Hello, @johnny27 and All,
Interesting problem ! And easy to solve with, both, regular expressions and the Column Editor ;-))
Here is the road map :
Open your file in Notepad++
Place th caret at the very beginning of the first line
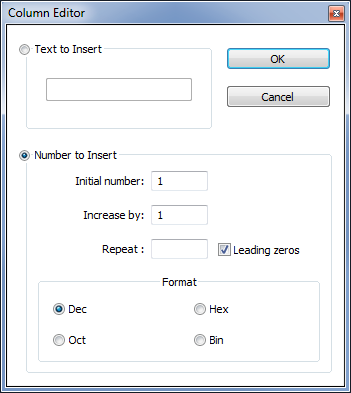
Open the Column Editor ( Alt + C )
Select Number to Insert
Type in 1 in all zones
Tick the Leading zeros option ( IMPORTANT )
Select the Dec format, if necessary
Click on the OK button
=> Each line should be preceded with a 6 digits number !
Now, open the Replace dialog ( Ctrl + H )
SEARCH (?-s)^.[50]0000(.+),|^\d{6}
REPLACE ?1\1;
Tick the Wrap around option
Select the Regular expression search mode
Click on the Replace All button
Voila ! Nice isn’t it ?
Notes :
The search regex contains two alternatives :
First, the (?-s) in-line modifier ensures that any . regex symbol corresponds to a single standard character, only and not to a line-break char !
Then the part ^.[50]0000 searches for any number of six digits, beginning current line and containing a 0 or a 5 at second position, followed with four 0 digits
And the part (.+), looks for theremainder of the lines, minus the , character, which is stored as group 1, due to the parentheses
If current line number is not of the form ^.[50]0000, then it, necessarily, matches the second alternative :
The part ^\d{6} matches the 6 digits number, generated by the Column Editor, which begins any line
The replacement regex contains a conditional replacement (?#....:....) :
If group 1 exists ( every 50,000 lines ), we rewrites the group 1, followed with a semi-colon
If group 1 is absent, as the negative part, after a : does not exist, the first 6 digits number of any line are simply deleted
Best Regards,
guy038