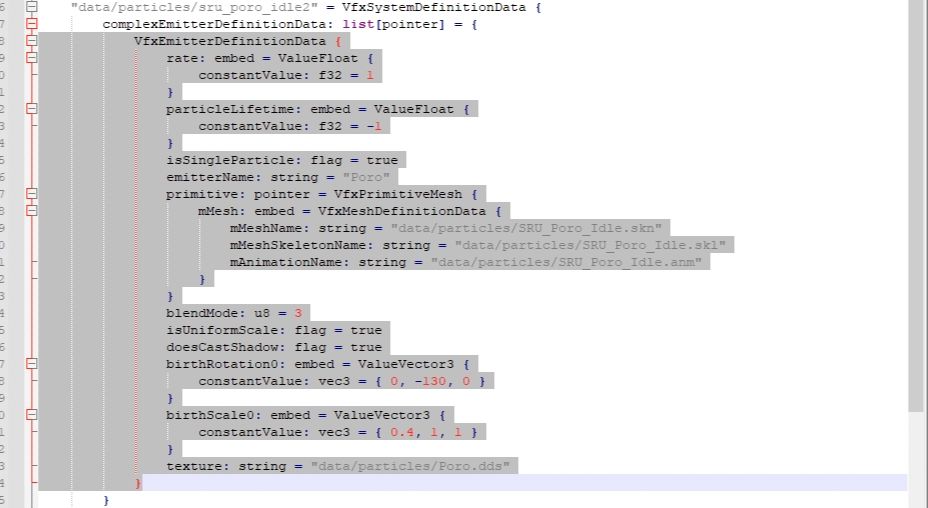
@kuzduk-kuzduk,
You earlier said,
i dont understand why Don Ho do not off by default this Special characters with unmapped “shortcut”…
And now you say
Thanks, but this doesn’t work for me because I’m using npp 8.5.8
I am sorry.
Some applications use a model where they are able to release patch fixes to old releases of software; Notepad++ does not work that way. If there are bug fixes, they go in the next revision. So, to be able to get a fix, you have to be willing to update to a new version.
(Yes, I said “willing” , not “able”, because despite your assertion, your choice to not upgrade Notepad++ instead of choosing to remap the weird PauseBreak global shortcut to something other than PauseBreak is just that… your choice. And it’s your choice to prioritize keeping PauseBreak over keeping )
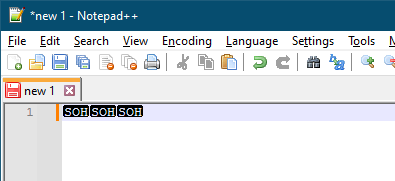
so sad, but [Alan’s script does] not work in russian layout
As an alternative, figure out all the Ctrl sequences that type ASCII control characters based on your setup. Then create a NULL macro for each of those. A “NULL macro” is a “do nothing” macro. The scintilla action 2172 is a do-nothing/no-op/null-op action. So, you could insert a macro like the following into shortcuts.xml, then save and restart:
<Macro name="NULL-CTRL-R" Ctrl="yes" Alt="no" Shift="no" Key="82" FolderName="Control Remaps">
<Action type="0" message="2172" wParam="0" lParam="0" sParam="" />
</Macro>
This mapped macro it would stop Ctrl+R from inserting the DC2 ASCII 18 control character, and instead run a no-op command, making it “do nothing”.
Creating multiple such macros, one for each unmapped sequence, would get rid of the accidental ASCII control characters in your documents. (And I showed putting it in FolderName="Control Remaps", so they would all show up in a sub-menu of Macros instead of cluttering your main Macros menu)
-----
update: earlier in this discussion, @Michael-Vincent linked to this old discussion. It turns out, my suggestion is essentially what Claudia suggested 8 years ago (good to know that her excellent answers have apparently become part of my subconscious mind), though she chose message 0 instead of 2172. And in this February’s replies to that ancient thread, @mkupper showed a mapping with lots of macros that show how to do the “one macro for each unmapped sequence” that I just suggested today. (Though I would again recommend changing to 2172, and I’d add the FolderName attribute to de-clutter the Macro menu.) And @Alan-Kilborn already made the 2172 correction in that other discussion. So basically, it turns out I said nothing new anywhere in the second half of this post of mine. ;-)