@PeterJones,
(I’m also really surprised that Michael’s code worked for him a few years ago; I don’t believe the definition of the MASK field of SCI_MARKERNEXT has changed in the last three years.)
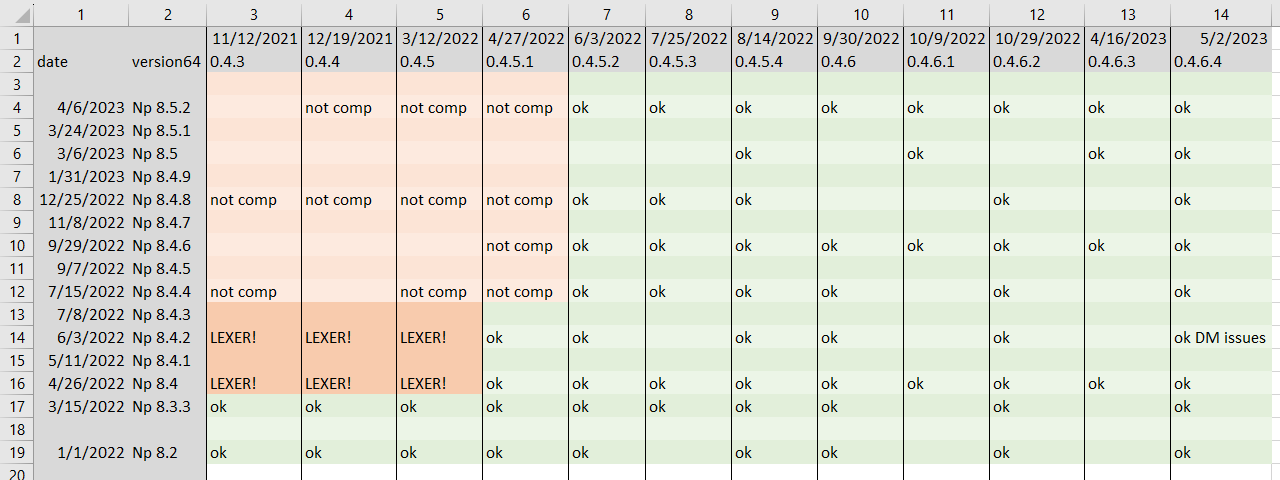
Nevermind. The definition of Notepad++'s MARK_BOOKMARK has changed in the last three years. Specifically, in v8.4.6 in Sept 2022, it was changed from 24 to 20 to work with Scintilla 5.3.0.
So just changing that single line to
SET LOCAL MASK ~ 1<<20
would have been sufficient.
In case you don’t understand: 3 years ago, when Michael wrote the script, bookmarks used mark#24, so SET LOCAL MASK ~ 1<<24 set the mask to 0x1000000, so if bit #24 matched, it would say the line number.
With v8.4.6 and newer, that marker is in bit #20, so if you only are looking at bit#24, it’s not going to find it. Your code, with 0xFFFFFF on the other hand, was looking at all marker numbers from 0 to 23, so it would find marker#20 as the bookmark line. But it would also find any of the other markers on those lines, even the ones that aren’t bookmarks – so it would find markers you weren’t looking for. If you file happened to have other marker types – like if you had any hidden lines due to View > Hide Lines or code folding in your active lexer – then it would report false matches.
Marker Number References
Scintilla reserves #25-31 for folding margins
Scintilla reserves #21-24 for Change History
Notepad++ reserves #16-20 for “internal use” (specifically, 18 & 19 for hidden lines, and 20 for bookmarks, with two more for future use)
Notepad++ allows #0-15 for plugins to use, but makes no guarantee that two plugins won’t try to make use of the same marker.