Hi, @hello313241, @michael-vincent, @terry-r and All,
Very, very clever solution Terry ! Indeed, no need for \K and just to type in half the screen size of spaces, in the Replace zone ;-))
And I also improved the process as we do not need, any more, to trim the trailing blank chars at the end. In addition to the mandatory regex part .{80}, I placed, before, a look-ahead (?=(.+[^\x20\r\n])\x20+) which splits these 80 characters in two zones :
A first zone (.+[^\x20\r\n]) which must end with a non-blank and Non-EOL character, to rewrite in replacement ( \2 )
A second zone \x20+ of blank characters only, to ignore
So we need two regex S/R, only ( Note that I follow my previous post with 140 characters for screen size )
The first S/R removes possible blank chars of a pure blank line OR replace any range, possibly null, of leading and trailing blank chars with 70 space characters ( 140 / 2 )
SEARCH ^\h*$|(^\h*|\h*$)
REPLACE ?1<followed with 70 spaces>
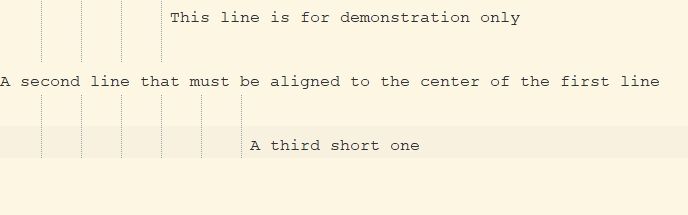
The second S/R replaces any full line of the selection, magically, with the range of ( 140 - L ) / 2 space chars, followed by the text to be centered, of size S :
SEARCH (?-s)^(\x20*)(?=(.+[^\x20\r\n])\x20+).{140}\1\x20?
REPLACE \2
Remarks :
As the total of any line of the selection is 140 + S characters long, thus the length of the surrounded range \1 is S/2 characters
I had to add the final \x20? regex because, in case the size S is an odd number, this extra space char is also matched and deleted after replacement !
All lines of the selection must have a size inferior or equal to 140. Lines, with size over 140, are shifted by 140 / 2 space characters !
So, the final macro is now simplified as :
<Macro name="Center Selected Lines" Ctrl="no" Alt="no" Shift="no" Key="0">
<Action type="3" message="1700" wParam="0" lParam="0" sParam="" />
<Action type="3" message="1601" wParam="0" lParam="0" sParam="^\h*$|(^\h*|\h*$)" />
<Action type="3" message="1625" wParam="0" lParam="2" sParam="" />
<Action type="3" message="1602" wParam="0" lParam="0" sParam="?1 " />
<Action type="3" message="1702" wParam="0" lParam="640" sParam="" />
<Action type="3" message="1701" wParam="0" lParam="1609" sParam="" />
<Action type="3" message="1700" wParam="0" lParam="0" sParam="" />
<Action type="3" message="1601" wParam="0" lParam="0" sParam="(?-s)^(\x20*)(?=(.+[^\x20\r\n])\x20+).{140}\1\x20?" />
<Action type="3" message="1625" wParam="0" lParam="2" sParam="" />
<Action type="3" message="1602" wParam="0" lParam="0" sParam="\2" />
<Action type="3" message="1702" wParam="0" lParam="640" sParam="" />
<Action type="3" message="1701" wParam="0" lParam="1609" sParam="" />
</Macro>
For instance, this initial text, where I used some sentences from the License.txt file and add some trailing blank chars :
This example works ONLY IF the TOTAL size of your SCREEN contains 140 characters
ADAPT to your CONFIGURATION, by adding HALF the APPROPRIATE number of SPACES, after "?1", in the REPLACEMENT zone of the 2ND regex S/R
><
><
><
Copyright (C)2016 Don HO <don.h@free.fr>
The licenses for most software are designed to take away your freedom to share and change it
1
Copyright (C) 1989, 1991 Free Software Foundation, Inc.
ABCD
Everyone is permitted to copy and distribute verbatim copies
You may charge a fee for the physical act of transferring a copy, and you may at your option offer warranty protection in exchange for a fee
12345 12345 12345 12345 12345
az
1
To protect your rights, we need to make restrictions that forbid anyone to deny you these rights or to ask you to surrender the rights.
1234567890
><
><
><
Would be modified and centered as below :
This example works ONLY IF the TOTAL size of your SCREEN contains 140 characters
ADAPT to your CONFIGURATION, by adding HALF the APPROPRIATE number of SPACES, after "?1", in the REPLACEMENT zone of the 2ND regex S/R
><
><
><
Copyright (C)2016 Don HO <don.h@free.fr>
The licenses for most software are designed to take away your freedom to share and change it
1
Copyright (C) 1989, 1991 Free Software Foundation, Inc.
ABCD
Everyone is permitted to copy and distribute verbatim copies
You may charge a fee for the physical act of transferring a copy, and you may at your option offer warranty protection in exchange for a fee
12345 12345 12345 12345 12345
az
1
To protect your rights, we need to make restrictions that forbid anyone to deny you these rights or to ask you to surrender the rights.
1234567890
><
><
><
Best Regards,
guy038