I would like to group all similar domains, not by alphabet.
-
Could you tell us which is this number?
The number is 13 dots!
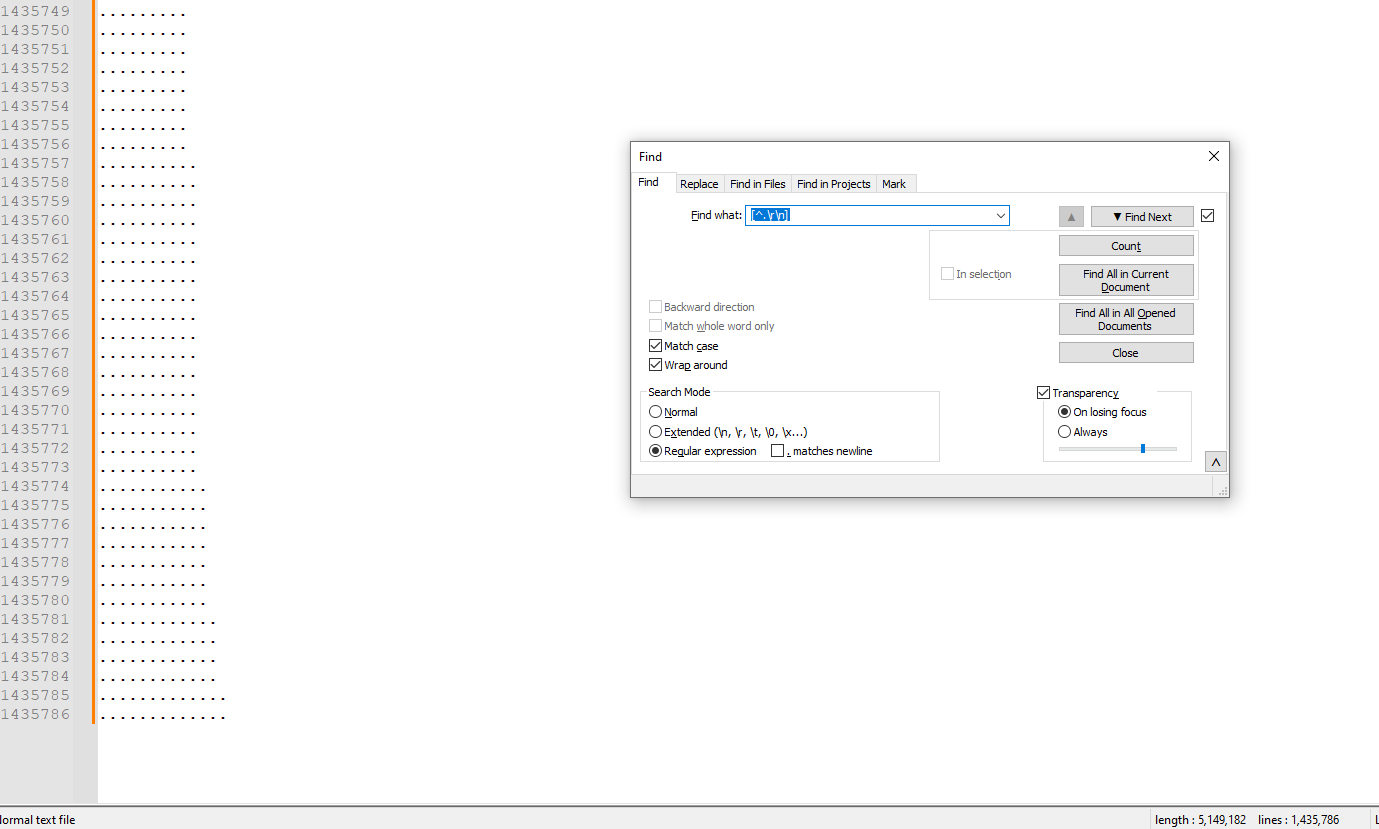
-
Hello @mohammad-al-thobiti and All,
Ah… OK !! So, give me some time to find out the correct regex S/R which could handle and revert up to
13sections !!See you later,
Best Regards
guy038
-
This post is deleted! -
@Coises said in I would like to group all similar domains, not by alphabet.:
Commas are not allowed in domain names, so we can use a comma to distinguish between forward and reversed domain names
… which is why I used the historical standard of exclamation points for reversed domain names, rather than introducing ambiguity by re-using the period.
, and reverse them one part at a time:
I do like the way that simplifies the regex, to make it much more understandable and generic, at the expense of making the user click Replace All up to 13 times.
Ugh. You deleted your post while I was replying. It had good information. I am hoping you are going to re-post a slightly rephrased version eventually.
@guy038 said,
So, give me some time to find out the correct regex S/R which could handle and revert up to 13 sections !!
That’s why I just gave the generic format in my original regex, and explained how @Mohammad-Al-Thobiti could extend the idea to as many groups as was desired, because I had a feeling in my reply that the original three-section solution wasn’t going to be enough. Taking my generic formula and just appending copies of the two tokens that I supplied would have worked up to 9 capture groups – and I was hoping that the other regulars here would have let the OP try to learn from the example, rather than spoonfeeding.
