@W-TX ,
One must first maximize one pane and hide another to start to do a search.
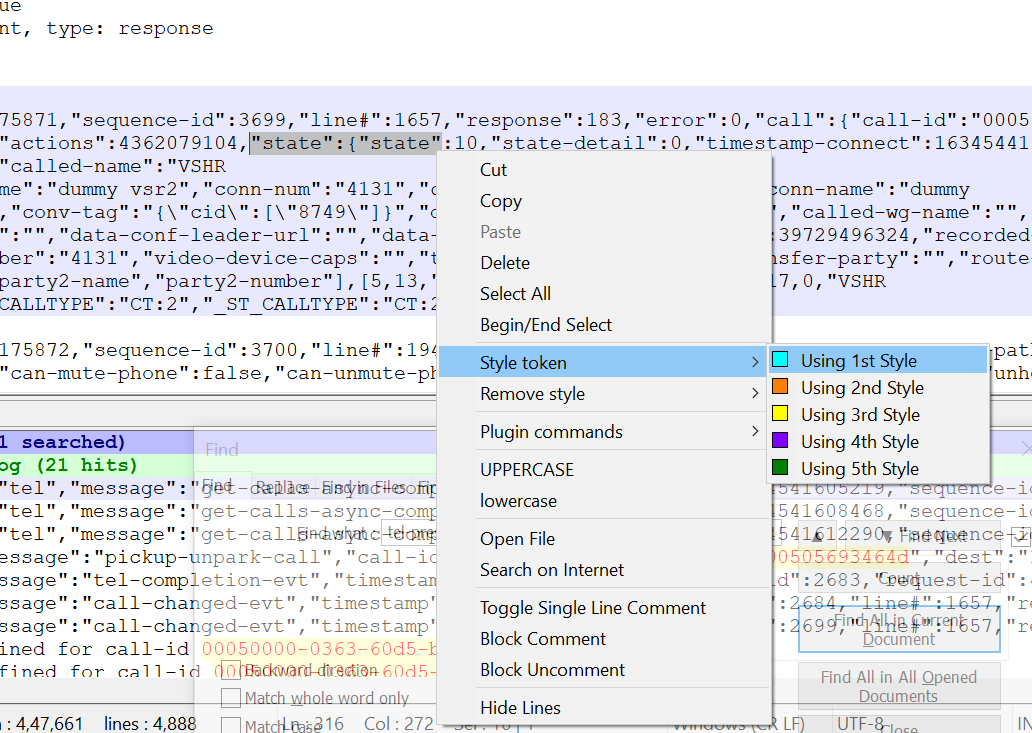
What part of “whether I’ve got the view collapsed (using the < or > arrow on the dividing line) to just primary, or just secondary” did you not understand? The “collapsed” is the correct terminology which aligns with your “maximize”. I even told you what I clicked to do that, which should have been enough to overcome any language barrier.
Please search for a string, not a word
A word is a string. The search engine makes no distinction.
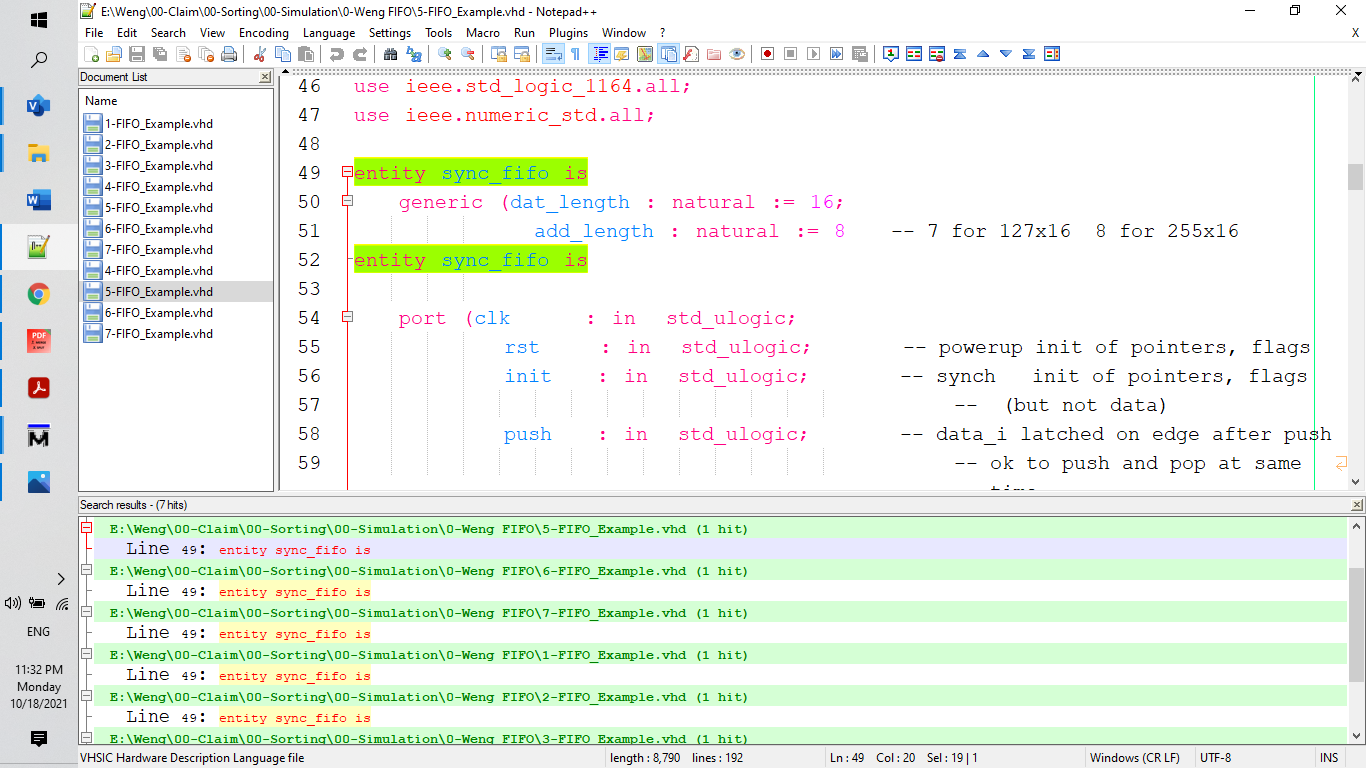
, alternately click an item in the document list pane and search result pane, prefer not to touch the file view pane
I never touched the file view pane during that experiment.
I am waiting for other people to repeat the procedure to reproduce the bug.
You will likely be waiting a long time, unless you can provide a simpler way of reproducing the bug.
finally get the bug removed by code designers
If there really is a bug, and others could confirm it: even if you reported the bug 1000000 in this forum, it would do no good, and would not cause the code designers – who have not been told of the bug – to do anything.
I will ignore all other unrelated opinions.
I am unable to help you any further, because you ignore what I say or what I say is incomprehensible to you. Maybe someone else will find some other way to helo you. Good luck.