@john-english said in Default file name for save?:
I’d prefer to save my energy to teach things that are worthwhile, not just bodging around problems in the tools they have to use.
With this sort of attitude, it’s no wonder today’s students aren’t well-prepared for being out in the real world, dealing with problems that they will encounter.
I don’t know…this whole thread is filled with your complaints about other tools that do things poorly, but you are taking out your frustrations on poor Notepad++, that is really only trying to give you a hint to give your files a good name (and not new 4.cpp, not new-4.cpp) when you save them. That point, which I’ve tried to make twice now, seems to be lost on you.
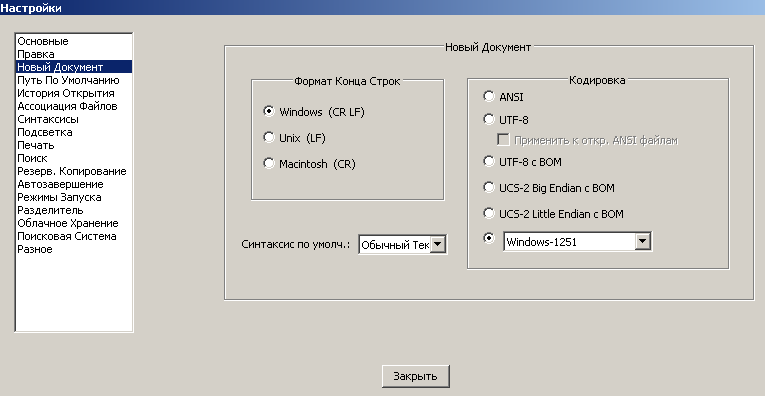
Pity it’s such a non-obvious way to change a setting.
Software developers don’t have infinite time to develop a nice and tidy solution that makes everyone happy, for everything that anyone might possibly want. On this one, if I were you, I’d be grateful that there is a way to do what’s wanted, even if “non obvious”.
My prejudice is that too many programs do not handle spaces correctly, so it is they you should be delivering your lecture to, not me.
So the people that are providing support for Notepad++ get chided, even though Notepad++ handles spaces just fine; nice.
There really isn’t anything more to say here (it’s all too dumb), except “I’m blocking the poster”.