And using the
${ℕ}substitution syntax and(?{ℕ}...)conditional replacement instead of$ℕand(?ℕ...)in the replacement would have allowed for ten or more groups. Which is what I would have suggested when the OP came back with the inevitable “but what if I want more groups than 9? when I tried to 13 groups, it didn’t work”. Because my expression didn’t use nesting, it wouldn’t require any fancy thought on the part of the user, just literally copy/pasting more of the same sort of token, and the ability to interpret that they needed to count up with each ℕ in the replacement.But @Coises’ currently-deleted suggestion of just doing a single pair replacement, run many times, would be even simpler to understand than my original suggestion, without the
{ℕ}requirements. So I hope @Coises re-posts that solution once he’s comfortable with the wording, because it’s the best solution for easy extending to as many domain pieces as needed. -
@PeterJones said in I would like to group all similar domains, not by alphabet.:
Ugh. You deleted your post while I was replying.
I am sorry about that. It contained a good idea, implemented incorrectly. My “solution” rotated the parts of the domain name rather than reversing them.
I didn’t know about exclamation points being a standard; I’ll use those instead of commas when I figure out how to do this correctly.
I also realized the original poster probably wants domains like
xxx.comandxxx.organdxxx.co.ukto sort together, which adds an extra complexity. -
@Coises said in I would like to group all similar domains, not by alphabet.:
I also realized the original poster probably wants domains like xxx.com and xxx.org and xxx.co.uk to sort together, which adds an extra complexity.
I think your solution, without that, is sufficient for any reasonable need. If the OP desires that complexity, they can take what we’ve already given them and read the documentation that I linked them to, and figure out the next level themselves. (But if you really want to spend your time on that, I’d recommend doing initial searches from
blah.com,blah.co.uk, etc, and turn those intoblah,comandblah,co,uk; then use ! as the machine separator. That way it will sort first by theblah, then by any more specific things above, which would keepblah.comandblah.co.uknear each other) -
Since there are so many levels, and you’re working with a temporary file anyway, we could make this less tricky. At @PeterJones’ suggestion, here we use an exclamation point to distinguish between forward and reversed domain names.
Enter:
Find what :
([^.\s]+)\.([^!\s]+)
Replace with :\2!\1Replace All repeatedly until it says 0 occurrences were replaced, then sort the file.
If you need to change back to normal domain names after the sort, use:
Find what :
([^!\s]+)!([^.\s]+)
Replace with :\2.\1and Replace All repeatedly until it says 0 occurrences were replaced.
The steps above will sort first by the top-level domain (.com, .net, etc.). If you need to have, say,
whatever.comandwhatever.netandwhatever.co.uksort together, then after reversing the domain names, use something like:Find what :
^([a-z]{2}![a-z]{2}|[^!]+)!(\S+)
Replace with :\2 \1and Replace All once before sorting. (This is not guaranteed to be correct for every case of two-letter top level domains, but it should get the common ones right.)
To reverse, after sorting, use:
Find what :
^(\S+) (\S+)
Replace with :\2!\1 -
Hi, @mohammad-al-thobiti, @peterjones, @coises and All,
Ah, ah ah… I’m very happy to announce that I’ve found out a general regex which can handle any number of sections ;-))
So, let’s begin with this simple INPUT text containing from
2to13sections ( one of each ), pasted in a new tab :abc.def abc.def.ghi abc.def.ghi.jkl abc.def.ghi.jkl.mno abc.def.ghi.jkl.mno.pqr abc.def.ghi.jkl.mno.pqr.stu abc.def.ghi.jkl.mno.pqr.stu.vwx abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0 abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123 abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456 abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789 abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789.€±¶ abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789.€±¶.Ø÷ß- Move to the very beginning of the file (
Ctrl + Home)
First, we add the
|.string at the beginning of every line, with the following regex S/R :-
SEARCH
(?x-s) ^ (?= . ) -
REPLACE
|.
Thus, we get :
|.abc.def |.abc.def.ghi |.abc.def.ghi.jkl |.abc.def.ghi.jkl.mno |.abc.def.ghi.jkl.mno.pqr |.abc.def.ghi.jkl.mno.pqr.stu |.abc.def.ghi.jkl.mno.pqr.stu.vwx |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0 |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123 |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456 |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789 |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789.€±¶ |.abc.def.ghi.jkl.mno.pqr.stu.vwx.yz0.123.456.789.€±¶.Ø÷ß- Move to the very beginning of the file (
Ctrl + Home)
Now, this is the main regex S/R :
-
SEARCH
(?x-s) ^ ( .* \| ) ( (?: \. (?: (?! \| ) \S )+ )+ ) ( \. (?: (?! \. ) \S )+ ) -
REPLACE
\1\3|\2 -
Click
14thtimes on theReplace Allbutton, till you get the messageReplace All: 0 occurrences were replaced from caret to end-of-file
=> You should get the temporary text :
|.def|.abc |.ghi|.def|.abc |.jkl|.ghi|.def|.abc |.mno|.jkl|.ghi|.def|.abc |.pqr|.mno|.jkl|.ghi|.def|.abc |.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.123|.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.456|.123|.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.789|.456|.123|.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.€±¶|.789|.456|.123|.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc |.Ø÷ß|.€±¶|.789|.456|.123|.yz0|.vwx|.stu|.pqr|.mno|.jkl|.ghi|.def|.abc- Move to the very beginning of the file (
Ctrl + Home)
Now, we just to get rid of all the
|chars as well as the FIRST dot of each line, with the regex S/R :SEARCH
(?x) ^ \| \. | \|REPLACE
Leave EMPTYAnd we get our expected OUTPUT text :
def.abc ghi.def.abc jkl.ghi.def.abc mno.jkl.ghi.def.abc pqr.mno.jkl.ghi.def.abc stu.pqr.mno.jkl.ghi.def.abc vwx.stu.pqr.mno.jkl.ghi.def.abc yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc 123.yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc 456.123.yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc 789.456.123.yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc €±¶.789.456.123.yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc Ø÷ß.€±¶.789.456.123.yz0.vwx.stu.pqr.mno.jkl.ghi.def.abc
So, @mohammad-al-thobiti :
-
Apply all the above steps against your real file
-
Run the
Edit > Line Operations > Sort Lines Lexicographically Ascendingoption ( No [rectangular] selection is needed as you just keep the addresses ) -
Possibly, add back the
127.0.0.1IPV4 address, followed with twospacechars with the regex S/R :-
SEARCH
(?x-s) ^ (?= . ) -
REPLACE
(127.0.0.1 )
-
Best Regards,
guy038
P.S. :
I’ve just seen the @coises’s solution. I’m going to have a look at its solution which could be more simple than my regex solution !
