Hi, @matthews-dylan and All,
I apologize for my very late reply, but I needed to do numerous verifications and tests ! I’m going to start with some general topics, and, then, I’ll come back to your specific problem to tell you why your second regex ^(.)*$ matches empty lines only and I’ll give you a solution in order to delete any line which does not contain any Emoji character. Take your time and have a drink : this post is quite long ;-))
First, I would say that most of the monospaced fonts, using in code editors, can display the glyphs of traditional characters only ! So, you need to get a more robust font, which could display most of Unicode symbols properly ;-))
So, refer to the last section of my other post, below :
https://community.notepad-plus-plus.org/post/50673
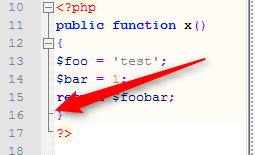
Now, after pasting the input line of your post, with my current N++ Courier New font, I get the line, below, where your character, not handled with that font, is simply replaced with a small white square box :
`Input line: □
To get information in that character, refer, again, to the last section of this other post, which speaks about a very handy on-line UTF-8 tool :
https://community.notepad-plus-plus.org/post/50983
With the help of this tool, we deduce that your special char has the following characteristics :
Character name SPLASHING SWEAT SYMBOL
Hex code point 1F4A6
Decimal code point 128166
Hex UTF-8 bytes F0 9F 92 A6
Octal UTF-8 bytes 360 237 222 246
UTF-8 bytes as Latin-1 characters bytes ð <9F> <92> ¦
Hex UTF-16 Surrogates D83D DCA6
Refer to the link, below, to see all the characters of the Unicode Miscellaneous Symbols and Pictographs block :
http://www.unicode.org/charts/PDF/U1F300.pdf
Note that the Unicode code-point of this character is 1F4A6, which is over the first 65536 characters of the Basic Multilingual Plane ( BMP ) Therefore, this means that :
It is correctly encoded in an UTF-8 encoded file. So, you must use the N++ UTF-8 or UTF-8 BOM encodings, which can handle all Unicode characters, from \x{0000} to \x{10FFFF}
It cannot be inserted in an ANSI encoded file, which handle 256 characters, only, from \x{00} to \x{FF}
It cannot be inserted in a N++ UCS-2 BE BOM and UCS-2 LE BOM encoded file, which can handle only the 65536 characters of the BMP, from \x{0000} to \x{FFFF}
Moreover, as the code-point of your character is over \x{FFFF} :
It cannot be represented with the regex syntax \x{1F4A6}, due a bug of the present Boost regex engine, which does not handle all characters in true 32-bits encoding :-(( Also, searching for \x{1F4A6} results in the error message Find: Invalid regular expression
The simple regex dot symbol . cannot match a character, with Unicode code-point > \x{FFFF}, too !
Luckily, if you paste your character in the Find what: zone, it does find all occurrences of the SPLASHING SWEAT SYMBOL character !
Now, the surrogates mechanism allows the UTF-16 encoding ( not used in Notepad++ ) to be able to code all characters with code-point over \x{FFFF}. Refer below :
https://en.wikipedia.org/wiki/UTF-16#Description
And I found out that if I write a regex, involving the surrogates pair ( 2 16-bit units ) of a character, which is over the BMP, the regex engine is able to match this character. For instance, as the surrogates pair of your character are : D83D DCA6, the regex \x{D83D}\x{DCA6} does find all occurrences of your SPLASHING SWEAT SYMBOL character !
I’ve done a lot of tests and, unfortunately, using a similar syntax, to get any char, with code over \x{FFFF}, most of the regexes do not work.
Indeed, as the high 16-bits surrogate belongs to the [\x{D800}-\x{DBFF}] range and the low 16-bits surrogate belongs to the [\x{DC00}-\x{DFFF}] range :
The regex [\x{D800}-\x{DBFF}][\x{DC00}-\x{DFFF}] does not find any match
The regex [\x{D800}-\x{DBFF}]\x{DCA6} does not find any match, too
Luckily, the regex \x{D83D}[\x{DC00}-\x{DFFF}] does match your special 💦 character :-))
So, in summary, because of the wrong handling of characters, in the present implementation of the Boost Regex library, within Notepad++ :
To match any standard character, from \x{0000} to \x{FFFF} ( NOT EOL chars and the Form Feed char \x0c ), use the simple regex .
To match any standard character from \x{10000} to \x{10FFFF}, use the regex .[\x{DC00}-\x{DFFF}] OR the shorter syntax ..
To match all standard characters, from \x{0000} to \x{10FFFF}, use the regex .[\x{DC00}-\x{DFFF}]? OR the shorter syntax ..?
