][A] - The regex \x03 matches the INVALID bytes x[8ABCEF][3] and x[BF][B] and \x[B][F] - The regex \x0[4-7] matches the INVALID bytes x[8ABCEF][4-7] - The regex \x0[8-F] matches the INVALID bytes x[8ACE][8-F] - The regex \x1[0-F] matches the INVALID bytes x[9D][0-F]I tried to find out a general rule explaining these results… without success :-(
Note that the invalid byte
xFF, in anUTF-8encoded file, cannot be find with the notation\x[01][0-F]
Now, I think that @ramanand-jhingade could also find and replace the
x93arulvaakkux94string with the following regex S/R :SEARCH
[[:cntrl:]]arulvaakku[[:cntrl:]]REPLACE
"arulvaakku"Note that, again, the Posix class
[[:cntrl:]]is not able to match the invalidUTF-8bytexFF!
As a remainder, here is, in a picture, some pieces of information about the
UTF-8encoding :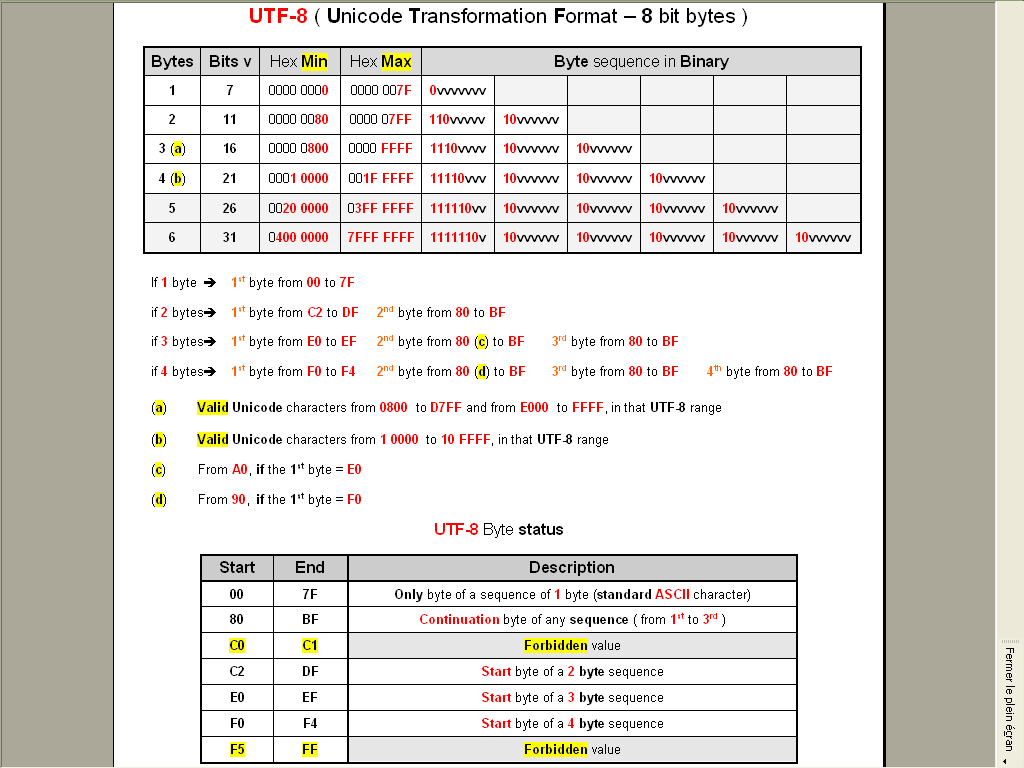
Best Regards
guy038
-
@guy038 said in How to find and replace unrecognizable characters in multiple files of a folder with the correct character using Notepad ++?:
here is, in a picture, some pieces of information about the UTF-8 encoding
That’s a nice reference. Where is it from?
I’ve just been using Wikipedia’s similar pictorial reference --> HERE.
-
Hi, @alan-kilborn and All,
No, just a personal presentation, in a
Worddocument, of some parts of this article that I made some years ago, to fully understand theUTF-8encoding ;-))My first table is simply the extension to the complete
UTF-8encoding of the Unicode table, seen here, which is able to encode all theUnicodecharacters (1,114,112)With the complete
UTF-8encoding, up to six bytes, it can represent up to134,217,728characters ( so fromU+0toU+7FFFFFF)As you can see, no problem for
UTF-8to encode all characters used in the different inhabited worlds of the galaxy !!!
And my second table is simply an other presentation of this one, on Wikipedia
BR
guy038