- Move to the very beginning of the file (
-
Hi, @mohammad-al-thobiti, @peterjones, @coises and All,
@mohammad-al-thobiti, you should use the @coises’s approach, which works much better than mine !!
In addition, in my previous post, I omitted to add the reverse regex to use, once your sort would be done :-((
While the @coise’s method avoids any additional S/R and correctly mentions the reverse regex to run after the sort operation
Note that I slightly Modified the first two @coises’s regexes to get more rigorous ones ( See, at the end of this post the reason for these changes )
Thus, I would propose this road map :
-
First, from the @coises’s post, I would use this alternate regex formulation :
-
SEARCH
(?x) ( [^.\r\n]+ ) \. ( [^!\r\n]+ ) -
REPLACE
\2!\1 -
Click
14thtimes on theReplace Allbutton
-
-
Run the
Edit > Line Operations > Sort Lines Lexicographically Ascendingoption ( No [rectangular] selection is needed as you just keep the addresses ) -
Thirdly, once the sort done, from the @coises’s post, use the alternate reverse regex S/R :
-
SEARCH
(?x) ( [^!\r\n]+ ) ! ( [^.\r\n]+ ) -
REPLACE
\2.\1 -
Click
14thtimes on theReplace Allbutton
-
=> You should get all your addresses back, in the right order
Best Regards,
guy038
P.S. :
@coises uses the
\sclass of characters, which is equivalent to any of the25characters, below, with the regex :(?x) \t | \n | \x{000B} | \x{000C} | \r | \x{0020} | \x{0085} | \x{00A0} | x{1680} | [\x{2000}-\x{200B}] |\x{2028} | \x{2029} | \x{202F} | \x{3000}In the highly unlikely event that one of these characters is included in some addresses, I preferred to use the
[\r\n]regex, which ONLY avoids these 2EOLchars in addresses, instead of using the\sregex ! -
-
Thank you for your efforts, my friends.
I would like to tell you that the result is excellent.
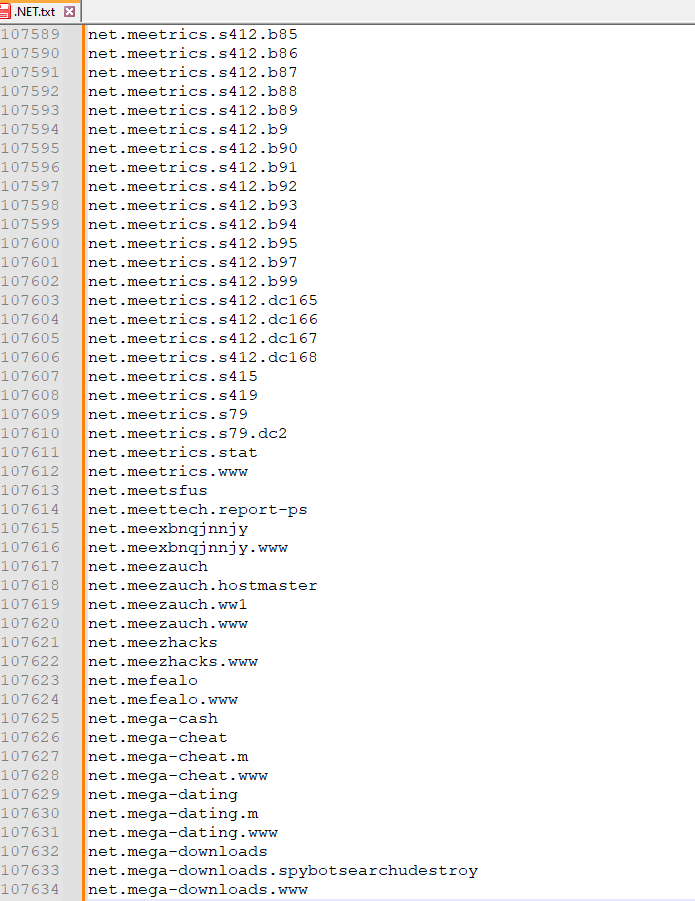
But an idea came to me: why not just delete the subdomain and keep only the main domain and then delete the similar ones?