And :
To match a specific character of the BMP, from \x{0000} to \x{FFFF} use the regex syntax \x{....}, with four hexadecimal numbers
To match a specific character over the BMP, from \x{10000} to \x{10FFFF}, use the high and low surrogates equivalent pair, with the regex syntax \x{<high>}\x{<low>}, replacing the <high> and <low> values with their exact hexadecimal values, using 4 hexadecimal numbers
First example :
From the list of chars, below :
•----------------------------------•------------•-------•-------------------------•-------------------•--------------------------•
| Character NAME | Code-Point | Char | In a UTF-8 encoded file | Hex-16 Surrogates | SEARCH Regex |
•----------------------------------•------------•-------•-------------------------•-------------------•--------------------------•
| LATIN CAPITAL LETTER A | 0041 | A | 41 | N/A | \x{0041} or . |
| MATHEMATICAL BOLD CAPITAL A | 1D400 | 𝐀 | F0 9D 90 80 | D835 + DC00 | \x{D835}\x{DC00} or .. |
| COMBINING GRAVE ACCENT BELOW | 0316 | ̖ | CC 96 | N/A | \x{0316} or . |
| COMBINING LEFT ANGLE ABOVE | 031A | ̚ | CC 9A | N/A | \x{031A} or . |
| MUSICAL SYMBOL COMBINING MARCATO | 1D17F | 𝅿 | F0 9D 85 BF | D834 + DD7F | \x{D834}\x{DD7F} or .. |
•----------------------------------•------------•-------•-------------------------•-------------------•--------------------------•
We may build up some COMPOSED characters, as below :
•-----------------------•-------•-------------------------•----------------------------•--------------------------------------------•
| Code-Points | Chars | In a UTF-8 encoded file | Hex-16 Surrogates | SEARCH Regex |
•-----------------------•-------•-------------------------•----------------------------•--------------------------------------------•
| 0041 + 031A | A̚ | 41 CC 9A | NO | \x{0041}\x{031A} or .. |
| 0041 + 1D17F | A𝅿 | 41 F0 9D 85 BF | D834 + DD7F ( on 2nd char) | \x{0041}\x{D834}\x{DD7F} or ... |
| 1D400 + 031A | 𝐀̚ | F0 9D 90 80 CC 9A | D835 + DC00 ( on 1st char) | \x{D835}\x{DC00}\x{031A} or ... |
| 1D400 + 1D17F | 𝐀𝅿 | F0 9D 90 80 F0 9D 85 BF | D835 + DC00 + D834 + DD7F | \x{D835}\x{DC00}\x{D834}\x{DD7F} or .... |
| 0041 + 1D17F + 031A | A𝅿̚ | 41 F0 9D 85 BF CC 9A | D834 + DD7F ( on 2nd char) | \x{0041}\x{D834}\x{DD7F}\x{031A} or .... |
| 0041 + 031A + 1D17F | A𝅿̚ | 41 CC 9A F0 9D 85 BF | D834 + DD7F ( on 3rd char) | \x{0041}\x{031A}\x{D834}\x{DD7F} or .... |
| 1D400 + 031A + 0316 | 𝐀̖̚ | F0 9D 90 80 CC 9A CC 96 | D835 + DC00 ( on 1st char) | \x{D835}\x{DC00}\x{031A}\x{0316} or .... |
•-----------------------•-------•-------------------------•----------------------------•--------------------------------------------•
Second example: If we use any of the 3 following regex S/R :
SEARCH (?-s)^.+(.[\x{DC00}-\x{DFFF}]).+
or :
SEARCH (?-s)^.+\x20(..)\x20.+
or :
SEARCH (?-s)^.+(\x{D83D}\x{DCA6}).+
and :
REPLACE A necklace of the SPLASHING SWEAT SYMBOL ––\1––\1––\1––\1––\1––\1––\1––\1––\1––
against the text This is the 💦 character, at the beginning a line, we get the resulting text :
A necklace of the SPLASHING SWEAT SYMBOL ––💦––💦––💦––💦––💦––💦––💦––💦––💦––
Now, let’s go back to your problem :
Fundamentally, the problem arise because your special 💦 character can be matched with the regex .., only, regarding our present regex engine. It looks like, for these characters, the regex engine don’t see the character itself, but the two surrogate 16-bits code units !
