@Michael-Madison said in Replacing A unique ID value with another based on a reference table in multiple text files:
I am sure this has been covered, in one way or another, but the searches come up with very code heavy solution that leave me clueless, and I have zero idea what i am doing.
Unfortunately, the problem you described is best dealt with using either code or a data management tool. Notepad++ is a text editor. While you can use Notepad++'s search/replace to do some crude data management tasks you end up with stuff that is both hard to create and harder to maintain.
I’ll use the idea proposed by @Mark-Olson and show this example. Let’s say we have a list of ten 6-digit WELL numbers and their corresponding 14-digit numbers.
729647 01816277784739
832291 05203379882010
323016 08529698086864
852429 25301745193483
613474 43535571764114
421123 69712418942707
495790 62415119153289
901250 16906577703160
214509 29859837478695
936045 11344788176363
A search/replace on multiple files of:
Search: (?-i)(?<=^WELL,")(?:(729647)|(832291)|(323016)|(852429)|(613474)|(421123)|(495790)|(901250)|(214509)|(936045))(?="$)
Replace: (?1(01816277784739))(?2(05203379882010))(?3(08529698086864))(?4(25301745193483))(?5(43535571764114))(?6(69712418942707))(?7(62415119153289))(?8(16906577703160))(?9(29859837478695))(?10(11344788176363))
will translate files containing
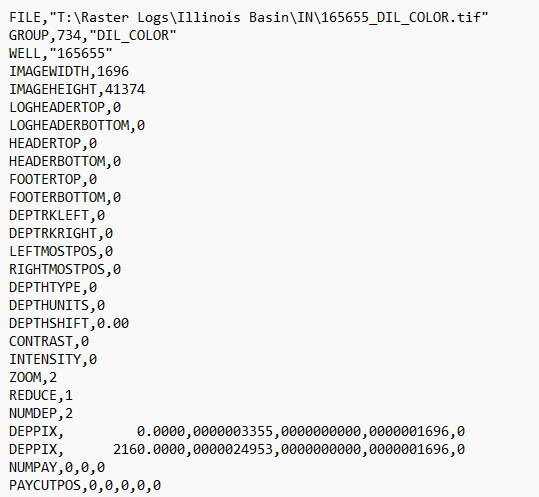
WELL,"729647"
WELL,"832291"
WELL,"323016"
WELL,"852429"
WELL,"613474"
WELL,"421123"
WELL,"495790"
WELL,"901250"
WELL,"214509"
WELL,"936045"
into files containing
WELL,"01816277784739"
WELL,"05203379882010"
WELL,"08529698086864"
WELL,"25301745193483"
WELL,"43535571764114"
WELL,"69712418942707"
WELL,"62415119153289"
WELL,"16906577703160"
WELL,"29859837478695"
WELL,"11344788176363"
You can expand that search/replace to deal with 20, maybe 30, translations at a time. The issue is that there’s a 1000 to 2000 character limit how long search/replace expressions can be. My example works for dealing with ten values at a time. I did not push the concept to see what the limit is. You said you had thousands of values meaning you would need to construct dozens, and possibly hundreds, of search/replace operations and to run them on all the data files.
This is an area where code shines vs dealing with it in Notepad++ alone as code can easily deal with translating a value such as 421123 into the desired 69712418942707. You run that on all your files and you will have the 14-digit WELL values.