Is there a way to delete long link extensions? And keep the main domain?Example:
-
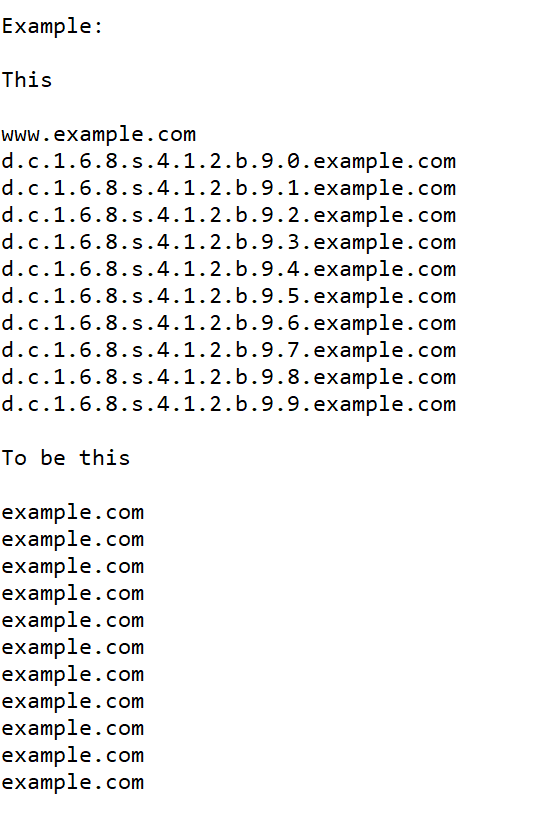
-
Hi, @mohammad-al-thobiti and All,
May I rephrase your question ? Let’s see if we mean the same goal !
So, for example, from the INPUT text, below :
abc.def.ghi.jkl.example.com all.net abc.def.example.com abc.my_site.com abc.def.ghi.all.net my_site.com abc.def.all.net abc.def.ghi.jkl.mno.opq.my_site.com example.comWith the following regex S/R :
SEARCH
(?x) ^ (?: [\w-]+ \. )* ( [\w-]+ \. [\w-]+ ) $REPLACE
\1We would get that text :
example.com all.net example.com my_site.com all.net my_site.com all.net my_site.com example.comThen, using the
Edit > Line Operations > Remove Duplicates Linesoption, we would end up with this OUTPUT :example.com all.net my_site.comIf this is exactly what you expect to, just go ahead !
BR
guy038
-
I would like to thank you for your useful information and those who contributed to this topic.
This article has become my reference. It works nicely. Yes, we mean the same goal !
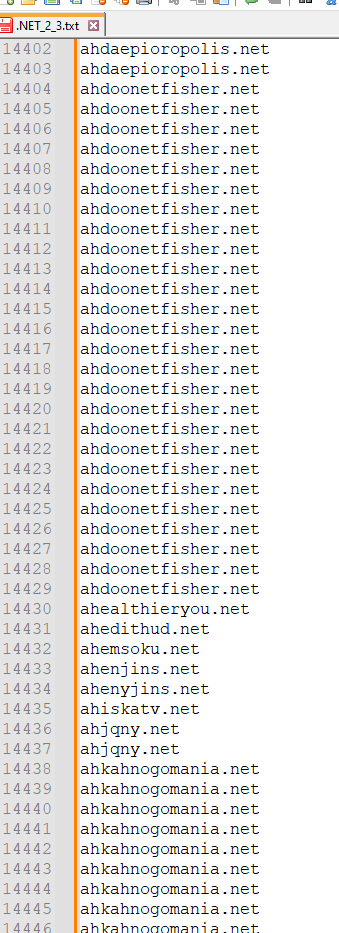
Right now. If you can sort or collect them from the most similar domains, please let me know.There are too many lines, starting with the most similar domain.
Reason: To find the most “worried” domains because it takes many lines. I will delete them later, as you told us. However, the goal is to discover more domains with many characters or long URLs and I will block them in other programs.
How can this be done?
-
@Mohammad-Al-Thobiti said in I would like to group all similar domains, not by alphabet.:
If you can sort or collect them from the most similar domains, please let me know.
Here’s a way; enter:
Find what :
^(!*([^\r\n]+))\R(!*)\2$
Replace with :!\3\1and Replace All repeatedly until there are no more changes.
Each line in the result will have an exclamation point at the beginning for each additional occurrence of the following text; so:
argh.com argh.com asdf.net asdf.net asdf.net asdf.net ef.org ef.org ef.org ef.org ef.org fasde.com fasde.com fasde.com fasde.com gorch.net gorch.net gorch.netwould become:
!argh.com !!!asdf.net !!!!ef.org !!!fasde.com !!gorch.netYou can then sort that to put them in order by the number of exclamation points at the beginning.
-
Thank you. I will clarify the issue.
