@Pan-Jan
Yes, but that’s not what you said before.
But, you have demonstrated in the past an unclearness about “straight” double quotes and “curled” double quotes, so I suppose you consider \` and \’ to be the same thing.
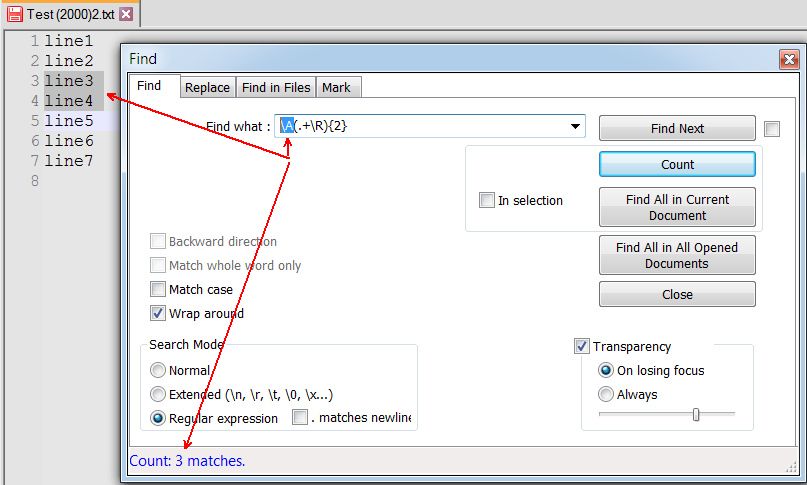
Aside from your inaccuracy about the equivalency for \A (let’s put that behind us), you also said “but it works”, so can you demonstrate to us how you think it works?
I don’t think you can, because your posts don’t make a lot of sense.
I’m sure you will hide behind not being a native English speaker, but others have tried to point out to you that language-translators can make non-English speakers sound truly like English speakers – if one is willing to use them, correctly.