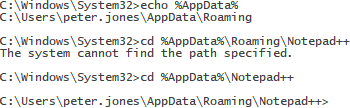
https://community.notepad-plus-plus.org/post/55641
Hello, All,
During my study of the backtracking control verbs ( see posts above ), I noticed this article which described ways to pre-define some subroutines, which can be used to build numerous modular patterns, at the same time :
https://www.rexegg.com/regex-tricks.html#pseudo-define
Note that the special conditional (?(DEFINE).....) structure was created, originally, to this purpose, by modern regex engines, including our Boost regex engine ! I already discussed of this syntax in this post below :
https://community.notepad-plus-plus.org/post/52608
So, for instance, with the free-spacing mode, the regex below :
(?x-i)
(?(DEFINE) # START of the conditional DEFINE structure
([A-Z]{2}\d) # TWO CAPITAL letters, followed with a DIGIT in Group 1
) # END of the conditional DEFINE structure
(?1)-(?1)-(?1) # THREE "Group 1" triplets, separated with DASHES
Against the string YH5-RC6-UY0-BD5-AZ3-KL9, would match the two substrings YH5-RC6-UY0 and BD5-AZ3-KL9
Now, in Rexegg site, we are told that, instead of the (?(DEFINE).....) conditional structure, we can use the (*FAIL) backtracking control verb to get a similar behavior, according to the syntax below, using an optional non-capturing group :
(?x-i)
(?: # START of an OPTIONAL NON-CAPTURING group
([A-Z]{2}\d) # TWO CAPITAL letters, followed with a DIGIT in Group 1
(*F) # Backtracking Control verb (*FAIL)
)? # END of the OPTIONAL NON-CAPTURING group
(?1)-(?1)-(?1) # THREE "Group 1" triplets, separated with DASHES
Remark that, instead of the (*F) verb, we may also use the negative look-ahead (?!) syntax for identical results
Now, I’ve found out a more simple syntax :
(?x-i)
([A-Z]{2}\d) # TWO CAPITAL letters, followed with a DIGIT in Group 1
(*F) # Backtracking Control verb (*FAIL)
| # OR
(?1)-(?1)-(?1) # THREE "Group 1" triplets, separated with DASHES
How this regex syntax works, against the string YH5-RC6-UY0-BD5-AZ3-KL9 ?
First, the regex engine tries to match the part ([A-Z]{2}\d) and, indeed, matches the substring HY5.
At the same time, it stores the pattern [A-Z]{2}\d in group 1
Then the regex engine meets the backtracking control verb (*F) which forces it to backtrack
So the current match HY5 is discarded and the starting position remains right before the first letter Y
Then the regex engine tries the other alternative ?1)-(?1)-(?1) and matches, successively, the two substrings YH5-RC6-UY0 and BD5-AZ3-KL9, as we expect to !
Note the effect of the (*FAIL) verb is exactly the same as if the regex engine would try to match a specific pattern that does not exist in subject string ! So, let simply substitute this verb with, for instance, the CURRENY sign ¤, of Unicode code point ``\x{00a4}`. which is generally not used in files !
You can use the Windows input method, hitting the Alt key and typing number 0164 on the numeric keypad
So we get the regex :
(?x-i)
([A-Z]{2}\d) # TWO CAPITAL letters, followed with a DIGIT in Group 1
¤ # The CURRENCY sign character ( In fact, any NON-EXISTENT character, in CURRENT file ! )
| # OR
(?1)-(?1)-(?1) # THREE "Group 1" triplets, separated with DASHES
Why my syntax also works :
First, the regex engine tries to match the part ([A-Z]{2}\d) and, indeed, matches the substring HY5.
At the same time, it stores the pattern [A-Z]{2}\d in group 1
But it cannot match the following currency sign ¤ and the regex engine naturally backtracks
The starting position remains right before the first letter Y
And the regex engine tries the other alternative ?1)-(?1)-(?1), which matches, successively, the two substrings YH5-RC6-UY0 and BD5-AZ3-KL9
Note that the regex engine does remember of the pattern contained in group 1 because, despite of the backtracking phase, the search process still goes on !