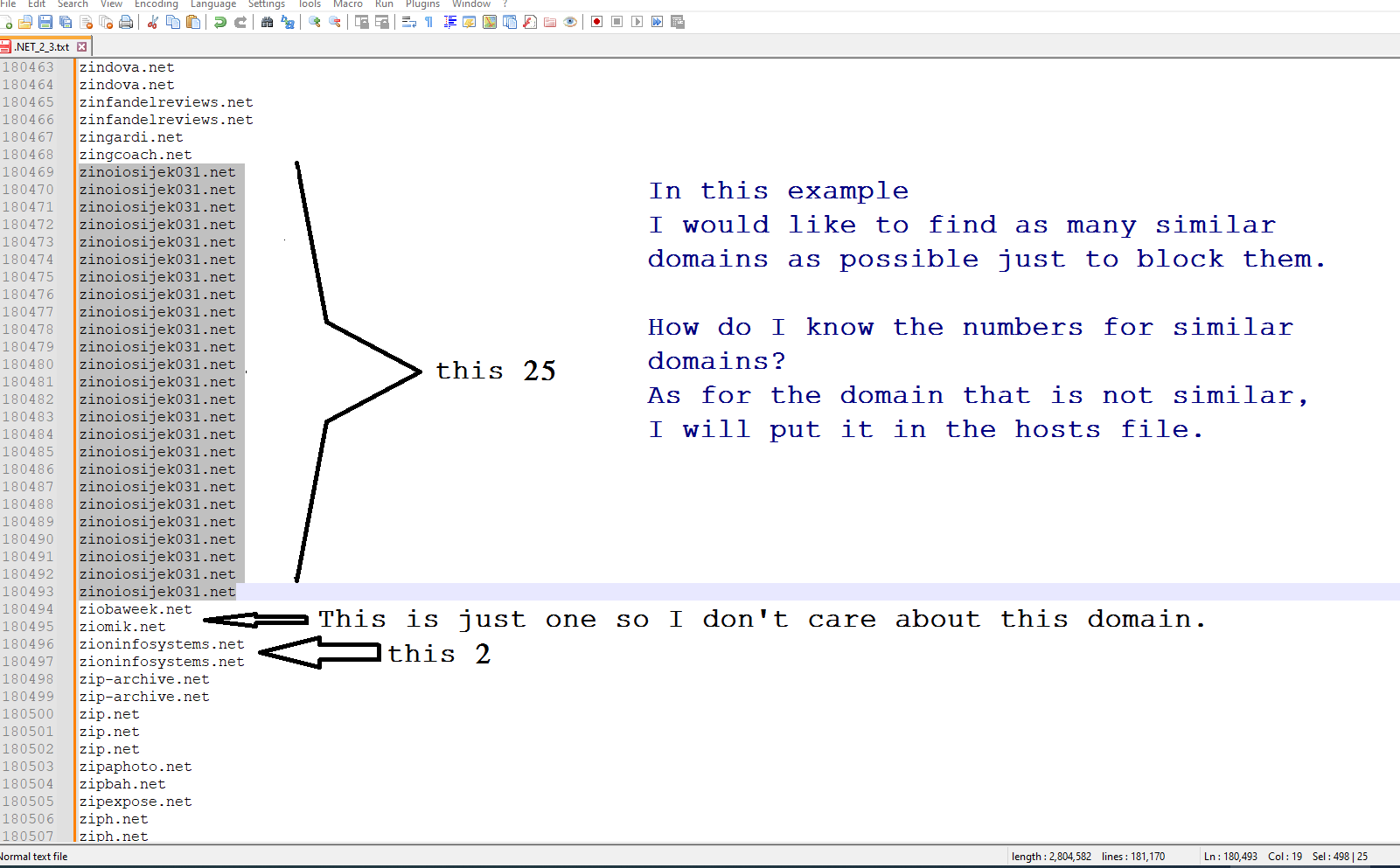
-
@Mohammad-Al-Thobiti said in I would like to group all similar domains, not by alphabet.:
Thank you. I will clarify the issue.
Using the method I suggested, if you start with:
zindova.net zindova.net zinfandelreviews.net zinfandelreviews.net zingardi.net zingcoach.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net ziobaweek.net ziomik.net zioninfosystems.net zioninfosystems.net zip-archive.netand do the repeated Replace Alls, then sort, you’ll get:
!!!!!!!!!!!!!!!!!!!!!!!!zinoiosijek031.net !zindova.net !zinfandelreviews.net !zioninfosystems.net zingardi.net zingcoach.net ziobaweek.net ziomik.net zip-archive.netThe first line represents 25 occurrences — there are 24 leading exclamation points. Each of the next three lines represent two occurrences (one leading exclamation point). The remaining lines occurred only once.
Is that not what you needed to accomplish?
