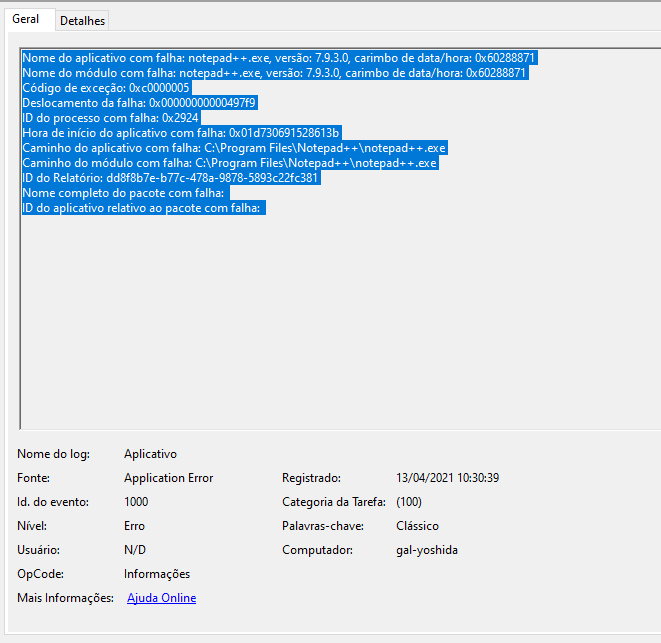
Hi, @Cristian-tanasa, and All,
I improved and generalized the process with these 8 new search regexes, in order to find part of a particular field n
Of course, I assume that :
Each row of the table contains the same number of fields
The field delimiter is the double quote char ( " )
The field separator is the semicolon ( ; )
Any field is preceded and/or followed with a ;
Any char, within a field, is different from, either, a " and a ; chars
Here are these generic regexes :
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {n-1} " \K (?1)* # ALL chars, even NONE, of FIELD n
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {n-1} " (?1){#} \K (?1)* # ALL chars, even NONE, AFTER the #th char of FIELD n
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {n-1} " (?1){#} \K (?1){p} # p chars, AFTER the #th char of FIELD n
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {n-1} " \K (?1){p} # The p FIRST chars of FIELD n
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {n-1} " (?1)* \K (?1){p} (?=") # The p LAST chars of FIELD n
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {n-1} " \K # EMPTY string, at BEGINNING of FIELD n
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {n-1} " (?1){#} \K # EMPTY string, AFTER the #th char of FIELD n
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {n-1} " (?1)* \K # EMPTY string, at END of FIELD n
Notes :
Let f be the total number of fields and let m be the maximum number of characters of the field n. Then :
The variable n is between the values 1 included and f included ( So n-1 is in range [0,f-1] )
The variable # is between the values 0 included and m included
The variable p is between the values 0 included and m included
Let’s test these 8 real regexes, below :
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {5} " \K (?1)* # ALL chars, even NONE, of FIELD 6
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {5} " (?1){10} \K (?1)* # ALL chars, even NONE, AFTER the 10th char of FIELD 6
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {5} " (?1){10} \K (?1){3} # THREE chars, AFTER the 10th char of FIELD 6
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {5} " \K (?1){5} # The 5 FIRST chars of FIELD 6
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {5} " (?1)* \K (?1){7} (?=") # The 7 LAST chars of FIELD 6
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {5} " \K # EMPTY string, at BEGINNING of FIELD 6
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {5} " (?1){10} \K # EMPTY string, AFTER the 10th char of FIELD 6
(?x) ^ (?: " ( [^";\r\n] )* " ; ) {5} " (?1)* \K # EMPTY string, at END of FIELD 6
Against the following sample text :
Field 6
V
"1000";"1";"1";"";"834600000";"";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"1";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"12";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"123";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"1234";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"12345";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"123456";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"1234567";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"12345678";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"123456789";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"1234567890";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"12345678901";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"123456789012";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"1234567890123";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"12345678901234";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"123456789012345";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"1234567890123456";"1080668 / 13341845 This is technical";"1";"EN";"Call"
"1000";"1";"1";"";"834600000";"12345678901234567";"1080668 / 13341845 This is technical";"1";"EN";"Call"
Super, isn’t it ?
Best Regards,
guy038