When you process the regex ^.*$ against your text : Input line: 💦, it does match the entire line, as the regex syntax .* means any number of chars ( . or .. or ..., and so on )
Now, let’s consider the following regex syntaxes, with a capturing group 1, against this 4-lines text, pasted in a new tab :
💦
Input line: 💦
Note that the 1st and 3rd line are empty, the 2nd line contains your 💦 special char, only and the 4th line ends with that special char
Regarding the following regex examples, below, you may test them, using the -->\1<-- Replace zone
Before, a quick remainder :
The INPUT text :
167844894321
16784
4566499
with the regex S/R :
SEARCH (\d)+
REPLACE -->\1<--
would result in :
-->1<--
-->4<--
-->9<--
As you can see, group 1 always contains the last stored value of the group. So, the regex could also have been rewritten as \d+(\d)
The regex ^(.)$ cannot find anything, as no character, with code <= \x{FFFF}, exists between beginning and end of line
The regex ^(..)$ does find, in line 2, your 💦 special character, with code > \x{FFFF}, between beginning and end of line
Your regex ^(.)*$ simply matches the true empty lines 1 and 3. WHY ?
Well, as the group contains only one dot ., it cannot match your last 💦 special character, in line 2 and 4, which needs to be considered as a pseudo two-chars entity. So the overall regex fails, in these lines !
The regex ^(..)*$ does match all the lines of the subject text, because, luckily, the part Input line:, followed with a space char, is exactly 12 chars long, so an even number ! And the last value of group 1 is your 2-chars 💦 special char, right before the end of the line
Notes :
The regex ^.*(..)$ would match all the non-empty lines 2 and 4, because group 1, .., represents your 💦 special char, ending these lines
And the regex ^(?:..){6}(..)$ would match the line 4, only
The regex ^.............(.)$ does not work properly, because group1 does not contain the 💦 special character ( See after the replacement ! )
On the contrary, the regex ^............(..)$ does find all contents of line 4, as the group 1, .., contains, exactly, the 💦 special character
On the other hand :
The regex ^(.)* selects as many standard characters, with code-point <= \x{FFFF}, so the following strings, but NOT your LAST 💦 special character !
The null string before your 💦 special char, in line 2
The string Input line:, followed with a space char, in line 4
And, finally :
The two regexes (.*)$ and (.*), with group 1 selecting all line contents, would match the four lines
Now, your last goal : let’s suppose that you would like to delete any line, which does not contain any Unicode Emojis character :
First, from that link :
http://www.unicode.org/charts/PDF/U1F600.pdf
We learn that the Unicode Emoticons block have code-points between \x{1F600} and \x{1F64F}
With the on-line UTF-8 toll, we verify that the two Hex UTF-16 surrogates are :
D83D DE00, for the \x{1F600} emoticon
D83D DE4F, for the \x{1F64F} emoticon
So, we should match all the characters of the Unicode Emoticons block, with the search regex :
SEARCH \x{D83D}[\x{DE00}-\x{DE4F}]
And, yes, it does work as expected. In that case, deleting any non-empty line which does not contain any Emoticon character(s) is easy with the following regex S/R :
SEARCH (?-s)^(?!.*\x{D83D}[\x{DE00}-\x{DE4F}]).+\R
REPLACE Leave EMPTY
In contrast, the regex S/R :
SEARCH (?-s)^(?=.*\x{D83D}[\x{DE00}-\x{DE4F}]).+\R
REPLACE Leave EMPTY
would delete any non-empty line containing one or more emoticon character(s) !
Not asleep yet ? That’s good news :-))
Best Regards,
guy038
P.S. :
Let’s suppose that, instead of the small Unicode Emoticons block, containing 80 characters, we would like to search for any character belonging to the Unicode Miscellaneous Symbols and Pictographs block, which contains 768 characters and where your special 💦 char takes place
Right now, it’s getting really inextricable ! The Unicode range of that block is from \x{1F300} to \x{1F5FF}, but, because of the surrogates mechanism, it must be split in two parts :
The range of chars between \x{1F300} and \x{1F3FF}, so with surrogates pairs D83C DF00 to D83C DFFF
The range of chars between \x{1F400} and \x{1F5FF}, so with surrogates pairs D83D DC00 to D83D DDFF
Therefore, the correct regex to match all the characters of this block is, indeed :
\x{D83C}[\x{DF00}-\x{DFFF}]|\x{D83D}[\x{DC00}-\x{DDFF}]
with an alternative between two regexes, in order to match each subset !
I confirm that this regex does find the 768 characters of the Unicode Miscellaneous Symbols and Pictographs block, with code-point over \x{FFFF} !
It’s really a pity that the N++ regex engine does not handle correctly all the characters outside the BMP. If so, we just would have to simply use the classical [\x{1F300}-\x{1F5FF}] character class !!