-
Hello, @mohammad-al-thobiti, @peterjones, @coises and All,
Oh, @coises, your method of finding out how many times each address occurs, is very elegant and really clever ! I’d never have thought of such sophistication on my own :-((
So, @mohammad-al-thobiti, starting with this INPUT file :
zindova.net zindova.net zinfandelreviews.net zinfandelreviews.net zingardi.net zingcoach.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net zinoiosijek031.net ziobaweek.net ziomik.net zioninfosystems.net zioninfosystems.net zip-archive.net zip-archive.net zip.net zip.net zip.net zipaphoto.net zipbah.net zipexpose.net ziph.next ziph.nextI’m using the @coises’s regex, that I slightly modified :
SEARCH
(?x-s) ^ ( !* ( .+ ) ) \R ( !* ) \2 $REPLACE
!\3\1- Run it several times, in order tp get the message
Replace All: 0 occurrences were replaced
=> You should get this text :
!zindova.net !zinfandelreviews.net zingardi.net zingcoach.net !!!!!!!!!!!!!!!!!!!!!!!!zinoiosijek031.net ziobaweek.net ziomik.net !zioninfosystems.net !zip-archive.net !!zip.net zipaphoto.net zipbah.net zipexpose.net !ziph.nextNow, we just add one
!character to get the exact number of occurrences of each addressSEARCH
(?x-s) ^ (?= . )REPLACE
!!!zindova.net !!zinfandelreviews.net !zingardi.net !zingcoach.net !!!!!!!!!!!!!!!!!!!!!!!!!zinoiosijek031.net !ziobaweek.net !ziomik.net !!zioninfosystems.net !!zip-archive.net !!!zip.net !zipaphoto.net !zipbah.net !zipexpose.net !!ziph.next- Then, run the
Edit > Line Operations > Sort Lines Lexicographically Ascending
=> We get this sorted text :
!!!!!!!!!!!!!!!!!!!!!!!!!zinoiosijek031.net !!!zip.net !!zindova.net !!zinfandelreviews.net !!zioninfosystems.net !!zip-archive.net !!ziph.next !zingardi.net !zingcoach.net !ziobaweek.net !ziomik.net !zipaphoto.net !zipbah.net !zipexpose.netFinally, runing the four regex S/R, below :
SEARCH (?x-s) ^ ! (?= [^!\r\n]+ ) REPLACE 1\t SEARCH (?x-s) ^ !! (?= [^!\r\n]+ ) REPLACE 2\t SEARCH (?x-s) ^ !!! (?= [^!\r\n]+ ) REPLACE 3\t SEARCH (?x-s) ^ !!!!!!!!!!!!!!!!!!!!!!!!! (?= [^!\r\n]+ ) REPLACE 25\t=> You should end up with this OUTPUT text :
25 zinoiosijek031.net 3 zip.net 2 zindova.net 2 zinfandelreviews.net 2 zioninfosystems.net 2 zip-archive.net 2 ziph.next 1 zingardi.net 1 zingcoach.net 1 ziobaweek.net 1 ziomik.net 1 zipaphoto.net 1 zipbah.net 1 zipexpose.netWhich should be a practical document to exploit !
Best Regards,
guy038
- Run it several times, in order tp get the message
-
@ guy038 and All,
Thank you my friends for the amazing results.
We have received the correct information. The most commonly used domains cleverly.
In any case, as you can see in the picture, the outcome is wonderful.
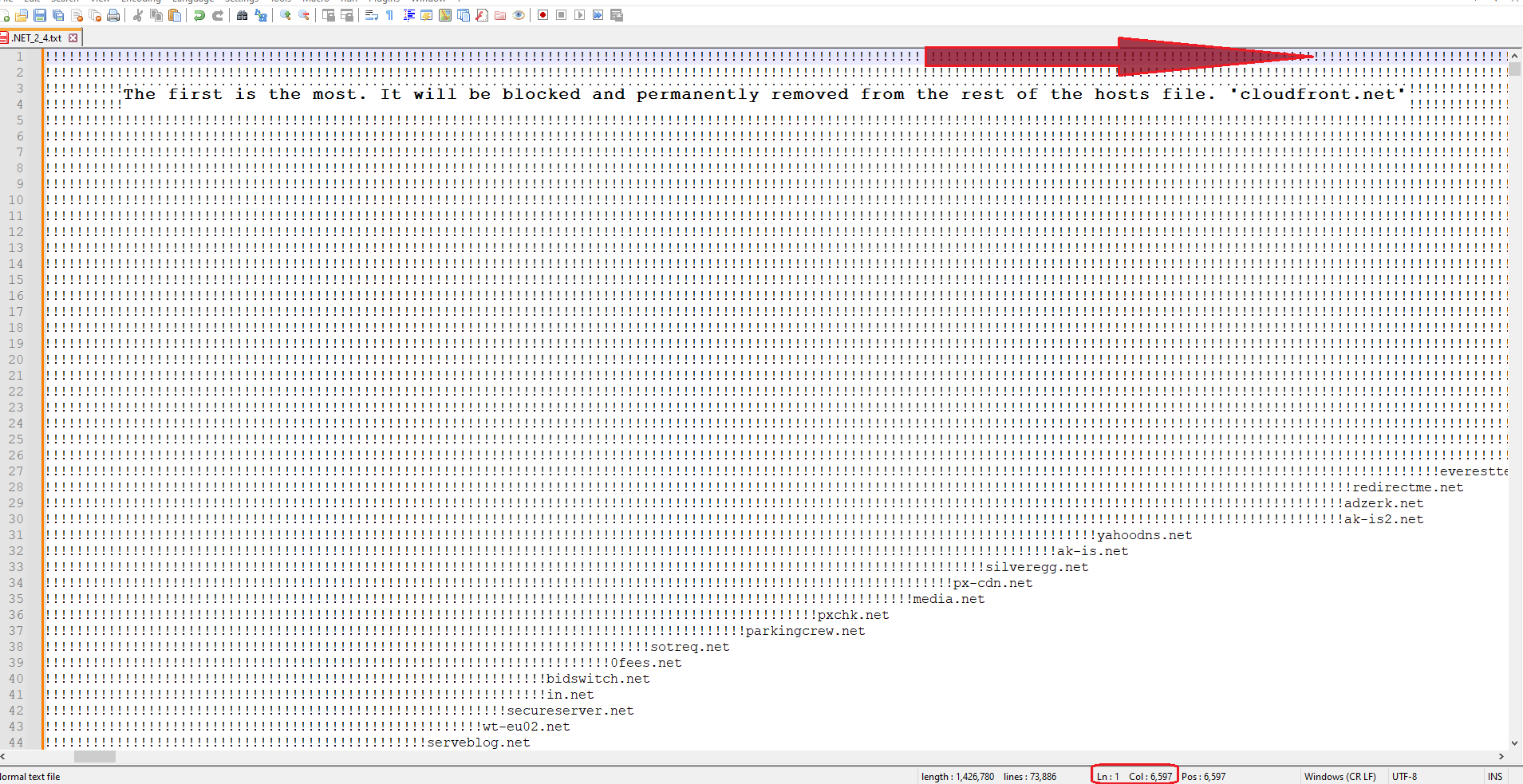
How do I write the code like this that you mentioned:
SEARCH (?x-s) ^ ! (?= [^!\r\n]+ ) REPLACE 1\t SEARCH (?x-s) ^ !! (?= [^!\r\n]+ ) REPLACE 2\t SEARCH (?x-s) ^ !!! (?= [^!\r\n]+ ) REPLACE 3\t SEARCH (?x-s) ^ !!!!!!!!!!!!!!!!!!!!!!!!! (?= [^!\r\n]+ ) REPLACE 25\tDid I write until I reached Col: 6,597? I think it is difficult and takes a lot of time. And I want to thank all of you for all your efforts on this fascinating topic.