Of course, instead of the single character ¤, you can, either, choose a simple string, which does not exist in current file. For instance, /// or @@ or _X_
It’s also important to point out that you can perfectly use named group(s), for all these syntaxes. For instance, my last regex syntax can be rewritten :
(?x-i)
(?<Seq>[A-Z]{2}\d) # TWO CAPITAL letters, followed with a DIGIT in NAMED group 'Seq'
¤ # The CURRENCY sign character ( In fact, any NON-EXISTENT character, in CURRENT file ! )
| # OR
(?&Seq)-(?&Seq)-(?&Seq) # THREE 'Seq' triplets, separated with DASHES
Of course, all the syntaxes, above, which help us to create a library of pre-defined groups are mostly valuable, when you try to search between numerous patterns, built up from these elementary patterns !
To that purpose, let’s expose a more interesting and practical example, regarding the search of specific sequences within the genetic code !
If necessary, refer for a very basic background, about genetic code, at the end of this post !
From now on, the genetic notions invoked are only the fruit of my imagination and are, in no way, based on scientific data. !! It’s just used to demonstrate the interest of the above regex syntaxes
Let’s suppose that the 3 genetic sequences CGUUUA, GCCACUAAACAG and AAUCGACAU, named Seq_1, Seq_2 and Seq_3, are of main importance in order to build up greater genetic chains from a combination of these components
Now, let’s assume that we want, at the same time, search for the seven combinations :
Seq_2 + Seq_3
Seq_1 + Seq_2
Seq_1 + Seq_3
Seq_2 + AAA codon + Seq_3
Seq_2 + CCC codon + Seq_1
4 consecutive Seq_1 + Seq_2
4 consecutive Seq_1 + Seq_3
Then, the regex to search any of these sequences, delimited with a start and a stop codon, could be, in free-spacing mode :
(?x-i) # FREE-SPACING mode and NON-INSENSITIVE search
(?<Seq_1>CGUUUA) # Seq_1 definition ( 6 bases )
(?<Seq_2>GCCACUAAACAG) # Seq_2 definition ( 12 bases )
(?<Seq_3>AAUCGACAU) # Seq_3 definition ( 9 bases )
X | # An INEXISTANT character in RNA sequence OR
(AUG|GUG|UUG) # Possible START codons
(?<Codon>[ACGU]{3})*? # Any number of CODONS, even ZERO, in the NAMED group Codon
\K # ANYTHING matched, so far, is DISCARDED
(?: # Start of a NON-CAPTURING group
(?&Seq_2)(?&Seq_3) | # Chain 1 : Seq_2 + Seq_3 OR
(?&Seq_1)(?&Seq_2) | # Chain 2 : Seq_1 + Seq_2 OR
(?&Seq_1)(?&Seq_3) | # Chain 3 : Seq_1 + Seq_3 OR
(?&Seq_2)AAA(?&Seq_3) | # Chain 4 : Seq_2 + AAA + Seq_3 OR
(?&Seq_3)CCC(?&Seq_1) | # Chain 5 : Seq_3 + CCC + Seq_1 OR
(?&Seq_1){4}(?&Seq_2) | # Chain 6 : FOUR consecutive Seq_1 + Seq_2 OR
(?&Seq_1){4}(?&Seq_3) # Chain 7 : FOUR consecutive Seq_1 + Seq_3
) # END of the NON-CAPTURING group
(?= # START of a LOOK-AHEAD
(?&Codon)* # Any number of CODONS, even ZERO
(UAA|UGA|UAG) # Possible STOP codons
) # END of the LOOK-AHEAD
You can test this regex against these lines, below, which **all** begin with a **start** codon and end with a **stop** codon :
~~~diff
AUGUGCAACGAUCGUUUAAAUCGACAUGCCACUAAACAGUUACAUCAUACUGCCAACCAGGGCCAUGUUUAA # Chain 3
GUGAACCAGGGCCAUGUUCGUUUAAAUCGACAUAAUCGACAUAACCCCUUACUUGCUAAUUUCUGA # Chain 3
UUGCGUUUAAACCUAAAAGAUGGGGUCGCCACUAAACAGAAUCGACAUAAUCGACAUGGACCGUAG # Chain 1
UUGACUUUACAUCAUACUGCCGCCACUAAACAGAAAAAUCGACAUCCCCGUUUAAAACCUUGGAGCCCGUAG # Chains 4 then 5
AUGCGUUUACGUUUACGUUUACGUUUAGCCACUAAACAGUCAACUGGAGGAUCCCGGCAUUUUUAA # Chains 6 then 2
GUGUCGAACUGGGGAGCGCCACCUCAUAGUUGUCGUUUACGUUUACGUUUACGUUUAAAUCGACAUUGA # Chains 7 then 3
However, if we change the greedy quantifier, of the Codon group, with a lazy quantifier, we get other matches. This is expected because some areas overlap with other areas or include some others !