-
@guy038 OK, I’ll take the bait… If you really want to count exclamation points:
Add the missing exclamation point, but also add a separator:
Find what :
^(!*)
Replace with :$1!/\tNow, group by tens:
Find what :
(!{10})+
Replace with :$0/followed by:
Find what :
!{10}
Replace with :!Repeat the above two steps until the first step finds nothing.
Now, count the exclamation points in each digit and remove the forward slashes:
Find what :
(?:(!{9})|(!{8})|(!{7})|(!{6})|(!{5})|(!{4})|(!{3})|(!{2})|(!{1})|())/
Replace with :(?{1}9)(?{2}8)(?{3}7)(?{4}6)(?{5}5)(?{6}4)(?{7}3)(?{8}2)(?{9}1)(?{10}0)This assumes there are no exclamation points or forward slashes elsewhere in the text. Of course, the forward slash (
/) can be replaced with any character that is not in use. -
Hi, @mohammad-al-thobiti and All,
Let’s recapitulate from the very beginning !
If we start with this kind of INPUT text :
127.0.0.1 a.z.xy.dummy-hyphen.org 127.0.0.1 a.example.com 127.0.0.1 cdef.x.example.com 127.0.0.1 my_site.net 127.0.0.1 b.dummy-hyphen.org 127.0.0.1 b.cde.fgh.example.com 127.0.0.1 abc.defgji.kkkkk.my_site.net 127.0.0.1 cd.xyztuv.ab-cd.4567.example.com 127.0.0.1 dummy-hyphen.org 127.0.0.1 example.comWith the following regex S/R :
SEARCH
(?x) ^ \Q127.0.0.1 \E \h+ (?: [\w-]+ \. )* ( [\w-]+ \. [\w-]+ ) $REPLACE
\1=> We just keep the main domain ;
dummy-hyphen.org example.com example.com my_site.net dummy-hyphen.org example.com my_site.net example.com dummy-hyphen.org example.comOf course, your present file deals with about
181,170lines !So, instead of using the last @coises’s method to find out the different occurrences of each line ( again, a very clever method ! ), I will simplify the goal by using a
Pythonscript to get the job done more quickly !This script is an adaptation from a @alan-kilborn’s script. I named this script
Count_Strings_Occurences.py# -*- coding: utf-8 -*- ''' Adapted from : https://community.notepad-plus-plus.org/topic/20598/show-a-list-of-same-word-before-replacement/2 and .../20 By DEFAULT, this script PASTES, in a NEW tab, a SORTED list of ALL the STRINGS of the CURRENT file, with their NUMBER of occurrences IF a NORMAL selection EXISTS, the script PASTES a SORTED list of ALL the STRINGS of the SELECTION, with their NUMBER of occurrences NOTES : - The CURRENT file processed DO NOT need to be SORTED, in any way ! - If you want a SORTED list of ALL the LINES with their NUMBER of occurrences, don't FORGET to INCLUDE all the POSSIBLE chars of the lines in the REGEX ! For example, if file may contain the line 'zip-archive.net', the REGEX, after editor.research, should be r'[\w.-]+', which includes the DOT and the DASH ! ''' from Npp import editor sel_start = 0 sel_end = editor.getLength() # Refer to : https://community.notepad-plus-plus.org/topic/22378/pythonscript-ops-on-selection-if-any-all-text-otherwise/3 sel_start, sel_end = editor.getUserCharSelection() word_matches = [] def match_found(m): word_matches.append(editor.getTextRange(m.span(0)[0], m.span(0)[1])) editor.research(r'[\w.-]+', match_found, 0 , sel_start, sel_end) histogram_dict = {} for word in word_matches: if word not in histogram_dict: histogram_dict[word] = 1 else: histogram_dict[word] += 1 output_list = [] for k in histogram_dict: output_list.append('{0:.<50} {1}'.format(k, histogram_dict[k])) #for k in histogram_dict: output_list.append('{}={}'.format(k, histogram_dict[k])) # INITIAl format of Alan Kilborn # For SPECIFICATIONS on the OUTPUT format, refer to : # https://doc.python.org/2.7/library/string.html#format-specification-mini-language # https://doc.python.org/2.7/library/string.html#format-examples output_list.sort() editor.copyText('\r\n'.join(output_list)) notepad.new() editor.paste() # console.clear() ; editor.research (r'\w+', lambda m: console.write (m.group(0) + '\n'))
- So, select the random list of
168lines, below.
Note that I suppose that the
IPV4addresses and the sub-domains were previously deletedzioninfosystems.net zingcoach.net ziph.net zinoiosijek031.net zindova.net zip.net zinoiosijek031.net zip-archive.net zinfandelreviews.net zindova.net zip.net zinoiosijek031.net zioninfosystems.net zip-archive.net ziomik.net zioninfosystems.net zip.net zindova.net zindova.net ziph.net ziph.net zinfandelreviews.net zinoiosijek031.net zindova.net zioninfosystems.net zindova.net zip.net zindova.net ziph.net zinfandelreviews.net zinoiosijek031.net ziph.net zinfandelreviews.net zinoiosijek031.net zinfandelreviews.net zinfandelreviews.net ziobaweek.net zinoiosijek031.net zinfandelreviews.net zindova.net zindova.net zinoiosijek031.net zinoiosijek031.net zipaphoto.net zinfandelreviews.net zinfandelreviews.net zingardi.net zip.net zipexpose.net zindova.net zip-archive.net zip-archive.net zindova.net zioninfosystems.net zipexpose.net zipaphoto.net ziph.net zipbah.net zinoiosijek031.net zinfandelreviews.net zip.net zindova.net zip.net zindova.net zingcoach.net zinoiosijek031.net zip.net ziomik.net zindova.net zinoiosijek031.net zioninfosystems.net ziph.net zioninfosystems.net zinfandelreviews.net zingardi.net zinoiosijek031.net zingardi.net zingardi.net ziph.net zingardi.net zinoiosijek031.net zinoiosijek031.net zingcoach.net zindova.net zip.net zindova.net zip-archive.net ziph.net ziobaweek.net zinfandelreviews.net zip.net zinoiosijek031.net zip.net ziomik.net zingardi.net zindova.net zinfandelreviews.net ziph.net ziobaweek.net zinoiosijek031.net zindova.net zinfandelreviews.net zip.net zingcoach.net zip-archive.net zip-archive.net zindova.net zinfandelreviews.net zingardi.net zioninfosystems.net zinoiosijek031.net ziph.net zioninfosystems.net ziobaweek.net zingcoach.net ziph.net zinoiosijek031.net ziobaweek.net zinfandelreviews.net zip.net zinoiosijek031.net ziph.net zinfandelreviews.net zindova.net zindova.net zindova.net zip-archive.net zip.net ziph.net zindova.net zioninfosystems.net zinoiosijek031.net zinoiosijek031.net ziph.net zinfandelreviews.net zip.net zingcoach.net zinfandelreviews.net zinoiosijek031.net zingardi.net zip-archive.net zip.net zinfandelreviews.net zinoiosijek031.net zindova.net zinfandelreviews.net zip.net zioninfosystems.net zingardi.net zioninfosystems.net zip-archive.net zingcoach.net zinoiosijek031.net ziomik.net zip.net zingardi.net zinfandelreviews.net zip-archive.net zindova.net ziomik.net zinoiosijek031.net zindova.net zinoiosijek031.net zinfandelreviews.net zinfandelreviews.net ziph.net zinoiosijek031.net zingardi.net- Run the
Plugins > Python Script > Scripts > Count_Strings_Occurrences.pyPython script
=> At once, a new tab will open with all the results :
zindova.net....................................... 26 zinfandelreviews.net.............................. 24 zingardi.net...................................... 11 zingcoach.net..................................... 7 zinoiosijek031.net................................ 28 ziobaweek.net..................................... 5 ziomik.net........................................ 5 zioninfosystems.net............................... 12 zip-archive.net................................... 11 zip.net........................................... 18 zipaphoto.net..................................... 2 zipbah.net........................................ 1 zipexpose.net..................................... 2 ziph.net.......................................... 16Note that the entries are sorted by the line contents, to easily access any of these !
-
Thus, do a zero-length RECTANGULAR selection of all the numbers of this new tab, at column
52 -
Run the
Edit > Line Operations > Sort Lines As Integers Descendingoption
=> You should get your expected OUTPUT :
zinoiosijek031.net................................ 28 zindova.net....................................... 26 zinfandelreviews.net.............................. 24 zip.net........................................... 18 ziph.net.......................................... 16 zioninfosystems.net............................... 12 zingardi.net...................................... 11 zip-archive.net................................... 11 zingcoach.net..................................... 7 ziobaweek.net..................................... 5 ziomik.net........................................ 5 zipaphoto.net..................................... 2 zipexpose.net..................................... 2 zipbah.net........................................ 1Here you are !
-
Proceed, in the same way, with your present file
-
Switch to your file tab ( selection and sort are not required )
-
Run again the
Plugins > Python Script > Scripts > Count_Strings_Occurrences.pyPython script -
In the opened new tab, do a zero-length RECTANGULAR selection of all the numbers, at column
52 -
Run the
Edit > Line Operations > Sort Lines As Integers Descendingoption
Bingo !
Best Regards,
guy038
- So, select the random list of