So, in order to correctly detect all these chains of nucleotides, we could look, only for the zero-length location, of the start of each sequence, with the appropriate regex, below :
(?x-i) # FREE-SPACING mode and NON-INSENSITIVE search
(?<Seq_1>CGUUUA) # Seq_1 definition ( 6 bases )
(?<Seq_2>GCCACUAAACAG) # Seq_2 definition ( 12 bases )
(?<Seq_3>AAUCGACAU) # Seq_3 definition ( 9 bases )
X| # An INEXISTANT character in RNA sequence OR
(?= # START of a LOOK-AHEAD
(?&Seq_2)(?&Seq_3) | # Case 1 : Seq_2 + Seq_3 OR
(?&Seq_1)(?&Seq_2) | # Case 2 : Seq_1 + Seq_2 OR
(?&Seq_1)(?&Seq_3) | # Case 3 : Seq_1 + Seq_3 OR
(?&Seq_2)AAA(?&Seq_3) | # Case 4 : Seq_2 + AAA + Seq_3 OR
(?&Seq_3)CCC(?&Seq_1) | # Case 5 : Seq_3 + CCC + Seq_1 OR
(?&Seq_1){4}(?&Seq_2) | # Case 6 : FOUR consecutive Seq_1 + Seq_2 OR
(?&Seq_1){4}(?&Seq_3) # Case 7 : FOUR consecutive Seq_1 + Seq_3
) # END of the LOOK-AHEAD
See below, with the indication of the start of each sequence :
v
AUGUGCAACGAUCGUUUAAAUCGACAUGCCACUAAACAGUUACAUCAUACUGCCAACCAGGGCCAUGUUUAA # Chain 3
v
GUGAACCAGGGCCAUGUUCGUUUAAAUCGACAUAAUCGACAUAACCCCUUACUUGCUAAUUUCUGA # Chain 3
v
UUGCGUUUAAACCUAAAAGAUGGGGUCGCCACUAAACAGAAUCGACAUAAUCGACAUGGACCGUAG # Chain 1
v v
UUGACUUUACAUCAUACUGCCGCCACUAAACAGAAAAAUCGACAUCCCCGUUUAAAACCUUGGAGCCCGUAG # Chains 4 then 5
v v
AUGCGUUUACGUUUACGUUUACGUUUAGCCACUAAACAGUCAACUGGAGGAUCCCGGCAUUUUUAA # Chains 6 then 2
v v
GUGUCGAACUGGGGAGCGCCACCUCAUAGUUGUCGUUUACGUUUACGUUUACGUUUAAAUCGACAUUGA # Chains 7 then 3
Now, if we want to completely match each composite sequence, we’ll use this last regex :
(?x-i) # FREE-SPACING mode and NON-INSENSITIVE search
(?<Seq_1>CGUUUA) # Seq_1 definition ( 6 bases )
(?<Seq_2>GCCACUAAACAG) # Seq_2 definition ( 12 bases )
(?<Seq_3>AAUCGACAU) # Seq_3 definition ( 9 bases )
X| # An INEXISTANT character in RNA sequence OR
(?: # START of a NON-CAPTURING group
(?&Seq_2)(?&Seq_3) | # Case 1 : Seq_2 + Seq_3 OR
(?&Seq_1)(?&Seq_2) | # Case 2 : Seq_1 + Seq_2 OR
(?&Seq_1)(?&Seq_3) | # Case 3 : Seq_1 + Seq_3 OR
(?&Seq_2)AAA(?&Seq_3) | # Case 4 : Seq_2 + AAA + Seq_3 OR
(?&Seq_3)CCC(?&Seq_1) | # Case 5 : Seq_3 + CCC + Seq_1 OR
(?&Seq_1){4}(?&Seq_2) | # Case 6 : FOUR consecutive Seq_1 + Seq_2 OR
(?&Seq_1){4}(?&Seq_3) # Case 7 : FOUR consecutive Seq_1 + Seq_3
) # END of a NON-CAPTURING group
See, below, the indication of each sequence with the v letter or the ^ symbol :
vvvvvvvvvvvvvvv
AUGUGCAACGAUCGUUUAAAUCGACAUGCCACUAAACAGUUACAUCAUACUGCCAACCAGGGCCAUGUUUAA # Chain 3
vvvvvvvvvvvvvvv
GUGAACCAGGGCCAUGUUCGUUUAAAUCGACAUAAUCGACAUAACCCCUUACUUGCUAAUUUCUGA # Chain 3
vvvvvvvvvvvvvvvvvvvvv
UUGCGUUUAAACCUAAAAGAUGGGGUCGCCACUAAACAGAAUCGACAUAAUCGACAUGGACCGUAG # Chain 1
vvvvvvvvvvvvvvvvvvvvvvvv # Chain 4
UUGACUUUACAUCAUACUGCCGCCACUAAACAGAAAAAUCGACAUCCCCGUUUAAAACCUUGGAGCCCGUAG
^^^^^^^^^^^^^^^^^^ # Chain 5
vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv # Chain 6
AUGCGUUUACGUUUACGUUUACGUUUAGCCACUAAACAGUCAACUGGAGGAUCCCGGCAUUUUUAA
^^^^^^^^^^^^^^^^^^ # Chain 2
vvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvvv # Chain 7
GUGUCGAACUGGGGAGCGCCACCUCAUAGUUGUCGUUUACGUUUACGUUUACGUUUAAAUCGACAUUGA
^^^^^^^^^^^^^^^ # Chain 3
Note that, in order to get, successively, all the occurrences, even in case of overlapping, hit the F3 shortcut to get a match. Then, hit the Left arrow, followed by the Right arrow, to advance of one position in text !
At last, I would say that it’s obvious that I’m not competing, with my simple regexes, against all the powerful ORF finding tools used by biologists ;-)) Refer to :
https://en.wikipedia.org/wiki/Open_reading_frame#ORF_finding_tools
Best Regards,
guy038
Here is a very basic summary, about genetic code, for the sole purpose of that present discussion :
DNA is a double ordered helix chain, made of four nucleotides, associated by pairs, adenine ( A ) with thymine ( T ) and guanine ( G ) with cytosine ( C ), which carries all the genetic instructions for development, functioning, growth and reproduction of all known living organisms
A gene is a sequence of nucleotides that encodes, either, the synthesis of the RNA molecule from the DNA molecule or the synthesis of a protein from a RNA molecule and may contain more than 1,000 pairs of nucleotides. Humans have nearly 20,000 genes, whose about 2,000 are thought essential to our survival !
Each triplet of nucleotides, named codon, part of a double-stranded DNA or part of a single-stranded RNA molecule, corresponds to an amino-acid, during the transcription process to RNA or during the translation process to a protein
A single translated region of the genetic code, in the DNA molecule, is called an ORF ( Open reading Frame ), containing, generally, a minimum of 100 to 150 codons
After the transcription phase, from the DNA molecule into Pre-mRNA and the suppression of introns, we get the mature RNA molecule, made of four nucleotides, associated by pairs, too : adenine ( A ) with uracil ( U ) and guanine ( G ) with cytosine ( C )
In RNA, the ORF zone has become the Protein Coding Region, composed of :
A start codon [ AUG , GUG , UUG ]
A continuous stretch of codons
A stop codon [ UAA , UGA , UAG ]
If we consider, for instance, the genome of the Escherichia Coli bacteria K-12, the proportions of each start and stop codons are :
START
STOP
Codon
Codon
AUG 83%
UAA 63%
GUG 14%
UGA 29%
UUG 3%
UAG 8%
Refer also to :
https://en.wikipedia.org/wiki/Introduction_to_genetics
https://en.wikipedia.org/wiki/DNA
https://en.wikipedia.org/wiki/RNA
https://en.wikipedia.org/wiki/Gene
https://en.wikipedia.org/wiki/Open_reading_frame
https://en.wikipedia.org/wiki/Start_codon
https://en.wikipedia.org/wiki/Stop_codon